JavaScriptCore 的新字节码格式
在版本 r237547 中,我们为 JavaScriptCore (JSC) 引入了一种新的字节码格式。新格式的目标是改善内存使用情况并允许字节码在磁盘上缓存,而旧格式则以内存使用为代价优化了解释器吞吐量。
在这篇文章中,我们将首先快速概述 JSC 的字节码、旧字节码格式的关键方面及其所实现的优化。接下来,我们将探讨新格式以及它如何影响解释器执行。最后,我们将研究新格式对内存使用和性能的影响,以及这次重写如何提高了 JavaScriptCore 中的类型安全性。
背景
在 JSC 执行任何 JavaScript 代码之前,它必须对其进行词法分析、解析并生成字节码。JSC 有 4 个执行层级:
- 低级解释器 (LLInt):启动解释器
- 基线 JIT:模板 JIT
- DFG JIT:低延迟优化编译器
- FTL JIT:高吞吐量优化编译器
执行从最低层级开始解释字节码,随着代码执行次数的增加,它会被提升到更高层级。这在这篇关于 FTL 的博客文章中有更详细的描述。
字节码是整个引擎的真相来源。LLInt 执行字节码。基线是一个模板 JIT,它为每个字节码指令发出机器代码片段。最后,DFG 和 FTL 解析字节码并发出 DFG IR,然后通过优化编译器运行。
由于字节码是真相来源,它在整个程序执行过程中往往会保留在内存中。在 JavaScript 占用较多的网站(如 Facebook 或 Reddit)中,字节码占总内存使用量的 20%。
字节码
为了使事情更具体,让我们看一个简单的 JavaScript 程序,学习如何检查 JSC 生成的字节码以及如何解释字节码转储。
// double.js
function double(a) {
return a + a;
}
double(2);
如果您使用 jsc -d double.js 运行上述程序,JSC 将把所有生成的字节码转储到 stderr。字节码转储将包含为 double 生成的字节码。
[ 0] enter
[ 1] get_scope loc4
[ 3] mov loc5, loc4
[ 6] check_traps
[ 7] add loc7, arg1, arg1, OperandTypes(126, 126)
[ 13] ret loc7
