JSC 新采样分析器介绍
JavaScriptCore (JSC) 有一个新的采样分析器,它为 Web Inspector 的 JavaScript & Events 时间轴提供支持。这个采样分析器取代了 JSC 旧的追踪分析器。它提供了关于程序执行时间消耗的更精确数据,并且比旧的追踪分析器快一个数量级。追踪分析器通过在运行程序中插入检测代码来工作。而采样分析器则通过定期暂停执行程序并收集程序执行状态的数据来工作。现在,当你在 Web Inspector 中记录时间轴时,你会体验到比旧时间轴快30倍的速度提升。这种速度提升源于 JSC 和 Web Inspector 在记录时间轴时所做的两个基础架构改变。主要的速度提升来自用采样分析器取代追踪分析器。进一步的速度提升则来自从执行程序中移除调试检测代码。当 Web Inspector 打开时,JSC 会在执行程序中插入调试检测代码以支持调试器。这种检测代码允许 JSC 检测执行程序中何时命中了断点。然而,在记录时间轴时不需要这些调试检测代码;通过移除它们,JSC 将会快2倍地执行 JavaScript。
分析方法
追踪分析器在进行性能分析时往往不太准确,因为在程序中插入检测代码的高开销改变了程序执行时间消耗的分布。例如,在 JSC 的追踪分析器中,每个调用点在调用前后都会被一个字节码指令装饰,以计时每个调用需要多长时间。不过,追踪分析器对于其他形式的分析很有用。例如,它们可以用来构建一个无损的动态调用图。
采样分析器通过定期采样目标线程并收集其执行状态的有趣数据来运行。通常,收集的数据将是线程暂停时的堆栈跟踪。在 JSC 中,采样分析器无需在运行程序中插入任何检测代码即可工作。这对于保持采样分析器的低开销至关重要。采样分析器收集的数据集总是会丢失一部分信息,因为它以固定间隔采样执行线程。它永远无法重建执行程序的无损调用图。尽管如此,采样分析器在确定程序执行时间消耗方面比追踪分析器更准确。这有两个主要原因。首先,采样分析器开销低,这使得它们能够很好地观察程序的自然状态。其次,如果程序的某个部分是“热点”(即执行频繁),那么采样分析器在该程序的“热点”部分执行时进行采样的可能性很高。换句话说,不采样程序“热点”部分的概率非常低。
采样分析器在程序执行状态的哪个位置进行采样,必须尽可能少地包含偏差。如果在数据采样位置存在偏差,则数据集将无法代表程序的自然执行状态。例如,一些分析器是使用安全点实现的。安全点是程序中执行线程让出执行以允许其他任务运行的特定位置。通常,安全点用于垃圾回收(GC),并提供进入安全点时执行线程状态的严格保证。在 JSC 中实现采样分析器的一种方法是使用基于安全点的机制。JSC 会在每个函数序言和每个循环头部编译一个安全点。正如 Mytkowicz、Diwan、Hauswirth 和 Sweeney 所展示的,基于安全点的分析器不准确。它们给测量数据集引入了太多的偏差。在 JSC 中,基于安全点的实现也会受到偏差的影响。重要的是,它会阻止分析器知道执行代码何时进入 C 运行时。对于某些程序,大部分时间都花在调用 C 运行时的 JavaScript 函数中。有必要将 C 运行时中花费的时间归因于调用它的 JavaScript 帧。对于 JSC 要使用基于安全点的实现,C 运行时需要学习如何与分析器接口。这既容易出错又麻烦。基于安全点的分析器不断地玩着猫捉老鼠的游戏,以最小化偏差。一旦引擎中存在偏差的部分暴露出来,分析器必须通过“教导”引擎的该部分了解分析器来消除该偏差。
JSC 没有使用基于安全点的分析器,正是因为这些缺点。JSC 实现的设计更简单、更简洁,因为JSC没有“教导”引擎的不同部分了解分析器,而是“教导”分析器了解引擎的不同部分。事实证明,这比使用安全点简单得多,因为“教导”分析器了解引擎所需的工作量非常少。JSC 的分析器通过使用一个后台采样线程来工作,该线程以给定频率唤醒,暂停 JSC 执行线程,并进行保守的堆栈跟踪。这种设计也自然而然地产生了一个比使用安全点实现的分析器更准确且开销更低的分析器。
实现 JSC 的采样分析器
JSC 的采样分析器必须进行保守的堆栈跟踪。采样线程事先不知道执行线程在暂停时会处于什么状态(毕竟 JSC 不使用安全点)。执行线程可能处于无法进行堆栈跟踪的状态。如果采样线程遇到这种状态,它将重新休眠,并在下一次采样时再次尝试。这可能会引起担忧。在程序的某些点无法进行堆栈跟踪可能会导致数据集中的偏差,如果程序大部分时间都花在无法进行堆栈跟踪的地方。然而,出现此问题的点是有限的。它们发生在 JSC 生成的机器代码的非常特定的区域。最常见的地方是 JSC 调用约定代码中的某些指令序列。由于 JSC 控制其生成的代码,它能够限制此类偏差的影响。当 JSC 工程师发现此类偏差时,他们可以通过以创建更少和更小的区域(无法进行堆栈跟踪)的方式构造机器代码来尽量减少其影响。
由于采样分析器与虚拟机其他部分清晰分离,其实现相当简单。本节的其余部分将探讨 JSC 采样分析器中更有趣的实现细节。为了探索这些细节,我们首先分析 JSC 采样分析器算法的高级伪代码实现。
void SamplingProfiler::startSampling()
{
VM& vm = getCurrentVM();
MachineThread* jscThread = getJSCExecutionThread();
while (true) {
std::sleep_for(std::chrono::microseconds(1000));
if (vm.isIdle())
continue;
// Note that the sampling thread doesn't control the state in
// which the execution thread pauses. This means it can be holding
// arbitrary locks such as the malloc lock when it gets paused.
