推出 B3 JIT 编译器
截至 r195562,WebKit 的 FTL JIT(Faster Than Light 即时编译器)现在在 OS X 上使用了一个新的后端。Bare Bones 后端,简称 B3,取代了 LLVM 成为 FTL JIT 中的低级优化器。尽管 LLVM 是一个出色的优化器,但它并非专门为 JavaScript 等动态语言的优化挑战而设计。我们认为,如果我们将 FTL 架构的优点与一个整合了我们从使用 LLVM 中学到的经验但又专门针对我们需求进行调整的新编译器后端相结合,就可以获得更大的速度提升。本文回顾了 FTL JIT 的工作原理,描述了 B3 的动机和设计,并展示了 B3 如何融入 WebKit 的编译器基础设施。
FTL JIT 背后的理念
FTL JIT 的设计理念是结合了推断类型并优化掉类型检查的高级优化编译器,以及处理寄存器分配等传统优化的低级优化编译器。我们使用现有的 DFG(数据流图)编译器进行高级优化,并使用 LLVM 作为低级编译器。这种架构更改非常成功,为优化热代码路径提供了额外的性能提升。
高级编译器和低级编译器通过一个称为 FTL::LowerDFGToLLVM 的降低阶段连接在一起。该阶段将低级编译器的中间表示抽象为一个名为 FTL::Output 的接口。抽象低级编译器意味着我们在选择使用哪种后端时具有一定的灵活性。我们选择 LLVM 作为 FTL 的初始实现,因为它免费可用,并且在生成高效代码方面表现出色。这意味着 WebKit 可以享受到成熟优化编译器的优势,而无需 WebKit 工程师自行实现。
FTL JIT 最初的作用是对已经通过我们更注重延迟的低级 JIT(如 DFG JIT)进行了足够高级优化的代码提供额外的低级优化。但随着我们对 FTL JIT 的优化,我们发现自己为其添加了强大的高级优化,而没有在低级 JIT 中实现同等优化。这样做是合理的,因为 FTL 使用低级优化后端意味着高级优化可以更粗糙,因此运行更快,编写也更迅速。例如,专门为 FTL 编写的转换可以留下死代码、不可达代码、未融合的加载/比较/分支序列以及次优的 SSA 图,因为 LLVM 会清理这些内容。
FTL JIT 的能力远超其各部分的总和,其吞吐量优势的很大一部分与 LLVM 无关。以下是 FTL JIT 执行但我们其他 JIT 和 LLVM 所没有的优化列表(不完全)
有时,即使 LLVM 也有某种优化,FTL 也会自己实现。LLVM 具有以下优化,但我们使用自己的 FTL 实现,因为它们需要了解 JavaScript 语义才能完全有效
FTL 已经变得如此强大,以至于在任何测试中提高 WebKit JavaScript 性能的基本策略是首先确保测试能从 FTL 中受益。但在某些平台以及一些总运行时间不足或包含大量编译缓慢代码的工作负载上,瓶颈仅仅是 FTL 的编译时间。在某些程序中,我们付出了运行 FTL 编译器线程的代价,但等到编译器完成时,程序已经运行完这些函数了。现在是时候解决编译时间问题了,由于 FTL 编译时间的绝大部分——通常是四分之三或更多——都归因于 LLVM,这意味着需要重新考虑 LLVM 是否应该作为 FTL 的后端。
设计新的编译器后端
我们知道,如果我们能在不完全支付 LLVM 编译时间成本的情况下,获得 FTL 的所有高级优化,那么就能在大量实际的 JavaScript 代码上获得速度提升。但我们也知道,LLVM 的低级优化对于运行时间足够长以隐藏编译时间的基准测试至关重要。这是一个巨大的机遇,也是一个巨大的风险:击败 LLVM 的编译时间看起来很容易,但只有当新的后端能在吞吐量上具有竞争力时,这才会是净收益。
与 LLVM 竞争是一项艰巨的任务。LLVM 投入了多年的工作,并包含了针对类 C 语言的全面优化。正如 FTL JIT 项目之前所展示的,LLVM 在优化 JavaScript 程序方面表现出色,并且其编译时间也足够好,因此使用 LLVM 对 WebKit 来说是一个净收益。