每行以方括号中的指令偏移量开头,后跟操作码名称及其操作数。在这里我们可以看到用于局部变量的 loc 操作数、用于函数参数的 arg 操作数以及 OperandTypes,它是关于参数预测类型的一些元数据。
旧字节码格式
旧字节码格式存在一些我们想要修复的问题:
- 它占用了太多内存。
- 指令流是可写的,这阻止了字节码流的内存映射。
- 它有一些我们不再受益的优化,例如直接线程。
为了更好地理解我们如何在新的格式中解决这些问题,我们需要对旧字节码格式有一个基本的了解。在旧格式中,指令可以是两种形式之一:未链接的,它紧凑且针对存储进行了优化;和已链接的,它膨胀且针对执行进行了优化,直接在指令流中包含运行时对象的内存地址。
未链接指令
指令使用可变宽度编码。操作码和每个操作数占用尽可能少的空间,范围从 1 到 5 字节。以上述程序中的 add 指令为例,它将占用 6 字节:一个字节用于操作码 (add),每个寄存器(loc7、arg1 和再次的 arg1)各一个字节,以及两个字节用于操作数类型。
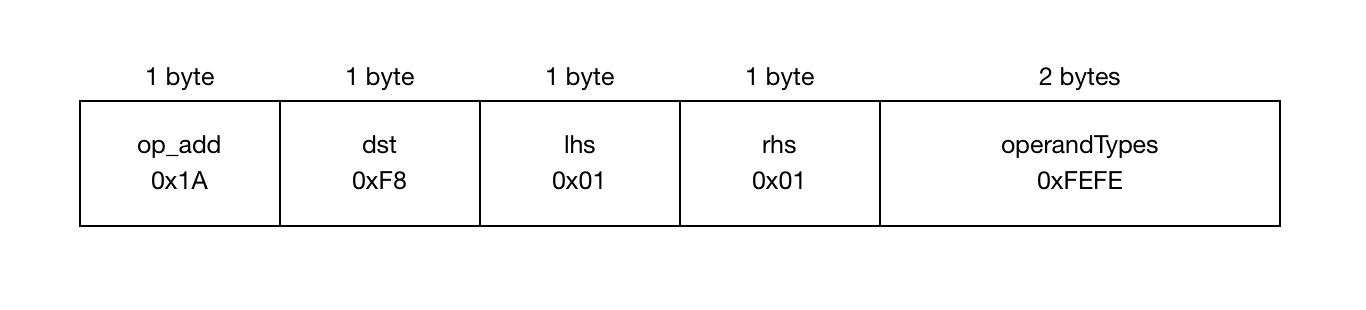
链接 / 已链接指令
在执行字节码之前,需要对其进行链接。链接会膨胀所有指令,使操作码和每个操作数都变为指针大小。操作码被替换为指令实现的实际指针,而与分析相关的元数据则被替换为新分配的分析数据结构的内存地址。上述的 add 需要 40 字节来表示。

执行
字节码由 LLInt 执行,LLInt 使用一种名为 offlineasm 的可移植汇编语言编写。以下是关于 offlineasm 的一些注意事项,它们可能有助于理解接下来的代码片段:
- 临时寄存器是
t0-t5,参数寄存器是a0-a3,返回寄存器是r0和r1。对于浮点数,等效寄存器是ft0-ft5、fa0-fa3和fr。cfp和sp是分别保存调用帧和堆栈指针的特殊寄存器。 - 指令具有以下后缀之一:
b表示字节,h表示 16 位字,i表示 32 位字,q表示 64 位字,p表示指针(32 位或 64 位取决于架构)。 - 宏是 lambda 表达式,接受零个或多个参数并返回代码。宏可以命名或匿名,并且可以作为参数传递给其他宏。
如果您想了解更多关于 offlineasm 的信息,LowLevelInterpreter.asm 是 JSC 中主要的 offlineasm 文件,并在顶部包含了对该语言更深入的解释。
旧字节码格式在解释器吞吐量方面有两个主要优势:直接线程和内联缓存。
直接线程
