WebKit 中的锁
回到 2015 年 8 月,我们用新的 WTF::Lock(WTF 代表 Web Template Framework)替换了 WebKit 中的所有自旋锁和操作系统提供的互斥锁。我们还用WTF::Condition替换了所有操作系统提供的条件变量。这些新原语具有一些很酷的特性
WTF::Lock和WTF::Condition每个只需要一字节的存储空间。WTF::Lock在该字节中只需要两位。小尺寸鼓励使用大量非常细粒度的锁。操作系统互斥锁通常需要 64 字节或更多。WTF::Lock的小尺寸意味着,任何需要同步的对象中,几乎没有理由不使用一个或多个细粒度锁。WTF::Lock在最重要的场景下速度极快:无竞争的锁获取。并行算法倾向于通过拥有许多细粒度锁来避免竞争。这意味着一个成熟的并行算法将有许多无竞争的锁获取——即在锁未被持有时调用lock(),以及在没有线程排队等待时调用unlock()。类似地,WTF::Condition优化了在没有线程等待时调用notify的常见情况。WTF::Lock在微竞争下速度很快。微竞争锁是指存在竞争且临界区很短的锁。这意味着在任何失败的锁尝试之后不久,锁将再次可用,因为没有线程会长时间持有锁。这是并行代码中最常见的竞争类型,因为在持有锁的同时进行少量工作是很常见的。- 当锁被长时间持有时,
WTF::Lock不会浪费 CPU 周期。WTF::Lock是自适应的:它根据尝试等待锁可用的时间长度来改变其策略。如果锁未能及时可用,WTF::Lock将挂起调用线程,直到锁变得可用。
与 pthread_mutex 等操作系统提供的锁相比,WTF::Lock 小 64 倍,快达 180 倍。与 pthread_cond 等操作系统提供的条件变量相比,WTF::Condition 小 64 倍。使用 WTF::Lock 而不是 pthread_mutex 意味着 WebKit 在 JetStream 上快 10%,在 Speedometer 上快 5%,在我们的页面加载测试中快 5%。
让 WTF::Lock 和 WTF::Condition 占用一字节并不容易,其背后的技术具有多层。Lock 和 Condition 将所有线程排队和挂起功能卸载到 WTF::ParkingLot,后者通过锁的地址管理线程队列。ParkingLot 的设计灵感来自 futex。ParkingLot 是核心 futex API 的可移植用户级实现。ParkingLot 也需要快速锁,所以我们为其构建了自己的锁,名为 WTF::WordLock。
这篇文章首先描述了一些关于锁的背景知识。然后我们描述 ParkingLot 抽象以及我们如何用它来构建 WTF::Lock 和 WTF::Condition。本节还展示了一些基于 ParkingLot 的替代锁定算法。接着我们描述 ParkingLot 和 WordLock 的实现方式,希望细节足够丰富以便进行有意义的审查。文章最后提供了一些性能数据,包括与一系列锁算法的比较。
背景
本节描述了一些关于锁的背景知识。这包括我们用来实现锁的原子操作,以及一些经典算法,如自旋锁和自适应锁。本节还尝试适当地提及其他锁实现。
原子操作
CPU 和编程语言很少提供关于内存访问在并发执行时相互作用方式的保证,因为期望程序员通过用锁保护来防止对同一内存的并发访问。但是,如果你像我一样喜欢实现自己的锁,你就会想要一些具有强大保证的低级原语。
C++ 为此提供了 std::atomic。你可以用它来包装一个基本类型(如 char、int 或指针类型),并提供一些原子性保证。只要你坚持最强的内存排序(seq_cst),你就可以确信 std::atomic 操作的并发执行将表现得如同它们是顺序执行的。这使得即使在并发运行时,通过设想其各种原子操作可能交错的所有方式,也可以判断算法是否可靠。
在 WebKit 中,我们使用自己的包装器,名为 WTF::Atomic。它是 std::atomic 提供功能的精简版本。我们将只考虑它的三个原子方法:T load()、store(T) 和 bool compareExchangeWeak(T expected, T desired)。
加载和存储是自解释的。有趣的是 compareExchangeWeak,它实现了原子 CAS(比较并交换)操作。这是一种 CPU 原语,可以看作是原子性地运行以下伪代码
bool CAS(T* pointer, T expected, T desired)
{
if (*pointer != expected)
return false;
*pointer = desired;
return true;
}
这个方法是根据 std::atomic::compare_exchange_weak 实现的,而 std::atomic::compare_exchange_weak 又是根据 x86 上的 lock; cmpxchg 指令或 ARM 上的 ldrex 和 strex 实现的。这种形式的 CAS 被称为弱,因为我们允许它虚假地什么都不做并返回 false。相反则不然——如果 CAS 返回 true,那么在其原子执行期间,它必定看到 *pointer 等于 expected,然后将其更改为 desired。
自旋锁
有了 WTF::Atomic,我们可以实现最简单的锁,称为自旋锁。它看起来像这样
class Spinlock {
public:
Spinlock()
{
m_isLocked.store(false);
}
void lock()
{
while (!m_isLocked.compareExchangeWeak(false, true)) { }
}
void unlock()
{
m_isLocked.store(false);
}
private:
Atomic<bool> m_isLocked;
};
这之所以有效,是因为 lock() 成功的唯一方式是 compareExchangeWeak 返回 true。如果它返回 true,那么一定是这个线程观察到 m_isLocked 为 false,然后在任何其他线程也看到它为 false 之前,立即将其翻转为 true。因此,没有其他线程可能持有锁。要么根本没有其他线程调用 lock(),要么它们对 lock() 的调用仍然在 while 循环中,因为 compareExchangeWeak 持续返回 false。
自适应锁
自适应锁只会自旋一小段时间,然后挂起当前线程,直到其他线程调用 unlock()。这保证了如果一个线程必须长时间等待一个锁,它会悄悄地等待。这是节省 CPU 时间和电力的一个理想保证。
相比之下,自旋锁只能通过自旋来处理竞争。最简单的自旋锁会使竞争线程看起来非常繁忙,因此操作系统会确保调度它们。这将浪费大量电力,并使其他可能真正能做有用工作的线程饿死。一个简单的解决方案是让自旋锁在 CAS 尝试之间休眠——可能休眠一毫秒。这在实际代码中会损害性能,因为它会在锁在休眠间隔期间可用时推迟进度。此外,休眠并不能完全解决自旋时的效率问题。WebKit 有些锁可能会被长时间持有。例如,用于控制编译器线程和垃圾收集器之间交错的锁通常是无竞争的,但有时可能会被持有并发生竞争,持续整个 JS 堆收集时间或编译某个函数所需的时间。在最极端的情况下,锁可能会保护阻塞 IO。这可能会意外发生,例如,一个看似无害的加载操作中的页面错误导致交换。有些临界区可能需要一段时间,我们不希望竞争线程在此期间进行轮询,即使频率只有 1KHz。
没有好办法让自旋变得高效。如果我们增加 CAS 尝试之间的延迟,那么我们只是增加了锁被解锁与竞争线程获取锁之间的时间。如果我们减少延迟,锁的效率会降低。我们希望有一种锁定算法,它能确保如果自旋不能快速地让我们获得锁,我们的线程会安静地等待,直到锁被释放的那一刻。这就是自适应锁试图做到的。
我们将实现的自适应锁可以分为两种独立的数据结构
- 内存中一个小的原子字段,它总结了锁的状态。它可以回答诸如“是否有人持有锁?”和“是否有人正在等待获取锁?”这样的问题。我们将称之为原子状态。
- 一个等待获取锁的线程队列,以及一个用于挂起和恢复这些线程的机制。队列必须有自己的同步原语,并且某种方式与原子状态保持同步。我们说“parking”(挂起)是指将线程入队并挂起它。我们说“unparking”(唤醒)是指将线程出队并恢复它。
WTF::Lock 是 WebKit 对自适应锁的实现,针对我们最关心的事情进行了优化:低空间使用率和无竞争锁获取的极佳快速路径。锁对象只包含原子状态,而队列在 ParkingLot 内部按需创建。这使得我们的锁只需要两位。像其他自适应锁一样,WTF::Lock 保证如果一个线程需要长时间等待一个锁,它会悄悄地等待。
相关工作
如果你知道你需要一个自适应锁,你可以确信现代操作系统的互斥锁实现将安全地适应竞争并避免自旋。不幸的是,大多数操作系统互斥锁会比自旋锁更慢、更大,因为兼容性(pthread_mutex_t 为 64 字节是为了与针对旧的、必须为 64 字节的实现编译的程序保持二进制兼容性)或需要支持你可能不需要的功能(如递归锁定——即使你不使用它,pthread_mutex_lock() 也可能至少需要检查你是否请求了它)而产生的人为限制。