我们预计,如果能构建一个比 LLVM 编译速度快大约十倍,同时仍能生成可比较代码的后端,那么就能在当前受 LLVM 编译阻塞的代码上获得速度提升。机会大于风险。我们于2015 年 10 月下旬开始开发原型。我们的直觉是,我们需要一个与 LLVM 具有相同粒度级别,并因此允许相同类型优化的编译器。为了让编译器运行更快,我们使用了更紧凑的 IR(中间表示)。我们的计划是通过不仅实现 LLVM 具有的相同优化,而且进行 WebKit 特定的调整来匹配 LLVM 的吞吐量。
本节的其余部分将描述 Bare Bones 后端的架构,并特别关注我们计划如何使其在减少总体 FTL 编译时间的同时实现高吞吐量。
B3 中间表示
我们知道,我们想要一个低级中间表示,它能暴露原始内存访问、原始函数调用、基本控制流以及与目标处理器能力紧密匹配的数值操作。但低级表示意味着需要大量内存来表示每个函数。使用大量内存也意味着编译器在分析函数时必须扫描大量内存,这会导致编译器产生大量缓存未命中。B3 有两种中间表示——一种是稍高级的表示,称为B3 IR;另一种是机器级的表示,称为汇编 IR,简称Air。这两种 IR 的目标都是表示低级操作,同时最大限度地减少分析代码所需的高开销内存访问次数。这涉及到四种策略:减少 IR 对象的总体大小,减少表示典型操作所需的 IR 对象数量,减少遍历 IR 时指针追逐的需求,以及减少中间表示的总数。
减小 IR 对象的大小
B3 和 Air 被设计为使用小型对象来描述程序中的操作。B3 通过丢弃可以延迟重新计算的冗余信息来减小 IR 对象的大小。Air 则更具侵略性,通过精心调整所有对象的布局来减小对象大小,即使这意味着使 IR 稍难操作。
B3 IR 使用SSA(静态单赋值),这意味着每个变量在程序文本中只被赋值一次。这在变量和赋值语句之间创建了一一映射。为了紧凑性,SSA IR 通常使用一个对象来封装为变量赋值的语句和变量本身。这使得 SSA 看起来很像数据流,尽管 B3 并非真正的数据流 IR,因为每个语句都锚定在控制流中的特定位置。
在 B3 中,表示变量及其赋值语句的类是 Value。每个值都属于某个基本块。每个基本块包含一系列要执行的值。每个值都将有一个指向其他值的引用列表(在 B3 术语中我们称之为子项),这些引用代表输入以及该操作码所需的任何元数据。
让子边成为双向边是很吸引人的。这样,查找任何值的所有用途都将非常便宜。如果你想用另一个值替换某个值,这将非常有用——这是一个非常常见的操作,以至于 LLVM 使用了“RAUW”(Replace All Uses With,替换所有用途)这个缩写,并在其词典中对其进行了定义。但是双向边代价昂贵。边本身必须表示为一个对象,其中包含指向子项和父项(或子项的使用者)的指针。子值列表变成一个 Use 对象数组。这是 B3 IR 避免内存使用的一个例子。在 B3 中,你无法通过一个独立的原子操作替换一个值的所有用途,因为值不知道它们的父项。这为每个值节省了大量内存,并使读取整个 IR 的成本大大降低。B3 优化不使用“替换所有用途”,而是使用Value::replaceWithIdentity()方法将值替换为标识。标识是一个只有一个子项并仅返回该子项的值。这最终是很经济的。我们可以原地将一个值更改为 Identity 值。大多数执行此类替换的转换已经遍历了整个函数,或者说在 B3 术语中是Procedure。因此,我们只需安排对现有过程的遍历也调用Value::performSubstitution(),该方法将 Identity 的所有用途替换为 Identity 子项的用途。这让我们两全其美:B3 阶段变得更快,因为处理一个值所需的内存访问更少;而且这些阶段不会因为无法“替换所有用途”而增加任何渐近复杂性,因为这项工作只是融入到它们已经进行的现有处理中。