链接的字节码用指向指令 offlineasm 实现的实际指针代替了操作码,这使得执行下一条指令就像将程序计数器 (PC) 按当前指令的大小前进并进行间接跳转一样简单。这在以下 offlineasm 代码中有所说明:
macro dispatch(instructionSize)
addp instructionSize * PtrSize, PC
jmp [PC]
end
请注意,dispatch 是一个宏,这样代码在每条指令的末尾都会重复。这非常高效,因为它只是一个加法加上一个间接分支。这种重复减少了分支预测污染,因为我们没有所有指令都跳转到一个公共标签并共享相同的间接跳转到下一条指令。
内联缓存
由于指令流是可写的且所有参数都是指针大小的,我们可以在指令流本身中存储元数据。最好的例子是 get_by_id 指令,它在 JavaScript 中从对象加载时发出。
object.field
这会发出一个 get_by_id 指令,用于从 object 加载属性 field。由于这是 JavaScript 中最常见的操作之一,因此其速度至关重要。JSC 使用内联缓存来加速这一过程。在解释器中实现这一功能的方法是,在指令流中保留空间以缓存有关加载的元数据。更具体地说,我们记录了正在加载对象的 StructureID 以及必须加载值的内存偏移量。get_by_id 的 LLInt 实现如下所示:
_llint_op_get_by_id:
// Read operand 2 from the instruction stream as a signed integer,
// i.e. the virtual register of `object`
loadisFromInstruction(2, t0)
// Load `object` from the stack and its structureID
loadConstantOrVariableCell(t0, t3, .opGetByIdSlow)
loadi JSCell::m_structureID[t3], t1
// Read the cached StructureID and verify that it matches the object's
loadisFromInstruction(4, t2)
bineq t2, t1, .opGetByIdSlow