WebKit 的锁定基础设施最受 Linux 卓越的 futex 原语的启发。Futex 使得开发者只需几行代码即可编写自己的自适应锁(Franke, Russell, and Kirkwood ’02)。与 futex 类似,我们只在锁遇到竞争时才实例化大部分锁数据,并通过哈希锁的地址来定位这些数据。与 futex 不同,我们的实现不依赖于内核支持,因此它可以在任何操作系统上运行。ParkingLot API 具有一些 futex 所缺乏的功能,例如在持有内部 ParkingLot 锁时调用回调。
每个自适应锁使用非常少比特的理念非常普遍,尤其是在 Java 虚拟机中。例如,HotSpot 通常只需要两到三位来表示对象锁的状态。我曾与他人合著了一篇关于另一个 Java VM 中锁定的论文,其中也将自适应锁压缩成少量比特。我们可以将构建小巧快速锁的一些想法追溯到元锁(Agesen 等人 ’99)和tasuki 锁(Onodera 和 Kawachiya ’99)。
诸如 std::synchronic 和 硬件事务内存 等新提案也旨在加速锁定。我们将展示这些技术不具备我们为 WebKit 所需的性能特质。
尽管这些基本技术在某些社区中已广为人知,但很难找到一个具备我们所需特性的 C++ 锁实现。自旋锁随处可见,它们通常被优化以使用少量内存,并在无竞争锁获取和微竞争方面具有极佳的快速路径。但当锁不能立即可用时,自旋锁会浪费 CPU 时间。操作系统互斥锁知道如何在锁不可用时挂起线程,因此它们在竞争下更有效率——但它们通常具有较慢的无竞争快速路径,在微竞争下不一定具有我们想要的行为,并且它们需要更多内存。C++ 通过 std::mutex 提供对操作系统互斥锁的访问。在 WTF::Lock 之前,WebKit 混合使用了自旋锁和操作系统互斥锁,我们试图根据对它们是更受益于无竞争速度还是竞争下效率的猜测来选择使用哪一种。如果我们需要这两种特性,我们将别无选择,只能放弃其中一种。例如,我们在 CodeBlock 中有一个自旋锁,它本应是自适应的,因为它保护着长的临界区;我们并行 GC 中有一个操作系统互斥锁,由于快速路径性能的不足,它在 Octane Splay 基准测试中占用了我们 3% 的时间。这些问题都通过 WTF::Lock 得到了解决。此外,没有办法同时拥有一个小型锁(1 字节或更小)并且在竞争下高效,因为操作系统互斥锁往往很大。在最极端的情况下,每个 JavaScript 对象都会有一个锁,因此我们关心锁的大小。
使用 ParkingLot 构建锁
WTF::ParkingLot 是一个用于构建自适应锁和其他同步原语的框架。WTF::Lock 和 WTF::Condition 都用它来挂起线程,直到锁可用或条件被通知。ParkingLot 还为我们提供了实现 Web 标准中即将出现的同步方案(如 SharedArrayBuffer)所需的一切。
自适应锁需要能够挂起和恢复线程。我们认为同步原语不应该维护自己的挂起队列,而应该由一个单一的全局数据结构提供一种通过使用锁的原子状态地址作为键来访问队列的方式。队列的并发哈希表称为 WTF::ParkingLot。由于每个线程在任何给定时间只能排队一次,ParkingLot 的内存使用量受线程数量的限制。这意味着锁不必为队列空间付出代价。这很有道理,因为 WebKit 通常运行少量线程(在我的系统上大约十个),但可以轻松分配数百万个锁(在最坏的情况下,每个 JavaScript 对象一个)。
ParkingLot 负责排队和线程挂起,这样锁算法就可以专注于其他事情,例如自旋多长时间、在自旋中引入何种延迟以及解锁时优先考虑哪些线程。
ParkingLot API
“Parking”(挂起)是指在挂起线程的同时,将其排入以某个地址为键的队列中。“Unparking”(唤醒)是指从以某个地址为键的队列中取出线程并恢复它。这种 API 必须有一个机制来解决挂起-恢复竞争,即如果恢复操作发生在挂起之前,线程仍然会挂起。ParkingLot 通过公开队列受锁保护的事实来解决这个问题。Parking 在持有队列锁时调用客户端回调,并让客户端有机会决定是否继续。Unparking 在持有队列锁时调用客户端回调,并告知客户端是否有线程被取出以及队列中是否还有其他线程。客户端可以依赖这种额外的同步来确保不会发生竞争性死锁。
ParkingLot 的基本 API 包括 parkConditionally、unparkOne 和 unparkAll。
bool parkConditionally(address, validation, beforeSleep, timeout)。它接收 const void* address 作为键,用于查找并锁定该地址的队列。在持有锁时调用 bool validation() 回调(通常是 C++ lambda 表达式)。如果验证返回 false,则队列被解锁,parkConditionally() 返回 false。
如果验证返回 true,当前线程会被放入队列,并且队列锁会被释放。队列锁释放后,会调用 void beforeSleep() 回调。这对于某些同步原语来说很有用,但大多数锁会传递一个空的 thunk(空函数)。此时,线程会被挂起,直到某个 unparkOne() 调用将此线程从队列中取出并恢复它。客户端可以使用 ParkingLot::Clock::time_point 提供超时(ParkingLot::Clock 是 std::chrono::steady_clock 的类型别名)。线程不会在该时间点之后保持挂起。
void unparkOne(address, callback)。它接收一个 const void* address,并将其用作键来查找并锁定该地址的队列。接着,unparkOne 尝试从队列中取出一个线程。一旦成功,它会调用 void callback(UnparkResult),传入一个结构体,该结构体报告是否有线程被取出以及队列当前是否为空。之后,它会解锁队列锁。如果它已经取出了一个线程,它现在会发出信号唤醒该线程。
void unparkAll(address)。唤醒与给定地址关联的队列上的所有线程。
这个 API 提供了实现所需锁定原语所需的一切:WTF::Lock 和 WTF::Condition。它还允许我们构建用户态版本的 FUTEX_WAIT/FUTEX_WAKE 操作,这些操作是 SharedArrayBuffer 原子操作所必需的。
WTF::Lock
我们有许多锁,包括在诸如 JavaScriptCore 的 Structure 这样频繁分配的对象内部的锁。我们希望锁对象尽可能少地占用内存,因此我们尽力使锁适应一个字节。我们在 Structure 中做了许多类似的技巧,因为有很大的压力要使该对象尽可能小。我们还希望核心算法能够支持将锁嵌入到位域的可能性,尽管 Lock 不支持这一点,因为 C++ 要求对象至少为一个字节。正如本节将展示的,ParkingLot 使实现快速锁定算法变得如此简单,以至于如果客户端确实需要将锁嵌入到位域中,他们完全可以合理地拥有自己的该算法实现。
我们的目标是拥有一种满足以下要求的锁:
- 使用尽可能少的位数。
- 在加锁和解锁的快速路径上仅需要 CAS 操作,以最大化无竞争下的吞吐量。
- 具有自适应性。
- 在竞争条件下最大化吞吐量。
使快速路径只要求 CAS 意味着 WTF::Lock 的原子状态必须能够告诉我们是否有任何线程被停泊(parked)。否则,unlock() 函数将不得不总是调用 ParkingLot::unparkOne(),以防有线程被停泊。虽然这样的实现能够正常工作,但远非最优。毕竟,ParkingLot::unparkOne() 必须进行哈希、获取某个队列锁并调用回调。这比我们在 unlock() 的常见路径中希望的要多得多。
这意味着原子状态需要两位:
isLockedBit用于指示锁是否已锁定。hasParkedBit用于指示可能存在停泊线程。
即使 hasParkedBit 已设置,只要 isLockedBit 清除,就可以进行加锁。此属性称为抢占(barging)。我们稍后将深入探讨抢占的影响。
如果加锁不成功,算法会在重试和停泊线程之间做出选择。在停泊之前,它会设置 hasParkedBit。传递给 parkConditionally 的 validation 回调会检查锁是否仍同时设置了 isLockedBit 和 hasParkedBit。如果 isLockedBit 清除,我们不想停泊,因为这意味着锁是可用的。如果 hasParkedBit 清除,我们不想停泊,因为这意味着锁已经忘记了我们即将停泊。
如果 hasParkedBit 清除,则解锁操作只需清除 isLockedBit。如果 hasParkedBit 已设置,它会调用 unparkOne(),并传入一个真正解锁的锁的回调。这个回调会将锁的状态设置为 hasParkedBit 或 0,具体取决于 UnparkResult 是否报告队列中仍有更多线程。
我们将这种基本算法称为抢占锁,一个基本实现可能如下所示:
class BargingLock {
public:
BargingLock()
{
m_state.store(0);
}
void lock()
{
for (;;) {
uint8_t currentState = m_state.load();
// Fast path, which enables barging since we are happy to grab the
// lock even if there are threads parked.