Air 在减小大小方面采取了更极端的方法。Air 中的基本操作单元是 Inst。Inst 是按值传递的。尽管 Inst 可以接受可变数量的参数,但它有三个内联容量,这是常见情况。因此,一个基本块通常包含一个单独的连续内存块,完整描述其所有指令。用于表示参数的 Arg 对象完全是就地存储的。它只是一个紧密打包的比特袋,用于描述汇编指令将看到的所有类型的参数。
最小化 IR 对象的数量
最小化表示典型操作所需的内存对象数量也很重要。我们研究了 FTL 中常用的操作。分支到退出基本块很常见。将常量添加到整数、将整数转换为指针并使用该指针进行加载或存储也很常见。在移位前对移位量进行掩码操作很常见。进行带溢出检查的整数运算也很常见。B3 IR 和 Air 在常见情况下使常见操作只使用一个 Value 或 Inst。分支和退出操作不需要多个基本块,因为 B3 将其封装在 Check 操作码中,Air 将其封装在特殊的 Branch 指令中。B3 IR 中的指针只是整数,并且所有加载/存储操作码都接受一个可选的偏移量立即数,因此典型的 FTL 内存访问只需要一个对象。B3 IR 中的算术操作仔细平衡了现代硬件和现代语言的语义。对移位量进行掩码是 C 语义的遗迹,以及关于将 N 位整数移位超过 N 位意味着什么的古老争议;由于 X86 和 ARM 都为您掩码了移位量,并且现代语言都假定移位是这样工作的,因此这些都不再有意义。B3 IR 通过不要求您发出那些无意义的掩码来节省内存。带有溢出检查的数学运算在 B3 中使用 CheckAdd、CheckSub 和 CheckMul 操作码表示,在 Air 中使用 BranchAdd、BranchSub 和 BranchMul 操作码表示。这些操作码都理解慢速路径是优化代码的突然终止。这消除了 JavaScript 程序每次进行数学运算时都需要创建控制流的需求。
减少指针追逐
大多数编译器阶段都必须遍历整个过程。你很少会编写一个只针对单一操作码执行操作的编译器阶段。公共子表达式消除、常量传播和强度削减——最常见的优化类型——都处理 IR 中的几乎所有操作码,因此必须访问过程中的所有值或指令。B3 IR 和 Air 经过优化,通过尽可能使用数组并减少指针追逐的需求,从而减少与此类线性扫描相关的内存瓶颈。如果最常见的操作是读取整个内容,那么数组往往比链表更快。访问数组中相邻的两个值很便宜,因为它们很可能落在同一个缓存行中。这意味着内存延迟只会在每 N 次从数组加载时发生,其中 N 是缓存行大小与值大小的比率。通常,缓存行很大:32 字节,或在 64 位系统上足以容纳 4 个指针,如今这往往是最小值。链表没有这种优势。因此,B3 和 Air 将过程表示为基本块数组,并将每个基本块表示为操作数组。在 B3 中,它是一个指向值对象的指针数组(特别是 WTF::Vector)。在 Air 中,它是一个 Inst 数组。这意味着在遍历基本块的常见情况下,Air 不需要指针追逐。Air 必然在优化访问方面最为极端,因为 Air 级别更低,因此天生会看到更多代码。例如,你可以获得立即数的值、临时寄存器或寄存器的类型,以及每个参数的元属性(它是否读取值?写入值?它访问多少位?它是什么类型?)所有这些都无需读取 Inst 中包含的内容之外的任何信息。
将基本块构造为数组似乎排除了在基本块中间插入操作的可能性。但同样,我们又因大多数转换必须处理整个过程而得救,因为很少会编写只影响操作一小部分的转换。当一个转换希望插入指令时,它会构建一个 InsertionSet(B3 中的实现 和 Air 中的实现),其中列出了应该插入这些值的索引。一旦转换完成一个基本块,它就执行该集合。这是一项线性时间操作,作为基本块大小的函数,它一次性执行所有插入和所有必要的内存重新分配。
减少中间表示的数量