// Read the PropertyOffset of `field` and load the actual value from it
loadisFromInstruction(5, t1)
loadPropertyAtVariableOffset(t1, t3, t0)
// Read the virtual register where the result should be stored and store
// the value to it
loadisFromInstruction(1, t2)
storeq t0, [cfr, t2, 8]
dispatch(constexpr op_get_by_id_length)
.opGetByIdSlow
// Jump to C++ slow path
callSlowPath(_llint_slow_path_get_by_id)
dispatch(constexpr op_get_by_id_length)
新字节码格式
在设计新字节码时,我们有两个主要目标:它应该更紧凑,并且易于在磁盘上缓存。有了这两个目标,我们预期内存使用将得到显著改善,并着手通过缓存来提高运行时性能。这塑造了我们编码指令和运行时元数据的方式。
第一个也是最大的变化是,我们不再有单独的用于执行的链接编码。这立即意味着字节码不能再直接线程化,因为指令的地址无法存储到磁盘,因为它会随着每次程序调用而改变。移除此优化是设计的有意选择。
为了使单一格式既适合存储又适合执行,每条指令都可以编码为窄或宽。
窄指令
在窄指令中,操作码及其操作数各占 1 字节。这是 add 指令的再次出现,这次是新格式中的窄指令:
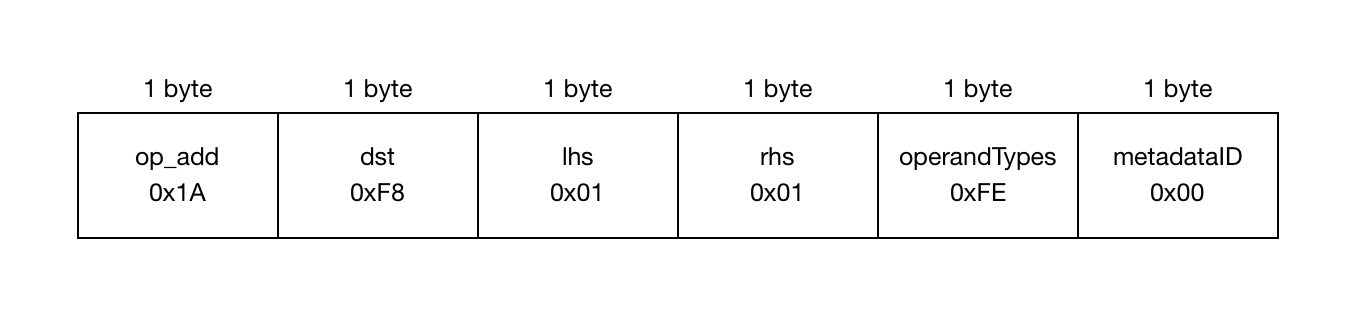
理想情况下,所有指令都应编码为窄型,但并非所有操作数都能放入单个字节中。如果任何操作数(或操作码)需要超过 1 字节,则整个指令都会提升为宽型。
宽指令
宽指令由一个特殊的 1 字节操作码 op_wide 组成,后跟一系列 4 字节的槽位,用于原始操作码及其每个参数。
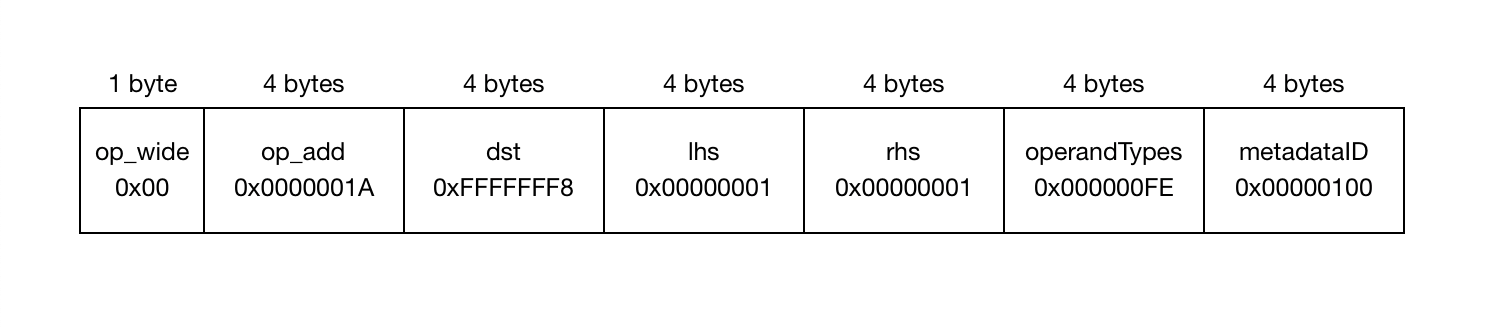
这里需要注意的重要一点是,不可能只有一个宽操作数——如果一个操作数溢出,则整个指令都将变为宽。这是一个重要的折衷,因为尽管乍一看似乎是浪费,但它使实现变得简单得多:无论指令是窄还是宽,任何给定操作数的偏移量都相同。唯一的区别是指令流是按 4 字节值数组还是 1 字节值数组处理。