if (!(currentState & isLockedBit)
&& m_state.compareExchangeWeak(currentState,
currentState | isLockedBit))
return;
// Before we park we should make sure that the hasParkedBit is
// set. Note that because compareAndPark will anyway check if the
// state is still isLockedBit | hasParkedBit, we don't have to
// worry too much about this CAS possibly failing spuriously.
m_state.compareExchangeWeak(isLockedBit,
isLockedBit | hasParkedBit);
// Try to park so long as the lock's state is that both
// isLockedBit and hasParkedBit are set.
ParkingLot::parkConditionally(
&m_state,
[this] () -> bool {
return m_state.load() == isLockedBit | hasParkedBit;
});
}
}
void unlock()
{
// We can unlock the fast way if the hasParkedBit was not set.
if (m_state.compareExchangeWeak(isLockedBit, 0))
return;
// Fast unlocking failed, so unpark a thread.
ParkingLot::unparkOne(
&m_state,
[this] (ParkingLot::UnparkResult result) {
// This runs with the queue lock held. If mayHaveMoreThreads
// is true, we unlock while leaving the hasParkedBit set.
if (result.mayHaveMoreThreads)
m_state.store(hasParkedBit);
else
m_state.store(0);
});
}
private:
static const uint8_t isLockedBit = 1;
static const uint8_t hasParkedBit = 2;
Atomic<uint8_t> m_state;
};
WTF::Lock 严格遵循此算法,但具有额外的性能优化,例如自旋(spinning)和内联快速路径。
自旋
自适应锁结合了停泊和自旋。自旋很好,因为它能保护微竞争场景免于进行停泊操作。微竞争是指线程在快速路径上获取锁失败,因为锁当前不可用,但该锁会在比停泊然后唤醒所需时间更短的时间内变得可用。在 WTF::Lock::lock() 停泊一个线程之前,它会自旋 40 次,每次自旋之间调用 yield。这在各种平台上都足够好。该算法可以如下可视化:
// Fast path:
if (m_word.compareExchangeWeak(0, isLockedBit))
return;
// Spin 40 times:
for (unsigned i = 40; i--;) {
// Do not spin if there is a queue.
if (m_word.load() & hasParkedBit)
break;
// Try to get the lock.
if (m_word.compareExchangeWeak(0, isLockedBit))
return;
// Hint that now would be a good time to context switch.
sched_yield();
}
// Now do all of the queuing and parking.
// ...
这是一种行之有效的方法,我们借鉴了 JikesRVM 的锁。我们认为这个算法,包括设置为 40 的自旋限制,对于我们的需求来说足够可移植。JikesRVM 的实验发现它在 1999 年的 12 路 POWER 机器上是最佳的。我发现在 Intel 硬件上,在各种 CPU 和内存拓扑下,当我尝试进一步优化这些锁时,它仍然是最佳的。我为这篇文章运行的微基准测试证实,40 仍然是最佳值,并且在约 10 到 60 次自旋之间存在一个广泛的接近最佳设置的平台。
快速路径
WTF::Lock 的结构围绕着一个用于 lock() 的内联快速路径(只进行一次加锁尝试),以及一个用于 unlock() 的内联快速路径(如果没有线程停泊,则解锁)。拥有小型内联快速路径意味着大多数锁客户端在加锁和解锁时只需付出 CAS 的代价。
WTF::Lock 总结
WTF::Lock 是一个高性能锁,只占用一个字节。底层算法只需要两位,因此它适合将锁塞进位域。有关完整实现,请参阅 wtf/Lock.h 和 wtf/Lock.cpp。
抢占与公平性
WTF::Lock 在处理解锁时做出了一个特定的选择:它会清除 isLockedBit,这使得锁对任何线程都可用,而不仅仅是它唤醒的线程。这意味着等待时间最长的线程可能会被其他线程(可能根本没有等待过)抢走锁。遭受这种失败的线程别无选择,只能再次停泊,这会将其放回队列的末尾。
这个缺点可以通过让 unlock() 在不释放锁的情况下唤醒一个线程来解决。这种协议将锁的所有权从执行解锁操作的线程移交给等待时间最长的线程。如果锁也缺乏自适应自旋循环,那么这种协议会对竞争锁的线程强制执行完美的 FIFO(先进先出)原则。FIFO 是一个吸引人的特性,它能确保没有线程的锁会被抢走。
然而,允许抢占而非强制 FIFO 可以在锁竞争激烈时实现更高的吞吐量。在 WebKit 这样使用细粒度锁的系统中,高竞争意味着多个线程会重复地加锁和解锁同一个锁。在最坏的情况下,一个线程在由同一个锁保护的两个临界区之间进展甚微。在抢占锁中,如果一个线程解锁了一个有线程停泊的锁,那么如果它能在被唤醒的线程调度之前到达下一个临界区,它仍然有资格立即重新获取该锁。抢占允许参与微竞争的线程在每次轮次中多次获取锁。另一方面,FIFO 锁强制竞争者形成一个车队(convoy),他们每轮只能持有锁一次。这使得程序运行比抢占锁慢得多,因为上下文切换次数巨大——每次锁获取都需要一次上下文切换!
Futex 算法与 ParkingLot
ParkingLot 与 futex 非常相似。这两种原语都遵循一个原则:锁不应该维护自己的队列。Futex 从内核获得帮助,并拥有更丰富的 API,这使得一些使用 ParkingLot 无法实现的锁定协议成为可能,例如 优先级继承 锁。然而,ParkingLot 足够强大,足以支持构成 futex 核心的基本 FUTEX_WAIT/FUTEX_WAKE 操作。
FUTEX_WAIT 可以这样实现:
enum Result {
TimedOut, // Timeout was reached.
TryAgain, // The comparison failed.
Success // The thread parked and then unparked.