B3 IR 涵盖了我们 LLVM IR 的所有用例,据我们所知,它并没有阻止我们进行 LLVM 会做的任何优化。它在实现这些的同时,使用更少的内存且处理成本更低,从而减少了编译时间。
Air 涵盖了我们 LLVM 低级 IR 的所有用例,例如选择 DAG、机器 SSA 和 MC 层。它在一个紧凑的 IR 中完成了这一切。本节将讨论使 Air 如此简单的一些架构选择。
Air 旨在表示所有指令选择决策的最终结果。虽然 Air 确实提供了足够的信息以供转换,但它并非用于除寄存器分配和调用约定降低等特定类型转换之外的任何操作的有效 IR。因此,将 B3 转换为 Air 的阶段,称为 B3::LowerToAir,必须巧妙地为每个 B3 操作选择正确的 Air 序列。它通过执行逆向贪婪模式匹配来做到这一点。它反向遍历每个基本块。当它看到一个值时,它会尝试遍历该值及其子项,甚至可能是其子项的子项(传递地,多层深度)来构建一个 Inst。与生成的 Inst 匹配的 B3 模式将涉及一个根值和一些仅由根使用并可以作为生成 Inst 的一部分计算的内部值。指令选择器会锁定这些内部值,这可以防止它们发出自己的指令——再次发出它们将是不必要的,因为我们选择的 Inst 已经完成了这些内部值本会做的事情。这就是逆向选择的原因:我们希望在看到值本身之前看到值的使用者,以防只有一个使用者并且该使用者可以将值的计算合并到单个指令中。
指令选择器需要知道哪些 Air 指令可用。这可能因平台而异。Air 提供了一个快速查询 API,用于确定特定指令是否可以在当前目标 CPU 上高效处理。因此,B3 指令选择器会级联遍历所有可能的指令以及与它们匹配的 B3 值模式,直到找到 Air 认可的指令。这非常快,因为 Air 查询通常会折叠成常量。它也相当强大。我们可以融合涉及加载、存储、立即数、地址计算、比较、分支和基本数学运算的模式,以便在 x86 和 ARM 上发出高效指令。这反过来又减少了指令的总数,并减少了我们用于临时变量的寄存器数量,从而减少了对堆栈的访问次数。
B3 优化
B3 IR 和 Air 的设计为我们构建高级优化提供了良好的基础。B3 的优化器已经包含了许多优化
我们还在 Air 中进行了优化,例如死代码消除、控制流图简化,以及针对部分寄存器停顿和溢出代码病理的修复。Air 中最重要的优化是寄存器分配;这将在后面部分详细讨论。
拥有 B3 也为我们提供了灵活性,可以专门针对 FTL 调整我们的任何优化。下一节将详细介绍我们的一些 FTL 特有功能。
为 FTL 调整 B3
B3 包含一些受 FTL 启发的功能。由于 FTL 大量使用自定义调用约定、自修改代码片段和栈上替换,我们知道必须将这些概念作为 B3 中的一流公民。B3 使用 Patchpoint 和 Check 系列操作码来处理这些。我们知道 FTL 在某些情况下会生成大量对同一属性的重复分支,因此我们确保 B3 可以专门化这些路径。最后,我们知道我们需要一个开箱即用且无需大量调优的出色寄存器分配器。我们的寄存器分配策略与 LLVM 显著不同。因此,我们有一个部分专门描述了我们的思考。
B3 补丁点
FTL 大量使用自定义调用约定、自修改代码片段和栈上替换。尽管 LLVM 确实支持这些功能,但它将它们视为实验性内置函数,从而限制了优化。我们从头开始设计 B3 来支持这些概念,因此它们获得了与任何其他操作相同的处理。
LLVM 使用补丁点(patchpoint)内置函数来支持这些功能。它允许 LLVM 的客户端发出自定义机器代码,以实现 LLVM 模拟为调用的操作。B3 通过原生 Patchpoint 操作码支持这些功能。B3 对补丁的原生支持提供了重要的优化
- 可以将任意参数固定到任意寄存器或栈槽。也可以请求一个参数获得任意寄存器,或者使用对编译器最方便的方式(寄存器、栈槽或常量)表示它。