链接 / 元数据表
新字节码的另一个基本部分是元数据表。在链接过程中,我们不构建新的指令流,而是用与任何给定指令关联的所有可写数据初始化一个副表。从概念上讲,该表是二维的,其第一个索引是指令的操作码,例如 add,它指向该特定指令的元数据条目的单态数组。例如,我们有一个名为 OpAdd::Metadata 的结构体来保存 add 指令的元数据,因此访问 metadataTable[op_add] 将得到一个类型为 OpAdd::Metadata* 的指针。此外,每条指令都有一个特殊操作数 metadataID,它用作元数据表中的第二个索引。
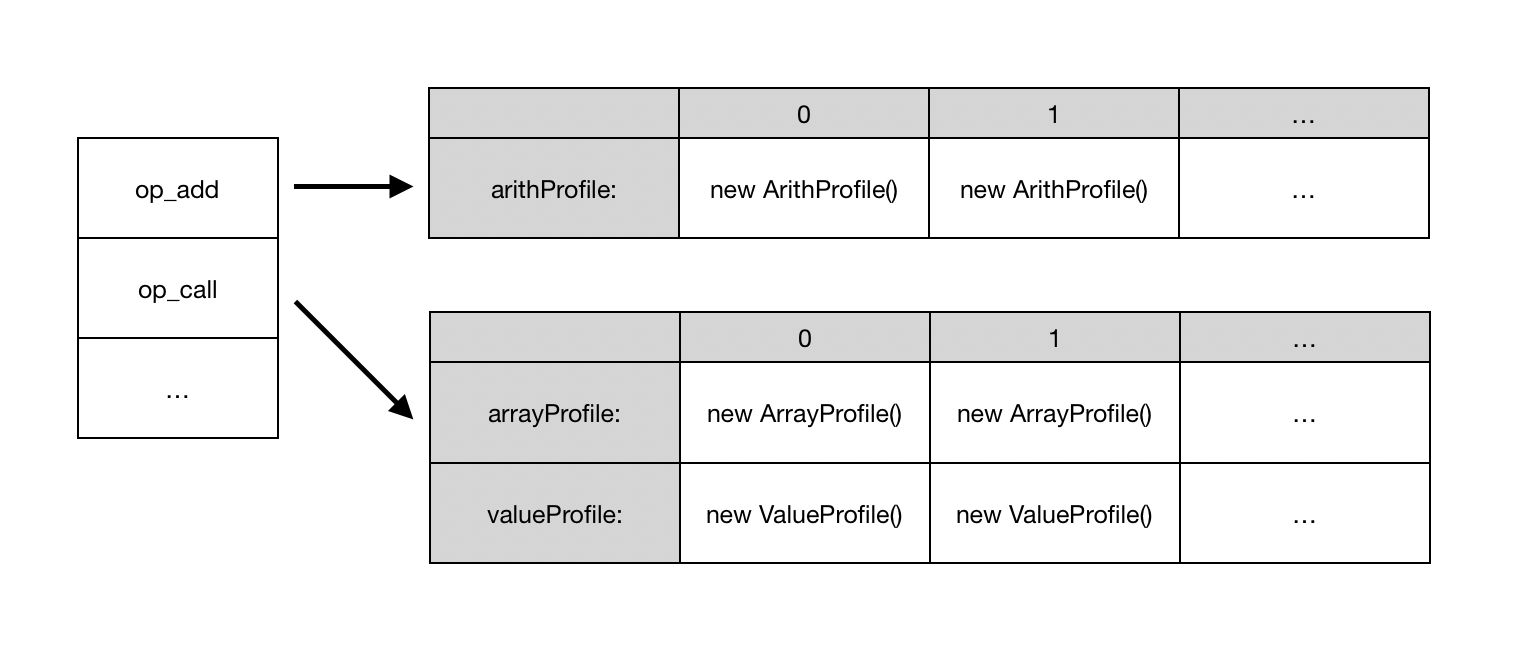
为了紧凑,元数据表在内存中以单个内存块的形式布局。以下是上面表格在内存中实际样子的表示。

表的开头是头部,一个数组,其中包含每个操作码的整数,表示该操作码元数据从表开头开始的偏移量。下一个区域是有效载荷,其中包含每个操作码的实际元数据。
执行
执行的最大变化是解释器现在是间接线程的,并且对于任何可写或运行时元数据,我们都需要从元数据表中读取。另一个有趣的方面是宽指令的执行方式。
间接线程
将操作码映射到指令地址的过程,在旧格式中曾是链接的一部分,现在是解释器调度的一部分。这意味着需要额外的加载,并且调度宏现在看起来像这样:
macro dispatch(instructionSize)
addp instructionSize, PC
loadb [PC], t0
leap _g_opcodeMap, t1
jmp [t1, t0, PtrSize]
end
元数据表
同类“内联缓存”†仍然适用于 get_by_id,但考虑到我们需要在运行时写入元数据,并且指令流现在是只读的,这些数据需要存在于元数据表中。
从元数据表加载有点昂贵,因为 CodeBlock 需要从调用帧加载,元数据表从 CodeBlock 加载,当前操作码的数组从表中加载,最后根据当前指令的 metadataID 从数组中加载元数据条目。
† 我在这里将“内联缓存”加上引号,因为它在技术上已不再是内联的了。
宽指令执行
宽指令的执行出奇地简单:每条指令都有两个函数,一个用于窄版本,另一个用于宽版本。我们利用 offlineasm 从一个实现生成这两个函数。(例如,op_add 的实现将自动生成其宽版本 op_add_wide。)