};
Result wait(Atomic<int32_t>* futex, int32_t expected,
Clock::time_point timeout)
{
bool comparisonSucceeded = false;
bool result = ParkingLot::parkConditionally(
futex,
[&] () -> bool {
comparisonSucceeded = futex->load() == expected;
return comparisonSucceeded;
},
[] () { },
timeout);
if (result)
return Success;
if (comparisonSucceeded)
return TimedOut;
return TryAgain;
}
ParkingLot 通过一个名为 parkConditionally() 的 API 抽象了其一个简单版本。
唤醒一个线程的 FUTEX_WAKE(常见情况)可以通过调用 unparkOne 来实现:
bool wake(Atomic<int32_t>* futex)
{
return ParkingLot::unparkOne(futex).didUnparkThread;
}
能够模拟核心 futex 功能意味着我们可以实现各种基于 futex 的锁算法。我们这样做是为了 对我们的锁实现进行基准测试。以下是我们实现的一些锁算法:
ThunderLock:一种简单的锁算法,它在任何时候只要有线程停泊,就会唤醒所有这些线程。这会释放出一群 “雷鸣般的羊群” 线程,它们都试图抢占锁。除了一个之外,所有线程都必须再次停泊。该算法比BargingLock更简单,只需要三种状态。使用 futex 很容易实现这一点,因为 futex 支持唤醒所有线程的WAKE变体。如果多个锁共享同一个地址,这也是一个很好的算法。CascadeLock:一种自适应锁,类似于 glibc 用于 Linux 上pthread_mutex的lowlevellock算法。该算法在unlock()时最多唤醒一个线程。这种最多唤醒一个线程的自适应锁的难点在于确定原子状态何时可以“忘记”有线程停泊。原子状态越早声称没有线程停泊,unlock()调用就能越早走快速路径。但我们不希望过早忘记停泊的线程,因为这可能导致死锁。WTF::Lock通过使用unparkOne()回调解决了这个问题,但 futex 不支持此功能。相反,CascadeLock解决这个问题的方式是,任何停泊的线程都会在LockedAndParked状态下获取锁。这保守地确保我们永远不会忘记停泊的线程。这也意味着,一旦线程在不进行停泊的情况下成功获取锁,并且没有其他线程竞争,锁就会“忘记”停泊状态,未来的解锁操作将变得快速。HandoffLock:这是一种严格的先进先出锁,它的unlock()会将锁的所有权移交给它唤醒的线程。这种锁比其他算法更具确定性,但正如我们将在性能评估中展示的,它的速度也慢得多。
此外,我们还以相同的方式实现了 WTF::Lock 的一个版本,以便于与其他算法进行比较:
BargingLock:WTF::Lock的可配置版本。这种锁无法使用 futex 实现,因为它需要在unparkOne()中使用回调,而只有ParkingLot提供了此功能。
WTF::Condition
ParkingLot 的停泊/唤醒操作与条件变量的需求完美契合。WTF::Condition 支持多种条件变量原语,例如各种带超时的等待。在本节中,我们只考虑三个最基本的基本原语,因为其他原语很容易在此基础上构建:wait、notifyOne 和 notifyAll。
条件变量最难的部分是它必须在线程等待条件的同时看起来解锁了锁。如果先解锁锁,然后单独等待条件,则意味着 notify 操作可能发生在解锁之后、等待之前。我们通过 parkConditionally 的 beforeSleep 回调来解决这个问题。这个回调在 ParkingLot 将调用线程放入停泊队列之后,但在线程实际停泊之前运行。这意味着一旦锁被解锁,任何 notify 操作都保证会将此线程从条件变量中释放。
这是一种简单而精确的算法,它确保 wait 除非条件被通知,否则永远不会返回。
有趣的是,这个算法意味着 WTF::Condition 实际上不需要将其任何数据放入其原子状态——它只是使用它来访问 ParkingLot 中的队列,然后由 ParkingLot 完成所有工作。我们利用这一点,使用 Condition 的内容来记录是否有任何等待者。我们使用 ParkingLot 的各种其他回调来维护此缓存,并在没有人等待时使 notifyOne/notifyAll 非常快:它们只需直接返回,而无需调用 ParkingLot。
基本 Condition 操作的完整算法是:
class Condition {
public:
Condition()
{
m_hasWaiters.store(false);
}
void wait(Lock& lock)
{
ParkingLot::parkConditionally(
&m_hasWaiters,
[this] () -> bool {
// This is the validation callback. It runs with the queue lock
// held. We will return true, so we know that the queue will
// have waiters before we release the queue lock.
m_hasWaiters.store(true);
return true;
},
[this, &lock] () {
// This is the beforeSleep callback. It runs once our thread
// is on the parking queue and so will definitely be notified -
// and so won't actually sleep - if an unpark operation
// happens. This runs after we have already unlocked the queue
// lock, so it's safe to do whatever we like. We use this as an
// opportunity to unlock the lock.
lock.unlock();
});
lock.lock();
}
void notifyOne()
{
if (!m_hasWaiters.load())
return;
ParkingLot::unparkOne(
&m_hasWaiters,
[this] (ParkingLot::UnparkResult result) {
m_hasWaiters.store(result.mayHaveMoreThreads);
});
}
void notifyAll()
{
if (!m_hasWaiters.load())
return;
m_hasWaiters.store(false);
ParkingLot::unparkAll(&m_hasWaiters);
}
private:
Atomic<bool> m_hasWaiters;
};
这种情况说明了与 futex 的一些差异。使用 futex 支持条件变量需要更多的“魔法”,因为我们必须在调用 FUTEX_WAIT 之前解锁锁。这将允许在解锁和等待之间发生 notify 调用。
一种解决方法是使用原子状态来指示当前是否有线程在解锁和等待之间陷入困境。我们会在 wait 开始时将其设置为 true,并在 notify 开始时将其设置为 false。不幸的是,这会导致 wait 的虚假返回:只要在我们调用 FUTEX_WAIT 之前发生 notify 操作,wait 就会返回,即使 notify 也唤醒了其他线程。根据 pthreads 和 Java,这会是 wait 的一个有效实现,因为它们都允许虚假唤醒。
我们喜欢 ParkingLot 允许我们避免虚假唤醒。在调试并发代码时,能够隔离发生了什么情况非常棒。确保 wait 仅在收到通知后才返回,这在尝试理解并发程序的行为时提供了一种可喜的确定性。
WTF::Lock 和 WTF::Condition 都只占用一个字节,并实现了您对这类同步原语所期望的所有功能。这得益于 ParkingLot API 的灵活性。ParkingLot 也足够强大,可以支持许多基于 futex 的算法,因为 ParkingLot::compareAndPark/unparkOne 是 FUTEX_WAIT/FUTEX_WAKE 的进程内等效项。
实现 WTF::ParkingLot
WTF::ParkingLot 提供了构建任何类型自适应锁所需的基本原语。ParkingLot 是停泊线程队列的集合。队列以其锁的原子状态的地址作为键。ParkingLot 基于并发哈希表以最大化并行性——即使许多线程正在经历竞争并需要对队列执行操作,这些线程也可能并行执行其队列操作,因为哈希表没有单一瓶颈。