- 还可以约束结果的返回方式。可以将结果固定到任意寄存器或栈槽。
- 补丁点不需要有预定的机器码大小,这消除了用空操作填充补丁点内部代码的需要。LLVM 的补丁点需要预定的机器码大小。LLVM 的后端会发出那么多字节的空操作来代替补丁点,并向客户端报告这些空操作的位置。B3 的补丁点允许客户端与自己的代码生成器协同生成代码,从而消除了对空操作和预定大小的需求。
- B3 的补丁点可以提供关于副作用的详细信息,例如补丁点是否可以读写内存、是否会导致突然终止等。如果补丁点确实读写内存,则可以使用 B3 用来限制加载、存储和调用副作用的相同别名语言,来提供对所访问内存的边界约束。LLVM 有一种用于描述堆抽象区域的语言(称为TBAA),但你不能用它来描述补丁点读写内存的边界。
补丁点可用于生成任意复杂的、可能自修改的代码片段。其他 WebKit JIT 可以访问大量用于生成稍后将进行补丁的代码的实用工具。这通过我们内部的 MacroAssembler API 暴露。创建补丁点时,你提供一个 C++ lambda 形式的代码生成回调,该补丁点会携带它。一旦 Air 发出补丁点,就会调用该 lambda。它会获得一个 MacroAssembler 引用(具体来说,是一个 CCallHelpers 引用,它用一些更高级别的实用工具增强了汇编器)以及一个描述补丁点在 B3 中的高级操作数与机器位置(如寄存器和栈槽)之间映射的对象。这个对象,称为 StackmapGenerationParams,还提供了关于代码生成状态的其他数据,例如已使用的寄存器集合。B3 与补丁点生成器之间的契约是:
- 生成器必须生成突然终止或直接通过的代码。它不能跳转到 B3 发出的其他代码。例如,一个补丁点跳转到另一个补丁点是错误的。
- 补丁点必须使用
Effects对象考虑生成器可能产生的各种副作用。例如,补丁点不能在未在副作用中注明的情况下访问内存或突然终止。任何补丁点的默认副作用都声称它可以访问任何内存并可能突然终止。 - 补丁点不能破坏 StackmapGenerationParams 声称正在使用的任何寄存器。也就是说,补丁点可以使用它们,但必须在使用前保存它们,并在通过前恢复它们。补丁点可以请求任意数量的临时 GPR 和 FPR,因此无需争抢寄存器。
由于 B3 补丁点从不需要预设机器码片段的大小,因此它们比 LLVM 的补丁点更经济,并且可以更广泛地使用。由于 B3 使得请求临时寄存器成为可能,FTL 在其补丁点发出的代码中溢出寄存器的可能性更小。
以下是 B3 客户端如何发出补丁点的示例。这是动态语言中一种经典的补丁点:它从内存中以一个偏移量加载一个值,该偏移量可以在编译器完成后进行修补。这个例子说明了将可修补代码引入 B3 过程是多么自然。
// Emit a load from basePtr at an offset that can be patched after the
// compiler is done. Returns a box that holds the location in machine code of
// that patchable offset and the value that was loaded.
std::pair<Box<CodeLocationDataLabel32>, Value*>
emitPatchableLoad(Value* basePtr) {
// Create a patchpoint that returns Int32 and takes basePtr as its
// argument. Using SomeRegister means that the value of basePtr will be in
// some register chosen by the register allocator.