// Therefore, the sampling thread can't malloc until the execution
// is resumed or the sampling thread may deadlock.
jscThread->pause();
// Get interesting register values from the paused execution thread.
void* machinePC = thread->PC();
void* machineFramePointer = thread->framePointer();
// JSC designates a machine register to hold the bytecode PC when
// executing interpreter code. This register is only used when the
// sampling thread pauses the top frame inside the interpreter.
void* interpreterPC = thread->interpreterPC();
void* framePointer = machineFramePointer;
if (!isMachinePCInsideJITCode(machinePC)
&& !isMachinePCInsideTheInterpreter(machinePC)) {
// When JSC's JIT code calls back into the C runtime, it will
// store the frame pointer for the current JavaScript upon
// entry into the runtime. This is needed for many reasons.
// Because JSC does this, the sampling profiler can use that frame
// as the top frame in a stack trace.
framePointer = vm.topCallFrame;
}
bool success =
takeConservativeStackTrace(framePointer, machinePC, interpreterPC);
if (!success)
continue;
jscThread->resume();
// The sampling thread can now malloc and do interesting things with
// other locks again.
completeStackTrace();
}
}
实际的实现只比上面的伪代码稍微复杂一点。因为采样线程不控制 JSC 执行线程暂停时的状态,所以采样线程不能假设执行线程持有任何锁。这意味着如果采样线程希望保证执行线程在暂停之前不持有特定锁,采样线程必须在暂停执行线程之前获取该锁。然而,还有其他锁是采样线程不希望获取的,并且它确保在执行线程暂停时不会传递性地获取这些锁。这类中最有趣的锁是 malloc 锁。采样线程进行的保守堆栈跟踪不能分配任何内存。如果采样线程分配内存,如果执行线程在暂停时持有 malloc 锁,则会发生死锁。为了防止分配任何内存,采样线程预分配了一个缓冲区,用于保守堆栈跟踪放置其数据。如果缓冲区空间不足,它将提前结束堆栈跟踪,并在恢复执行线程后扩大其缓冲区。
当执行线程暂停时,采样分析器必须知道机器的程序计数器(PC)在哪里。采样线程关注四种状态。第一种状态是VM空闲时;遇到这种状态时,采样线程只是回去休眠。最后三种状态是基于VM非空闲时机器的PC。PC可以在JIT代码内部,解释器代码内部,或者两者都不是。采样线程将最后一种状态理解为PC在C运行时内部。采样线程能够轻松确定执行线程何时在C运行时内部,并将该时间归因于调用C运行时的JavaScript帧。采样线程可以通过读取VM类的一个字段来做到这一点,该字段保存了调用C运行时的JavaScript帧的帧指针。这使得JSC的采样分析器实现避免了假设的基于安全点的实现的最大缺点之一。采样线程必须区分解释器和JIT代码的原因是,解释器使用虚拟PC来保存当前正在执行的字节码指令。采样线程使用解释器的虚拟PC来确定程序在函数中的执行位置。机器PC在解释器内部不包含足够的信息来做到这一点。当机器PC在JIT代码内部时,JSC使用一个从PC到JSC称之为CodeOrigin的映射。CodeOrigin用于确定程序当前正在执行的操作的行号和列号。
采样时让JSC快速运行
使用追踪分析器时,Web Inspector 即使在记录时间线时也总是会启用 JSC 的调试器。启用调试器会阻止许多有趣的编译器优化发生。例如,JSC 会禁用内联。JSC 还会将所有变量标记为闭包变量。这迫使一些原本应该存在于栈上的变量存在于堆分配的闭包对象中,使得对该变量的所有使用都是从堆中读取,对该变量的所有写入都是写入堆中。此外,所有函数都必须至少为闭包对象执行一次对象分配。由于调试器极大地改变了程序的执行状态,它使执行程序偏离了其自然状态。此外,追踪分析器并未在 JSC 的 FTL JIT 中实现。由于这些缺点,用追踪分析器记录的数据充其量是扭曲的,最坏的情况下是完全错误的。
为了防止采样分析器出现同样的偏差,Web Inspector 在开始时间线记录之前会禁用 JSC 的调试器。为了让时间线记录反映程序的自然执行状态,JSC 不能采样一个用调试检测代码编译的程序。与追踪分析器不同,采样分析器不限制函数可以在哪些编译器层级执行。采样分析器可以进行堆栈跟踪,堆栈中的任何帧都可以在任何层级下编译。通过消除这些缺点,当在 Web Inspector 中使用采样分析器记录时间线时,JSC 既能获得出色的性能,又能收集到更能代表程序自然执行状态的数据。