默认情况下,执行指令的窄版本,直到执行特殊的 op_wide 指令。op_wide 指令所做的只是读取下一个操作码,并分派到其宽版本,例如 op_add_wide。一旦宽操作码执行完毕,它就会回到分派窄指令,因为每个宽指令都需要 1 字节的 op_wide 前缀。
内存使用
新字节码格式的内存使用量大约减少了 50%,这意味着对于 JavaScript 占用较多的网站(如 Facebook 或 Reddit),总体内存使用量减少了 10%。
以下是比较 reddit.com、apple.com、facebook.com 和 gmail.com 字节码大小的图表。
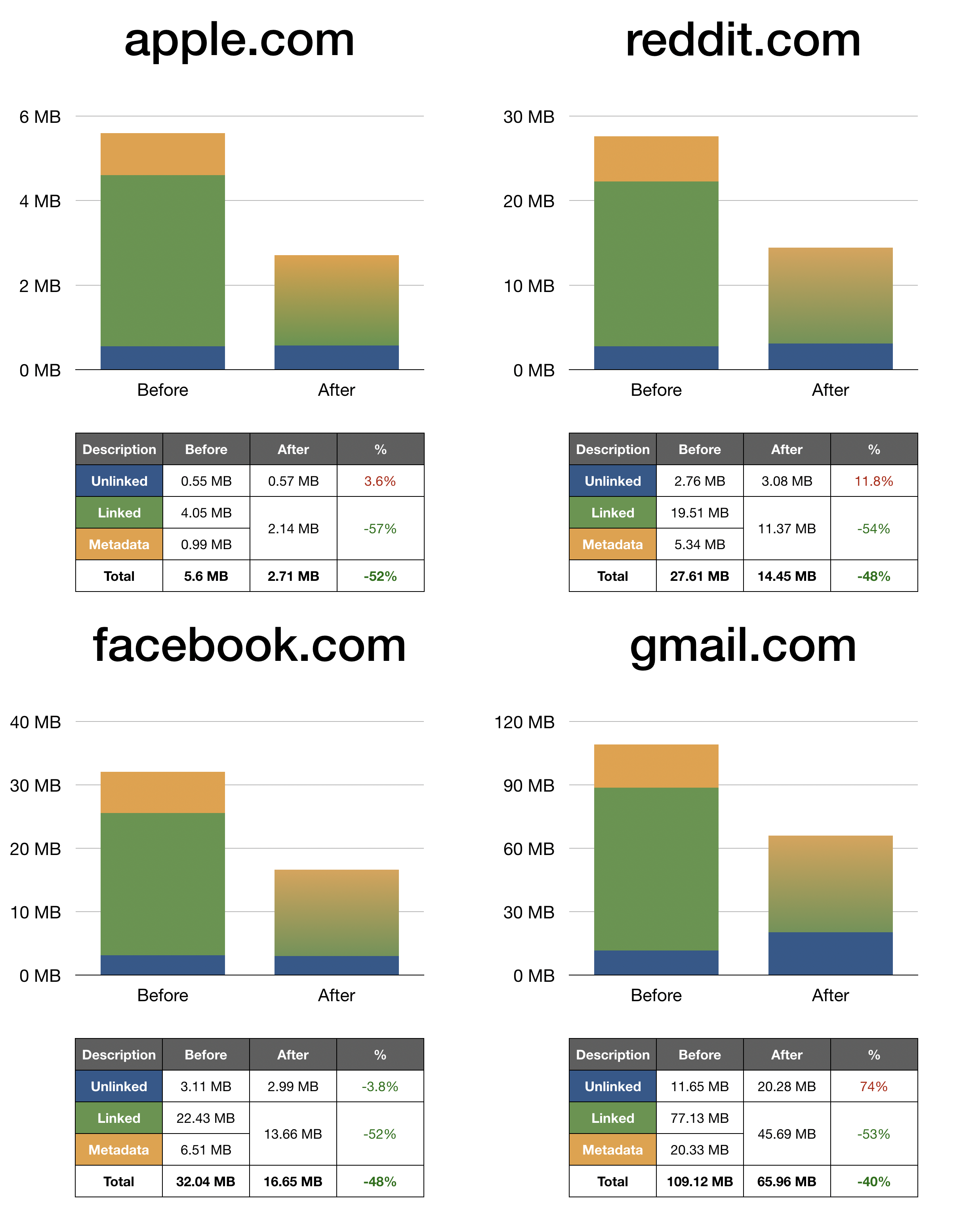
请注意,在“之后”的情况下,元数据已与链接合并,以表示元数据表使用的内存,而未链接则表示实际的字节码指令。原因是新元数据中很大一部分曾经存在于旧的链接字节码中。否则,比较结果会看起来不平衡,因为整个链接条会消失,而元数据似乎会扩大一倍,而实际上它是链接中一部分数据移动到了元数据。
性能
如前所述,间接线程会增加解释器调度的开销。然而,考虑到 JSC 中字节码指令的平均复杂度,我们预计调度开销不会对解释器的整体性能产生有意义的影响。多层 JIT 进一步分摊了这一开销。我们在 CLoop(LLInt 的 C++ 后端)中对纯粹从直接线程切换到间接线程进行了分析,即使禁用了 JIT,结果也是中性的。
从元数据表加载成本较高,涉及大量的加载链。为了减少这个链条,我们在解释器中固定了一个被调用者保存寄存器,以便始终保存指向元数据表的指针。即使有此优化,访问元数据条目仍需要三次加载。这导致了解释器 10% 的减速,但在启用所有 JIT 层级运行时,结果是中性的。
额外:类型安全
改变字节码格式需要在整个引擎中进行更改,因此我们决定借此机会改进与字节码相关的基础设施,提高代码的类型安全性、可读性和可维护性。
为了支持所有这些更改,首先我们需要更改指令的指定方式。最初,指令在一个 JSON 文件中声明,包含它们的名称和长度(操作数数量加一,用于操作码)。这是 add 指令的声明方式:
{ "name": "op_add", "length": 5 }
从 C++ 访问指令及其操作数时,代码大致如下所示:
SLOW_PATH_DECL(slow_path_add)
{
JSValue lhs = OP_C(2).jsValue();