PatchpointValue* patchpoint =
block->appendNew<PatchpointValue>(procedure, Int32, Origin());
patchpoint->appendSomeRegister(basePtr);
// A box is a reference-counted memory location. It will hold the location
// of the offset immediate in memory once all compiling is done.
auto offsetPtr = Box<CodeLocationDataLabel32>::create();
// The generator is where the magic happens. It's a lambda that will run
// during final code generation from Air to machine code.
patchpoint->setGenerator(
[=] (CCallHelpers& jit, const StackmapGenerationParams& params) {
// The 'jit' will let us emit code inline with the code that Air
// is generating. The 'params' give us the register used for the
// result (params[0]) and the register used for the basePtr
// (params[1]). This emits a load instruction with a patchable
// 32-bit offset. The 'offsetLabel' is the offset of that
// immediate in the current assembly buffer.
CCallHelpers::DataLabel32 offsetLabel =
jit.load32WithAddressOffsetPatch(
CCallHelpers::Address(params[1].gpr()), params[0].gpr());
// We can add a link task to populate the 'offsetPtr' box at the
// very end.
jit.addLinkTask(
[=] (LinkBuffer& linkBuffer) {
// At link time, we can get the absolute address of the
// label, since at this point we've moved the machine
// code into its final resting place in executable memory.
*offsetPtr = linkBuffer.locationOf(offsetLabel);
});
});
// Tell the compiler about the things we won't do. By default it assumes
// the worst. But, we know that this won't write to memory and we know
// that this will never return or trap.
patchpoint->effects.writes = HeapRange();
patchpoint->effects.exitsSideways = false;
// Return the offset box and the patchpoint, since the patchpoint value
// is the result of the load.
return std::make_pair(offsetPtr, patchpoint);
}
补丁点只是 B3 动态语言支持的一半。另一半是 Check 系列操作码,用于实现栈上替换(OSR)。
B3 中的 OSR
JavaScript 是一种动态语言。它不具备能够本地快速执行的类型和操作。FTL JIT 通过推测它们的行为,将这些操作转换为快速代码。推测意味着如果遇到某些不期望的条件,就从 FTL JIT 代码中退出。这确保了后续代码不必再次检查此条件。推测使用 OSR 来处理从 FTL JIT 退出。OSR 包含两种策略
- 安排运行时将函数的所有未来执行切换到由非优化(即基线)JIT 编译的版本。当运行时检测到 FTL JIT 未预期的某些条件出现,从而优化代码不再有效时,就会发生这种情况。WebKit 通过重写所有调用链接数据结构以指向基线入口点来做到这一点。如果函数当前在栈上,WebKit 会涂写优化函数内部的所有失效点。失效点在生成的代码中是不可见的——它们只是可以安全地用跳转到 OSR 处理程序的机器代码覆盖的位置,OSR 处理程序会弄清楚如何重塑栈帧使其看起来像基线栈帧,然后跳转到基线代码中的适当位置。