为了了解采样分析器比追踪分析器准确多少,让我们检查一个程序,在该程序中,追踪分析器的数据集表明大量时间花在某个特定函数中,而该程序在自然状态下在该函数中花费的时间很少。
var shouldComputeSin = false;
var shouldComputeCos = true;
function computeSin(obj, x) {
if (shouldComputeSin)
obj.sin = Math.sin(x);
}
function computeCos(obj, x) {
if (shouldComputeCos)
obj.cos = Math.cos(x);
}
function computeResults(x) {
var results = {};
computeSin(results, x);
computeCos(results, x);
}
function run() {
for (var i = 0; i < 1000000; i++) {
computeResults(i);
}
}
run();
当在自然状态下在 JSC 中运行示例程序时,JSC 将执行以下重要优化,这将消除程序的大部分开销:
- 对
computeSin和computeCos的调用将被内联到computeResults中。 shouldComputeSin和shouldComputeCos上的分支将被常量折叠,因为 JSC 将意识到这些变量是全局的,并且在程序的执行过程中一直是常量。- 当
computeResults提升到 FTL 级别时,FTL 将执行对象分配下沉,这将阻止computeResults为results对象执行分配。FTL 可以做到这一点,因为它在内联computeSin和computeCos之后,证明results仅在本地使用且不会逃逸。分配下沉随后会将results的字段转换为局部变量。
当在 Safari 技术预览版的 Web Inspector 中记录时间轴时,这个示例程序运行得超级快;在我的机器上大约只需 10 毫秒。采样分析器显示了时间花费的以下分布:

时间仅花在 computeResults 和 computeCos 内部;computeSin 中没有花费时间。这是有道理的,因为一旦 computeResults 提升到优化 JIT,JSC 将执行优化,使 computeSin 变成一个空操作。
当在 Safari 9 中记录同一程序的时间线时,结果完全不同