我们使用 ParkingLot 来节省锁中的内存。任何边表方法的一个风险是,我们只是将空间消耗从锁对象转移到 ParkingLot。幸运的是,ParkingLot 给了我们一个强有力的保证:ParkingLot 的大小受线程数量的限制。它主要依赖于线程局部对象,这些对象在需要时分配,并在线程终止时自动销毁。正如我们将展示的,ParkingLot 的所有数据结构都遵循其大小渐近地受线程数量限制的规则。这意味着锁的数量,甚至您在锁上竞争的频率,都不会影响 ParkingLot 的硬性 O(线程数) 空间限制。作为这种固定每线程开销的交换,ParkingLot 使您的所有锁每个只占用一个字节。
有三个基本操作:parkConditionally、unparkOne 和 unparkAll。本节中我们只描述前两个,因为 unparkAll 使用与 unparkOne 相同的逻辑实现起来非常简单。
同步队列的并发哈希表
实现 ParkingLot 的一个简单方法是使用一个单一锁来守护一个将地址映射到队列的哈希表。这对于并行度不高的程序来说可能效果很好,但这个锁会在多线程程序中成为瓶颈。ParkingLot 通过使用并发哈希表来避免这个瓶颈。
并发哈希表背后的直觉是,不同的线程不太可能相互干扰,因为它们可能使用不同的键进行访问,这些键哈希到不同的桶中。因此,即使是并发写入也可能并行进行。最复杂的并发哈希表算法在整个过程中都使用无锁数据结构。但一个更简单的方法是为每个桶加上锁。这是我们在 ParkingLot 中采取的方法。算法相当简单,因为我们不需要优化大小调整。我们可以采取这些捷径,因为:
- 只有一个并发哈希表。
ParkingLot是不可实例化的。它的所有成员函数都是静态的。因此,在任何进程中只有一个这样的并发哈希表。 - 它的大小受线程数量的限制。一个线程本身就已经占用大量内存。这意味着我们不必担心这个哈希表的空间消耗,只要它是 O(线程数) 并且每线程开销远小于典型的线程栈即可。
- 一旦我们在哈希表中找到队列,就必须获取与其关联的锁。这意味着将哈希表本身设计为无锁并不会带来太大益处。它的所有使用者无论如何都会获取一个锁。这促使我们寻找一个不涉及无锁并发哈希表的解决方案——只是一种旨在最小化锁竞争的方案。
- 遍历整个表并不常见,也不是很重要。这意味着迭代(例如大小调整)可以很粗糙。
我们的调整大小算法会泄露旧的(较小的)哈希表。这对于使算法健壮至关重要。因为只有一个 ParkingLot 并且它的大小受线程数量的限制,我们可以计算出泄露内存量的硬性上限。
我们的调整大小算法最重要的部分是它使调整大小成为一个极其罕见的事件。表的大小调整仅在以下条件出现时发生:
- 一个线程首次停泊。
- 当时线程数大于哈希表大小的三分之一。
这确保了大小调整只在线程的高水位线增加时发生。当我们扩容表时,新大小总是我们所需大小的两倍。这些规则结合起来确保,如果在任何时候活跃线程的最大数量为 N,那么我们曾经执行的大小调整次数最多为 log(N)。既然我们知道可以实现一个非常糟糕的大小调整算法,我们首先将考虑如何在没有大小调整的情况下使 ParkingLot 工作。
固定大小哈希表的简化算法
让我们假设哈希表大小是固定的,并且所有线程都同意一个指向该哈希表的指针。这使得我们能够考虑一个更简单的算法版本。我们稍后再考虑添加大小调整功能。
我们使用的基本算法是每个哈希表桶都是一个队列。每个桶都有一个锁(具体来说,是本节稍后描述的 WordLock)来保护自身。我们将此锁用作 ParkingLot API 的队列锁。哈希表只支持入队(enqueue)和出队(dequeue),因此冲突通过简单地交错冲突队列来处理。例如,如果地址 0x42 和 0x84 都哈希到索引 7 处的桶,并且您执行一系列入队操作,例如:
- enqueue(0x42, T1)
- enqueue(0x42, T2)
- enqueue(0x84, T3)
- enqueue(0x84, T4)
那么索引 7 处的桶将指向一个如下所示的队列:
head -> {addr=0x42, thr=T1} -> {addr=0x42, thr=T2} -> {addr=0x84, thr=T3} -> {addr=0x84, thr=T4} <- tail
这种设计意味着入队完全不必担心冲突;它只需在队列节点中记录实际所需的地址(即当前线程的 ThreadData)。出队通过从头开始查找列表中第一个具有我们正在出队的地址的元素来解决冲突。
线程停泊后入队时,ParkingLot 必须将其挂起,直到在唤醒时将其出队。ParkingLot 使用线程局部条件变量来挂起线程。在此代码路径上,只有大的开销才重要,因为其性能主要受操作系统使线程不再可运行的工作量的影响。因此,ParkingLot 最终使用操作系统条件变量代码是没有问题的。
在这种设计中,ParkingLot::parkConditionally 的执行流程如下:
- 对提供的原子状态地址进行哈希,以获取哈希表中的索引。更好的是,这直接给我们一个指向我们桶的指针。从这里开始,我们只关注这个桶。
- 锁定该桶的锁。
- 调用提供的验证回调。该桶的锁也是客户端原子状态地址的队列锁,因此在此处调用验证回调满足
parkConditionally的契约。如果验证失败,我们释放桶锁并返回。 - 如果验证成功,我们通过将其附加到链表尾部来将当前线程入队。当前线程的
ThreadData将包含我们正在停泊的地址。 - 解锁该桶的锁。
- 调用
beforeSleep回调。在此刻进行工作对于条件变量来说非常有用;稍后将详细说明。 - 等待当前线程的停泊条件变量。
通过 ParkingLot::unparkOne 唤醒线程的流程如下:
- 对提供的原子状态地址进行哈希,以获取桶指针。
- 锁定该桶的锁。
- 从队列头部向前搜索,找到队列中第一个匹配我们地址的条目,然后删除该条目。我们可能找不到任何此类条目。队列甚至可能完全为空。
- 调用提供的回调,告知它我们是否已出队任何线程,以及队列中是否还有更多元素。在我们持有桶锁时向客户端提供这些信息对锁来说非常有用;稍后将详细说明。
- 解锁该桶的锁。
- 如果我们已经出队了一个线程,则通过信号通知其停泊条件变量,告知它可以现在唤醒。
ParkingLot 的其他操作是这两种操作的简单变体。ParkingLot::compareAndPark 只是 parkConditionally 的一个包装器,而 unparkAll 几乎与 unparkOne 相同,只是它查找所有匹配地址的条目,而不仅仅是第一个。
调整哈希表大小
我们不想猜测进程将拥有多少线程。WebKit 的贡献者有时喜欢添加线程,我们不希望阻止这一点。Web API 可以导致 WebKit 启动线程,并且线程数量可以由网页控制。因此,我们不想陷入猜测我们将看到多少线程的业务。这意味着哈希表必须是可调整大小的。
如果我们锁定当前哈希表中的每个桶,那么我们就拥有对表的独占访问权限,可以随心所欲地操作它。任何希望访问该表的其他线程都将卡在尝试获取某个桶的锁上,因为上一节中的停泊/唤醒操作都始于锁定某个桶的锁。直观地说,调整大小可以简单地锁定旧表的所有桶,然后分配一个新的哈希表并将旧表的内容复制到其中。然后,在仍然持有所有桶的锁的情况下,它可以将全局哈希表指针重新指向新表。之后,我们可以释放旧表中桶的锁。这意味着另一个变化:停泊/唤醒算法将在桶锁被锁定后检查全局哈希表指针是否仍然相同。如果不调整大小,停泊的实现可能看起来像:
void ParkingLot::parkConditionally(...)
{
Hashtable* hashtable = g_hashtable; // load global hashtable pointer.
Bucket* bucket = hashtable->buckets[hash % hashtable->size];
bucket->lock.lock();
// The rest of the parking algorithm...
}
调整大小意味着任何哈希表操作将以如下方式开始:
void ParkingLot::parkConditionally(...)
{
Bucket* bucket;
for (;;) {
Hashtable* hashtable = g_hashtable;
bucket = hashtable->buckets[hash & hashtable->size];
bucket->lock.lock();
if (hashtable == g_hashtable)
break;
// The hashtable resized while we were waiting for the lock. Try
// again.
bucket->lock.unlock();
}
// At this point, we will have a bucket, it will be locked, and the
// hashtable is not resizing.
// The rest of the parking algorithm...