JSValue rhs = OP_C(3).jsValue();
...
}
请注意,操作数是通过其偏移量访问的:OP_C 是一个宏,它会在给定偏移量处访问 Instruction* pc 参数(此处被 SLOW_PATH_DECL 宏隐藏)。然而,指定偏移量处的数据类型是未知的,因此结果必须被强制转换为所需类型。这容易出错,并使代码难以理解。了解指令有哪些操作数(及其类型)的唯一方法是查找其用法并查看变量名和类型转换。
有了新的基础设施,在声明指令时,必须为每个操作数提供名称和类型,并声明将存储在元数据表中的所有数据。
op :add,
args: {
dst: VirtualRegister,
lhs: VirtualRegister,
rhs: VirtualRegister,
operandTypes: OperandTypes,
},
metadata: {
arithProfile: ArithProfile,
}
有了这些额外信息,现在可以为每条指令生成一个完全类型化的 struct,从而得到更安全的 C++ 代码:
SLOW_PATH_DECL(slow_path_add)
{
OpAdd bytecode = pc->as<OpAdd>();
JSValue lhs = GET_C(bytecode.m_lhs);
JSValue rhs = GET_C(bytecode.m_rhs);
...
}
在上面的示例中,我们首先需要将泛型 Instruction* pc 转换为我们想要访问的指令,这将执行一个运行时检查。如果操作码匹配,它将返回生成的结构体 OpAdd 的一个实例,该实例包含字段 m_lhs 和 m_rhs,两者都如我们的指令声明中所指定为 VirtualRegister 类型。
这些额外信息还使我们能够用更安全、自动生成的代码替换大量的机械式代码。例如,我们自动生成所有用于将指令写入指令流的类型安全代码,这些代码会自动进行窄/宽适应。我们还生成所有用于调试时转储指令的代码。
结论
JavaScriptCore 拥有新的字节码格式,平均内存使用量减少了 50%,并已在 Safari 12.1 和 Safari 技术预览版中提供。新字节码的缓存 API 工作已在 WebKit 仓库中进行,欢迎有兴趣的人在 bugs.webkit.org 上关注并贡献!您也可以在 Twitter 上与我联系,提出任何问题或意见。