追踪分析器测量该程序运行时间约为 1.85 秒。这比 Safari 技术预览版中采样分析器测量到的慢了 185 倍。此外,当查看追踪分析器的调用树时,数据显示大量时间花在 computeSin 中。这完全是错误的。当程序以其自然的、未观察到的状态运行时,实际上没有时间花在 computeSin 中。对于像上面示例这样的程序,分析器报告准确信息至关重要。当分析工具报告误导性数据时,会导致工具的用户花费时间优化错误的地方。如果用户信任此示例中追踪分析器的数据,可能会导致他们从 computeResults 中删除函数调用,并手动将 computeSin 和 computeCos 内联到 computeResults 中。然而,采样分析器表明这是不必要的,因为 JSC 将在 DFG 和 FTL JIT 中自行执行此优化。
为了比较两种分析器在更实际的工作负载上的性能,让我们检查它们在 Octane 基准测试中的表现。
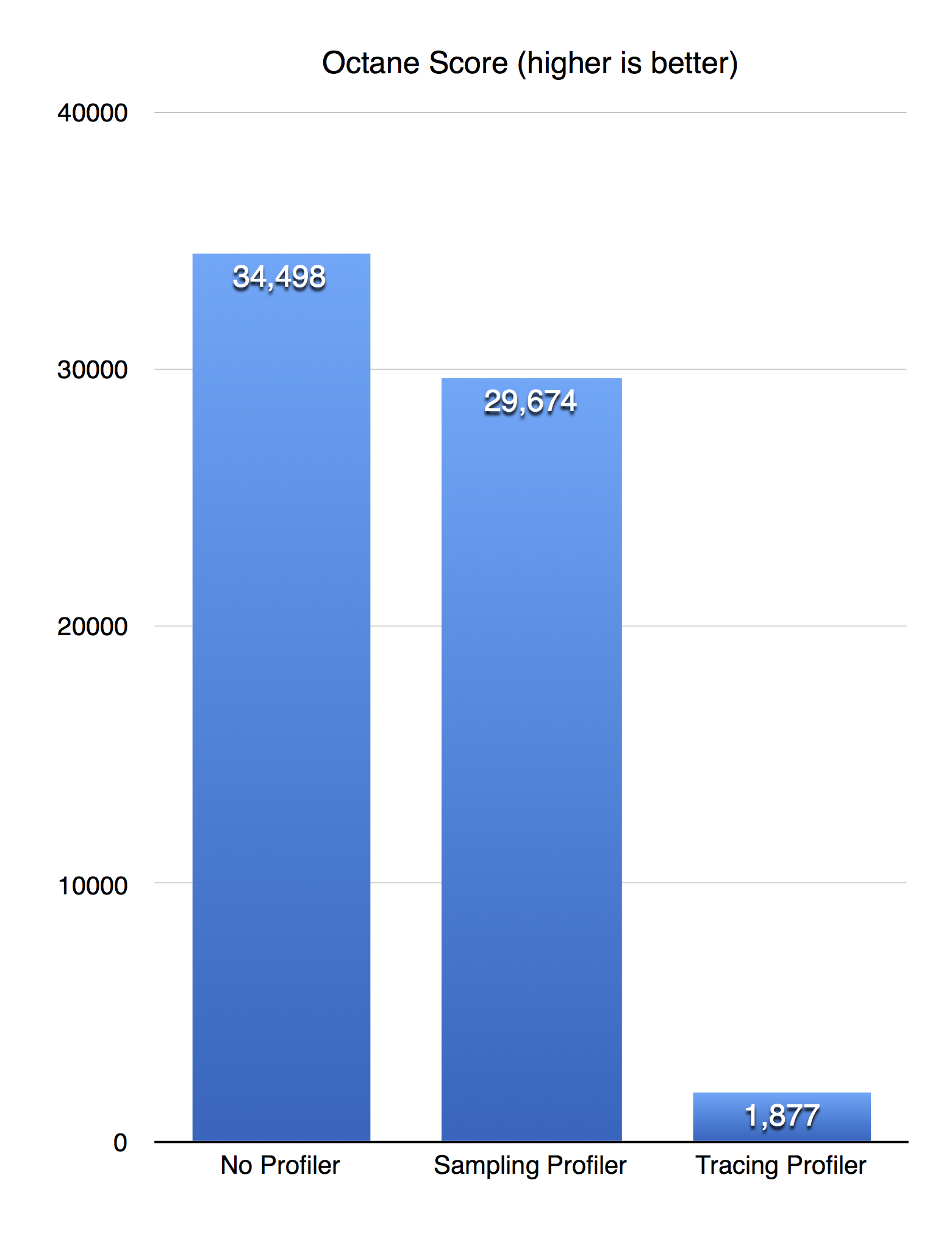
为了收集这些数据,我希望在浏览器中运行 Octane,包括 Safari 技术预览版和 Safari 9,同时在 Web Inspector 中记录时间线。不幸的是,Safari 9 在运行 Octane 时记录时间线会崩溃。因此,采样分析器不仅速度快得多,而且也更可靠。为了让 Octane 运行不崩溃,我使用了 jsc 命令行实用程序,并使用了必要的 jsc 命令行选项来模拟在 Safari 技术预览版中使用采样分析器记录时间线和在 Safari 9 中使用追踪分析器记录时间线的情况。这些结果清楚地表明,Web Inspector 和 JSC 在新的分析架构下比旧的追踪分析架构快了一个数量级。
Web Inspector 集成
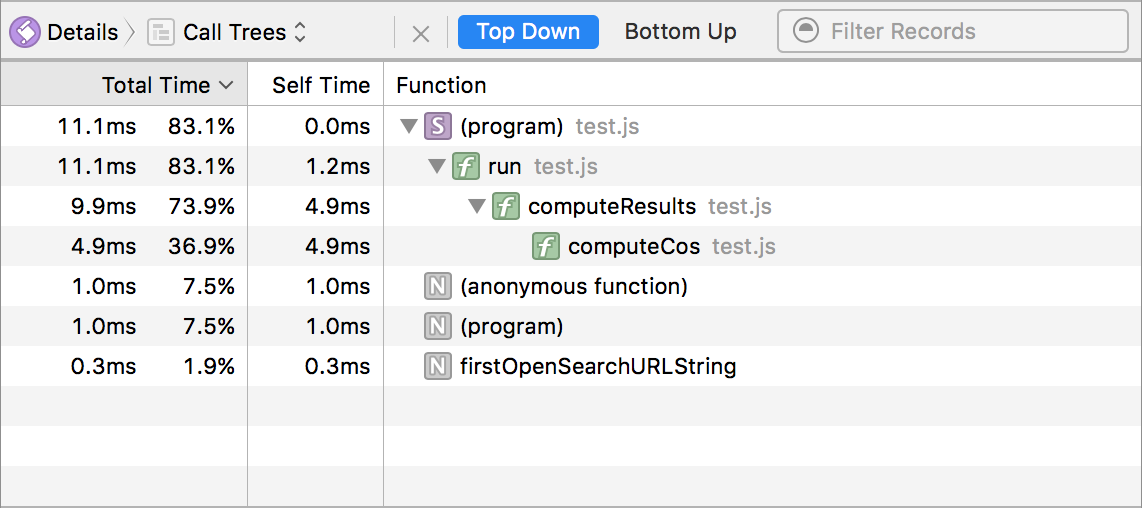
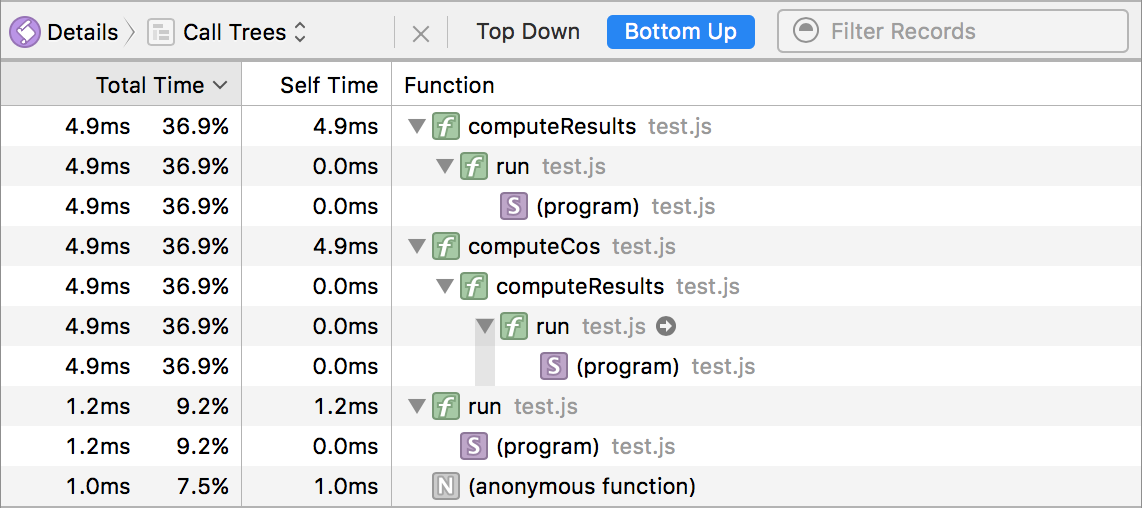
为了配合新的采样分析器,Web Inspector 在 JavaScript & Events 时间轴中引入了新的 Call Trees 视图。此视图允许用户查看关于整个程序或手动选择的时间范围的紧凑调用树数据。调用树可以以自顶向下或自底向上(这是我最喜欢的性能分析视图)的方式查看。以下两张图片展示了上述 JavaScript 示例程序的新 Call Trees 视图。
总结
JSC 和 Web Inspector 进行了许多更改,以使新的采样分析器既快速又准确。新分析器的准确性是移除执行程序中所有检测代码的结果。JSC 转向使用采样分析器而不是追踪分析器,因为采样分析器不需要将检测代码编译到执行程序中。采样分析器在进行性能分析时也更准确,因为它们比追踪分析器对测量数据集引入的偏差更少。此外,Web Inspector 现在在记录时间轴时禁用调试器,以防止调试检测代码被编译到 JavaScript 程序中。总而言之,这些更改使新的 JavaScript & Events 时间轴成为进行性能分析工作的绝佳体验,使 JavaScript 运行速度比以前快 30 倍。如果您对 JSC 的新采样分析器有任何意见或疑问,请通过 Twitter 联系我或 Jon Davis。