}
调整大小后,我们需要泄露旧的哈希表。在解锁所有桶后,我们无法确定有多少线程仍然卡在加载旧哈希表指针和尝试锁定桶之间。由于操作系统调度,线程可能会在任意两条指令之间卡住不确定时间。更糟的是,一个桶的锁可能有任意数量的线程在等待它,所以我们不能删除这个锁。与其尝试询问操作系统系统中所有线程的状态以检测何时可以安全删除旧表,我们干脆就泄露旧的哈希表。这没关系,因为是指数级大小调整。假设哈希表从大小 1 开始,并调整大小到 64。那么我们将分配如下大小的哈希表:
1 + 2 + 4 + 8 + 16 + 32 + 64
这是一个几何级数,收敛于 127(即 64 * 2 – 1)。通常,由于泄露旧表而浪费的内存量与当前表使用的内存量成比例。有点幽默的是,ParkingLot 会将所有“泄露的”哈希表记录在一个全局向量中,以确保内存泄露检测工具不会因为这些无害且故意的泄露而打扰我们。
我们进一步优化了这一点,将桶(bucket)设为单独的堆分配对象。哈希表只包含指向桶的指针,并且我们在调整大小时重用桶。这意味着我们唯一泄露的是桶指针数组,它的数量级比所有桶的总大小小得多。在我们的实现中,泄露是有界的(总泄露内存量受我们正在使用的内存量限制)并且非常小(它受限于指针数组的大小,这远小于用于桶的总内存量,而后者又受线程数量限制,并且远小于线程用于栈等其他事物的总内存量)。
WTF::ParkingLot 总结
总而言之,ParkingLot 提供了以锁的内存地址为键的停泊队列。ParkingLot 的内存使用与锁的数量无关——它受当前停泊线程数量的限制(而停泊线程的数量又受线程总数的限制)。通过一些简单的并发技巧,ParkingLot 能够在不同线程在不同地址上排队时提供并行性。有关完整实现,请参阅 wtf/ParkingLot.h 和 wtf/ParkingLot.cpp。
WTF::WordLock
WTF::ParkingLot 需要一个锁实现来保护桶。这不应该是一个自旋锁,因为我们没有限制在持有锁时可能执行的代码量。ParkingLot 将使用此锁来同步 parkConditionally() 中的 validation 和 unparkOne() 中的 callback。尽管这些回调通常工作量很小,但我们不想对其施加严格限制。我们还需要锁在微竞争下表现良好,并且不占用太多内存。这意味着我们需要类似 WTF::Lock 的东西。
幸运的是,如果我们愿意使用一个完整的指针大小的字(word),就可以在没有 ParkingLot 的情况下实现该算法。这就是 WTF::WordLock 为我们提供的。它不如 WTF::Lock 理想,因为它需要更多内存,但它是独立的,因此我们可以将其用于 ParkingLot 的所有锁定需求。一个 WordLock 实例内部只有一个 Atomic<uintptr_t>。除了某些小的每线程数据结构外,没有其他开销,这些结构在线程首次竞争锁时创建,并在线程终止时自动销毁。
一个锁需要三种数据结构:原子状态、线程队列以及一个保护队列的锁。在我们的 BargingLock 算法中,原子状态包含一个位,指示锁是否已锁定,以及一个位,指示队列是否非空。WordLock 调整了此算法,使其原子状态成为指向队列头部的指针,同时窃取该指针的两个低位来表示锁是否已锁定以及队列是否已锁定。我们对原子状态的解释如下:
- 最低位是
isLockedBit。 - 次低位是
isQueueLockedBit。 - 其余位是指向队列头部的指针,如果队列为空则为 null。
队列使用 ThreadData 对象表示。每个线程有一个这样的对象。它包含管理队列所需的指针,包括 next 指针和 tail 指针。我们约定队列的头部指向尾部,这消除了为存储指向尾部的指针而分配其他内存的需要:原子状态只指向头部,这提供了一种 O(1) 的方式来查找尾部。
在所有其他方面,WTF::WordLock 都遵循 BargingLock 算法。我们的实验将表明,除了空间使用方面,WordLock 的性能与 Lock 相同。有关完整实现,请参阅 wtf/WordLock.h 和 wtf/WordLock.cpp。
性能
我们将 WebKit 中的所有锁替换为 WTF::Lock,因为它比自旋锁更安全(线程没有在自旋循环中浪费时间的可能性),并且比操作系统提供的互斥锁更快、更小。本节展示了这一变更对性能的影响,包括对 WebKit 未使用但我们偶然发现或听说其他人使用的锁定协议的一些探讨。
本节首先展示在运行 WebKit 基准测试时 WTF::Lock 的性能,然后展示使用各种不同锁变体的微基准测试结果。
WTF::Lock 在 WebKit 中的性能
在 WTF::Lock 之前,WebKit 使用了操作系统提供的互斥锁和自旋锁的混合方式。我们会猜测锁对快速路径性能和空间的重要性以及临界区可能持续多长时间。对于我们认为可能很长的临界区,我们总是使用操作系统提供的互斥锁。我们有数据显示,至少在某些情况下我们选择不正确:其中一些操作系统提供的互斥锁正在减慢我们的速度,而一些自旋锁会导致 sched_yield 出现在时间剖析中。猜测使用哪种锁的困难促使我们实现了 WTF::Lock。
现在很难撤销此更改并回到为不同临界区选择不同锁的世界,我们怀疑使用自旋锁通常不是一个好主意。如果代码的某个部分意外地花费很长时间,例如由于交换(swapping),那么我们最不希望看到的是其他线程开始忙等待锁。我们也从经验中得知,试图通过让自旋锁有时休眠来缓解该程序只会降低常见情况下的性能。
本节旨在证明,如果您知道需要一个自适应锁,那么 WTF::Lock 就是您想要使用的。我们使用了三个基准测试:JetStream 1.1、Speedometer 1.0 和 PLT3(我们的内部页面加载时间测试)。所有这些基准测试都在一台 Mac Pro 上运行,该机器配备两颗 2.7 GHz 6 核 Xeon E5 CPU(带超线程,即 24 个逻辑 CPU)和 16 GB 内存,运行 El Capitan 系统。“OS 互斥锁”的结果是通过将 WTF::Lock 替换为 pthread_mutex_t 的包装器得出的。WTF::Lock 的结果是基线。这些数据是使用 WebKit r199680 并回溯了 r199690(因为它影响了这台机器上的性能)后收集的。
JetStream 性能

此图表显示了 OS 互斥锁和 WTF::Lock 的 JetStream 分数。分数越高越好。
JetStream 是一个 JavaScript 基准测试,由小型到中型程序组成,用于测试我们 JavaScript 引擎的各个部分。WebKit 在运行 JavaScript 程序时严重依赖锁。在最极端的情况下,每个对象可能都有自己的锁,并且可以在任何属性访问时获取此锁。这对于允许我们的并发编译器检查堆是必要的。没有锁,这些访问将不安全。这些 JetStream 数据表明在运行 JavaScript 时拥有快速的锁非常重要。
Speedometer 性能

此图表显示了 OS 互斥锁和 WTF::Lock 的 Speedometer 分数。分数越高越好。
Speedometer 是一个 JavaScript 和 DOM 基准测试,由在不同 Web 框架中实现的 Web 应用组成。它对整个引擎施加压力。我们可以看到,对于这项真实的测试,WTF::Lock 提供了 5% 的加速。
PLT3 性能

此图表显示了 PLT3 几何平均页面加载时间。时间越短越好。
如果您切换到 WTF::Lock,PLT3 会加速 5%。由于 PLT3 并非完全由 JavaScript 主导,这表明 WebKit 中还有许多其他锁受益于其快速性。
WebKit 锁性能总结
WTF::Lock 总是比 pthread_mutex_t 带来性能提升。它还小 64 倍——它只使用一个字节,而 pthread_mutex_t 使用 64 个字节。根据这些数据,我们确信正确的选择是继续使用 WTF::Lock 而非 pthread_mutex。
微基准测试性能
本节探讨了在简单微基准测试中各种锁的性能,该微基准测试可以启动任意数量的线程,这些线程重复地锁定一个锁并执行少量浮点数学运算(每次循环迭代执行一次双精度加法和乘法)。我们可以改变锁定协议以及锁定协议的一些参数(例如在停泊之前它将执行的自旋次数)。这将 WTF::Lock 和 WTF::WordLock 与自旋锁以及使用 ParkingLot 的其他各种锁算法进行比较。本节还将 WTF::Lock 与 std::synchronic 以及 硬件事务内存 进行比较。
这些基准测试在配备 2.6 GHz Intel Core i7 四核处理器(带超线程)和 16 GB 内存的 MacBook Pro 上运行,系统为 El Capitan。
不同线程数下的微竞争
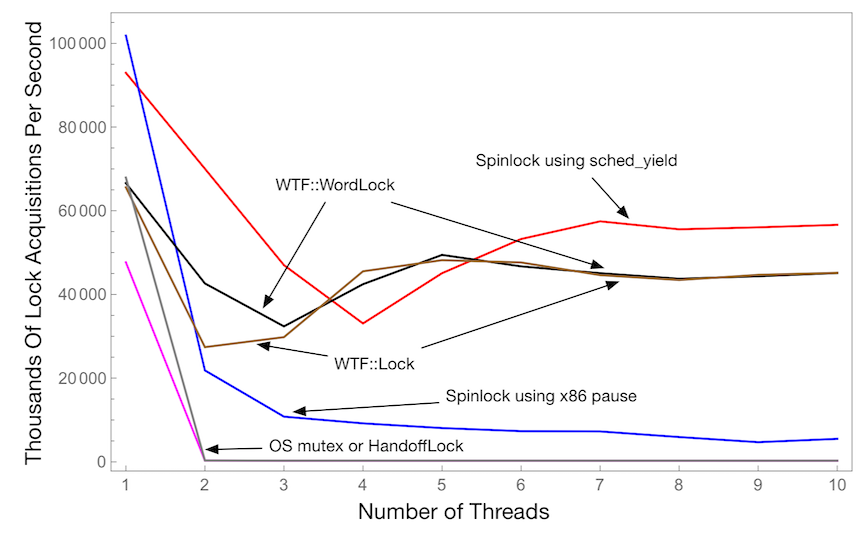
此图表显示了所有线程每秒成功获取锁的次数,作为线程数量的函数。这使用了一个临界区,在持有锁时执行一次循环迭代。越高越好。
我们使用六种锁定协议:
- 操作系统互斥锁。
HandoffLock。这是一个使用ParkingLot实现的完全公平的互斥锁。- 在自旋时使用
sched_yield的自旋锁. - 在自旋时使用 x86
pause指令的自旋锁. WTF::WordLock.WTF::Lock.
此图表显示,随着线程数量的增加,WTF::Lock 能够轻松保持其性能。很难看出 OS 互斥锁和 HandoffLock 有多慢。实际上,对于 10 个线程,它们慢了大约 160 倍。
请注意,对于单个线程,最快的锁总是自旋锁。这是因为自旋锁在解锁时不必使用 CAS。对于带有队列的锁,在解锁时使用 CAS 是必要的,因为您需要在解锁时检查是否有停泊的线程。自旋锁不这样做,因此它们可以直接将 0(或任何表示“未锁定”的值)存储到锁的原子状态中。
同样清楚的是,根据竞争线程的数量,不同的锁具有非常不同的性能。看起来 WTF::Lock 对于两到三个线程来说并不是那么出色。
最后,很明显 x86 的 pause 指令对我们的自旋锁没有用。Intel 显示它能带来加速,但我们无法证实他们的说法。
优化 WTF::Lock 的自旋限制
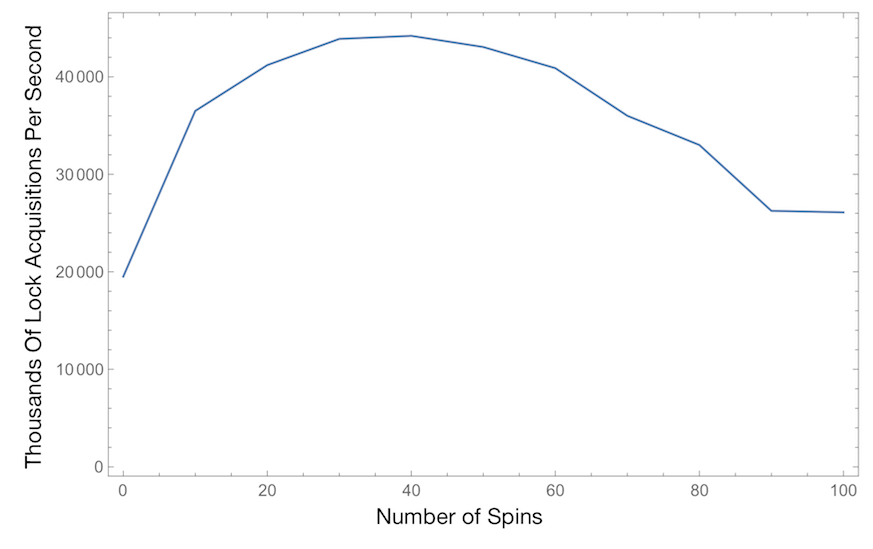
此图表显示了所有线程每秒成功获取锁的次数,作为自旋限制的函数。越高越好。此测试使用 4 个线程,因为对于更少的线程,自旋限制影响不大,而对于更多的线程,图表看起来与此没有太大区别。这使用了一个临界区,在持有锁时执行一次循环迭代。
我们最初根据古老的 JikesRVM 实验选择了 40 的自旋限制。令人惊讶的是,此图表精确地证实了 40 仍然是最佳值。
不同锁的微竞争
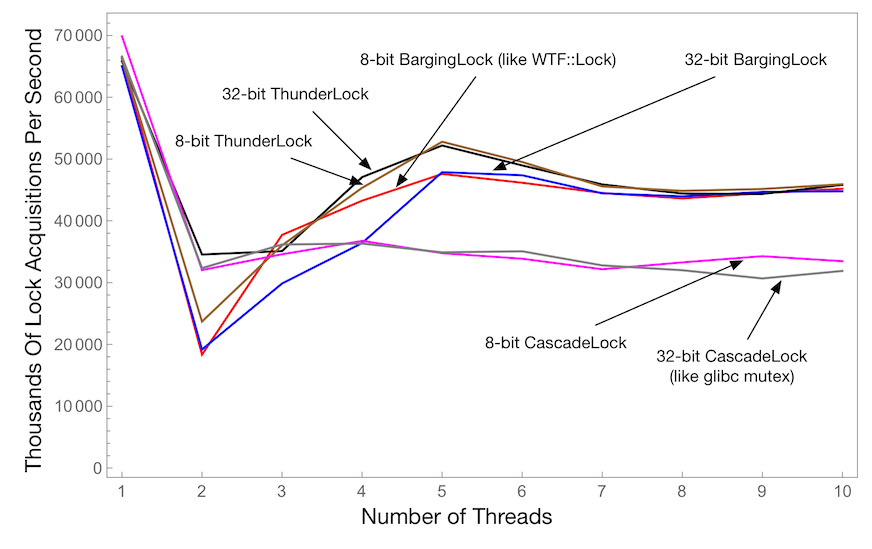
此图表显示了所有线程每秒成功获取锁的次数,作为线程数量的函数。这使用了一个临界区,在持有锁时执行一次循环迭代。越高越好。
这部分探讨了三种算法:
ThunderLock。每当它唤醒线程时,都会释放出一群“雷鸣般的羊群”。CascadeLock。这基于 glibc 的lowlevellock算法。BargingLock。这类似于WTF::Lock,但更具可配置性。
然后我们以两种变体运行每种算法:一种是 8 位,另一种是 32 位。
此图显示,CascadeLock 和 ThunderLock 在线程数量较少时表现出出色的性能。BargingLock 和 ThunderLock 在线程数量较多时表现出最佳性能。此图表表明,如果我们将 ThunderLock 和 CascadeLock 的优点整合到 WTF::Lock 算法中,可能会获得额外的性能改进。另一方面,这个微基准测试相当极端,并没有决定性地偏向于这些算法中的任何一种。由于这些结果,我们有一个未解决的 bug,关于继续重新考虑我们的 WTF::Lock 实现。
不同临界区长度下的竞争
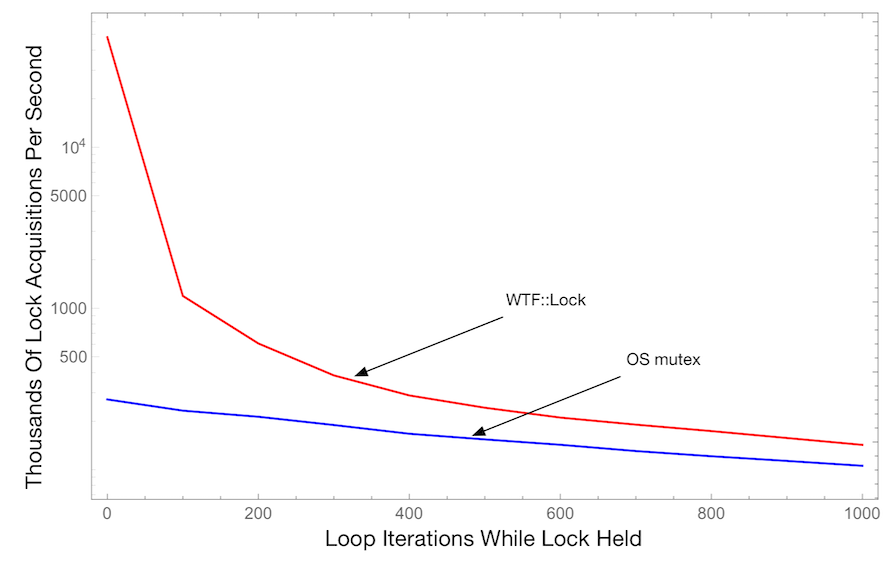
此图表显示了所有线程每秒成功获取锁的次数,作为临界区被持有期间循环迭代次数的函数。越高越好。此测试使用 4 个线程。
所有之前的微基准测试图表都使用了非常短的临界区。这显示了当临界区长度增加时会发生什么。意料之中地,OS 互斥锁和 WTF::Lock 之间的性能差距减小了,但即使对于长的临界区(1000 次双精度乘法和 1000 次双精度加法),WTF::Lock 仍然快了近 2 倍。
锁的公平性
操作系统互斥锁的一个优点是它们保证公平性:所有等待锁的线程形成一个队列,当锁被释放时,队列头部的线程会获取它。它是 100% 确定的。尽管这种行为使互斥锁更容易推断,但它降低了吞吐量,因为它阻止线程重新获取刚刚释放的互斥锁。WebKit 线程重复获取同一个锁是很常见的。本节试图评估 OS 互斥锁和 WTF::Lock 的相对公平性。
我们的 公平性基准测试 在持有锁的情况下启动十个线程。它在启动线程后稍作等待,以最大化所有这些线程堆积在锁队列上的可能性。然后我们释放锁,并计算在 100 毫秒的运行期间每个线程获取锁的次数。一个 FIFO 锁将确保每个线程获取锁的次数相同,除了可能存在一步的误差:每当 100 毫秒的测试运行结束时,某些线程可能正好有机会多获取一次锁,因为它们碰巧在循环中首先到达。
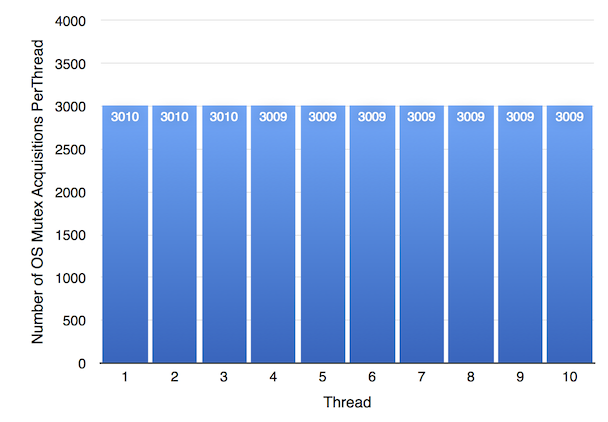
上图显示了 OS 互斥锁的公平性结果。正如预期,它是完全公平的。
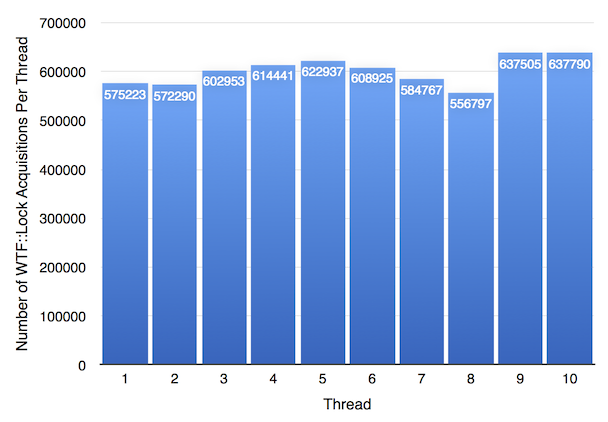
根据上图,WTF::Lock 的公平性略差。然而,最不幸运的 WTF::Lock 线程仍然比任何 OS 互斥锁线程多获取了大约 180 倍的锁:线程 8 是最不幸运的 WTF::Lock 线程,仅获取了 556797 次,比最幸运的线程 10 少了 15%。但与 OS 互斥锁线程所能达到的最佳次数 3010 相比,这是一个巨大的锁获取次数。
这是一个令人惊讶的结果。显然,OS 互斥锁完全按照其设计意图运行:没有线程比其他线程执行更多的工作。另一方面,WTF::Lock 不保证公平性。对算法的分析表明,等待获取锁时间最长的线程可能无法获取锁,并被迫回到队列末尾。但这张图表显示,即使没有公平性保证,使用 WTF::Lock 的最不幸运的线程也比使用保证公平互斥锁的任何线程获得了更好的待遇。这几乎就像 OS 互斥锁实际上并不公平,因为虽然线程 1 和线程 2 得到同等服务,但相对于一个使用不同算法的假设线程 11,所有 10 个线程都服务不足。事实上,我们可以将线程 11 视为操作系统上下文切换处理器。
公平算法在某些情况下是有意义的,例如,如果所有临界区都很长,并且任何线程的最长等待时间受线程数量及其临界区总长度的限制很重要。但 WebKit 使用非常小的临界区,其中一些会发生竞争。事实证明,在小型临界区中确保公平性的成本过高,不切实际。
我们必须考虑操作系统互斥锁由于公平性以外的某些原因比 WTF::Lock 慢的可能性。我们可以对此进行测试,因为我们还实现了 HandoffLock,这是一个使用 ParkingLot 实现的完全公平的锁。
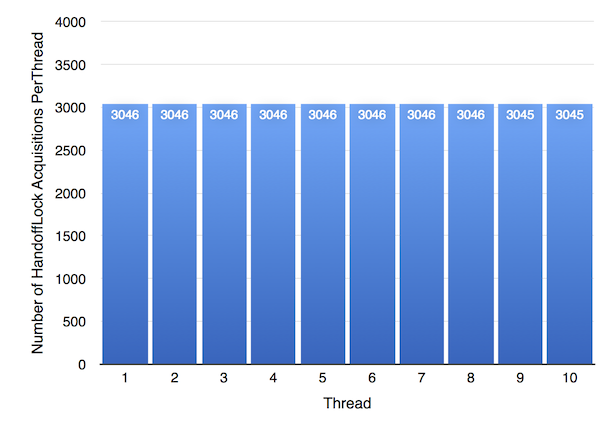
上图显示了 HandoffLock 的公平性结果。它的表现几乎与 OS 互斥锁完全相同。这个结果有一些有趣的含义。它表明 OS 互斥锁的性能很可能完全归因于其确定性的公平性保证。这也意味着 ParkingLot 引入的额外开销不会对 ParkingLot 在线程之间移交执行的速度产生不利影响。
与其他新型锁的比较
C++ 语言有一个名为 std::synchronic 的提案特性,它解决了与 ParkingLot 相同的一些问题。它允许用户编写自己的锁,并且这些锁可以占用少量内存。锁算法非常注重如何处理竞争,以便即使多个线程想要持有同一个锁时也能优化吞吐量。在学术计算机科学中,一种流行的处理竞争的方法是 事务内存(transactional memory)。如果一个事务性临界区存在竞争,但竞争线程除了获取锁的竞争之外没有其他竞争(即它们访问的是除了锁本身之外的不相交内存),那么这些线程将可以并发运行。如果检测到竞争,一些线程将中止并重试,可能会退回到传统的锁算法。现代 x86 芯片通过 硬件锁省略 (HLE) 支持事务内存。WebKit 避免使用单一锁来保护不相关的数据,因为这既笨拙(将一个微小的 WTF::Lock 放在它所保护的任何字段旁边最容易)又不是最优的(它导致无意义的竞争)。在 WebKit 中,我们添加锁是为了保护数据竞争,因此事务不太可能有所帮助。本节评估了这些替代方案的性能,重点关注 WebKit 风格的临界区,其中锁上的竞争意味着对相同底层数据的竞争。

此图表显示了所有线程每秒成功获取锁的次数,作为线程数量的函数。这使用了一个临界区,在持有锁时执行一次循环迭代。越高越好。
为了测试 std::synchronic,我们实现了一个锁,它遵循 synchronic 测试套件中的“TTAS 锁”算法。为了测试 HLE,我们实现了一个用 xacquire/xrelease 包装的基本自旋锁。如本图所示,WTF::Lock 始终比这两种锁中的任何一种都快得多。我们怀疑 std::synchronic 性能相对较差,因为它要求 ParkingLot::unparkOne() 的模拟操作在每次释放锁时都运行,即使没有人等待。另一方面,使 std::synchronic 稍慢的相同特性也使其 API 更易于使用。我们怀疑 HLE 性能相对较差,因为此基准测试中的锁保护的是数据竞争。我们只在 WebKit 中存在数据竞争需要保护时才使用锁,所以尽管这个基准测试对 HLE 的预期用例不公平,但我们认为它是一个模拟我们如何使用锁的适当基准。我们并不是第一个发现事务内存不尽如人意的。该帖子指出,事务内存的一个问题是缺乏杀手级应用,并指出整个行业都缺乏并发杀手级应用。WebKit 使用并发来显著加速 JIT 编译,并使用并行性来显著加速垃圾回收,这两者都得益于快速锁。
总结
我们将 WebKit 的所有锁替换为我们自己的锁实现,称为 WTF::Lock。我们这样做是因为我们希望积极地减小锁的大小,同时提高整体性能。我们还希望锁具有自适应性,这样当锁被长时间持有时,线程就不会自旋。这个名为 WTF::Lock 的新锁是使用一个可重用的线程停泊和排队抽象实现的,这个抽象在实现新的 Web 标准时将派上用场。