- 发出执行某些检查的代码,并在检查失败时跳转到 OSR 处理程序。这使得后续代码可以假定不需要重复检查。例如,FTL 推测整数运算不会溢出,这使其能够使用整数来表示许多 JavaScript 数字,这些数字在语义上行为类似双精度浮点数。FTL JIT 还发出许多推测性类型检查,例如快速检查一个值是否真的是具有某些字段的对象,或者检查一个值是否真的是整数。
失效点可以使用 Patchpoint 实现。补丁点的生成器除了警告我们的 MacroAssembler 我们想要一个稍后可能涂写跳转的标签外,不发出任何代码。我们的 MacroAssembler 长期以来一直支持这一点。它只会在该标签处发出一个跳转大小的空操作,前提是该标签离其他控制流太近。只要没有其他控制流,就不会发出任何内容。补丁点会获取 OSR 处理程序所需的所有活跃状态。当 OSR 处理程序运行时,它会查询 StackmapGenerationParams 留下的数据,以确定哪些寄存器或栈位置包含状态的哪些部分。请注意,这可能发生在 B3 完成编译很久之后,这就是 B3 将此数据表示为称为 B3::ValueRep 的按值对象的原因。这与我们在 LLVM 中所做的没有区别,尽管由于 LLVM 没有使用我们的 MacroAssembler 发出指令,我们不得不使用单独的机制来警告我们要用跳转进行重新修补。
对于涉及显式检查的 OSR,Patchpoint 操作码虽然足够,但不一定高效。在 LLVM 中,我们将每个 OSR 退出建模为一个基本块,该基本块调用一个补丁点并将所有活跃状态作为参数传递。这要求将每个推测性检查表示为
- 对正在检查的谓词进行分支。
- 一个基本块,用于表示检查成功后要执行的代码。
- 一个基本块,用于表示 OSR 退出。此基本块包含一个补丁点,该补丁点将其参数作为重建基线栈帧所需的所有状态。
这准确地表示了推测的含义,但它是通过打破基本块来实现的。每次检查都会将其基本块分成两部分,然后为退出引入另一个基本块。这不仅增加了编译时间。它还削弱了任何在控制流附近变得保守的优化。我们发现这影响了 LLVM 中的许多方面,包括指令选择和死存储消除。
B3 旨在处理 OSR 而不破坏基本块。我们使用 Check 操作码来实现这一点。Check 就像是 Branch 和 Patchpoint 的结合。像 Branch 一样,它接受一个谓词作为输入。就像对 Branch 所做的那样,指令选择器支持 Check 的比较/分支融合。像 Patchpoint 一样,Check 也接受额外的状态和一个生成器。Check 不是基本块的终结符。它封装了对谓词的分支,在谓词为真时发出 OSR 退出处理程序,并在谓词为假时继续执行下一条指令。传递给 Check 的生成器在与 Check 分支链接的内联外路径上发出代码。它不允许直接通过或跳回 B3 代码。B3 可以假定通过 Check 证明谓词为假。
我们发现 Check 是一项重要的优化。它极大地减少了表示推测操作所需的控制流数量。与 LLVM 一样,B3 也有一些在实际控制流附近变得保守的优化,但它们对 Check 的处理非常出色。
尾部复制
FTL 生成的代码通常对同一属性有许多重复分支。这些可以通过跳转线程和尾部复制等优化来消除。尾部复制功能更强大一些,因为它允许在编译器意识到该特化会揭示哪些优化之前,就进行有限的代码特化。LLVM 直到后端才进行尾部复制,因此错过了许多它本可以揭示的高级优化机会。B3 具有尾部复制功能,添加此优化使 Octane 几何平均分数提高了 2% 以上。LLVM 过去曾有尾部复制功能,但在2011 年被移除。当时关于其移除的讨论似乎表明它对编译时间产生了不利影响,并且对 clang 来说无利可图。我们也发现它对编译时间造成了一点影响——但与 clang 不同,我们看到了整体速度提升。如果对我们跟踪的基准测试来说是净收益,我们乐于牺牲一些编译时间。这是我们可以在 B3 中自由进行的网络特定调整的一个例子。
寄存器分配
寄存器分配仍然是计算机科学中一个蓬勃发展的研究领域。LLVM 在过去五年中彻底改革了其寄存器分配器。GCC 在八年前彻底改革了其分配器,目前仍在进行另一次彻底改革。
B3 在 Air 上进行寄存器分配。Air 类似于汇编代码,但它允许在目标处理器允许寄存器的任何地方使用临时变量。然后,寄存器分配器的任务是转换程序,使其引用寄存器和溢出槽而不是临时变量。后续阶段将溢出槽转换为具体的栈地址。
选择寄存器分配器很困难。LLVM 和 GCC 的历史似乎表明,编译器最初选择的寄存器分配器很少是最终选择。我们决定使用经典的图着色寄存器分配器,称为迭代寄存器合并(Iterated Register Coalescing),简称 IRC。这个算法非常简洁,我们过去有实现和调优它的经验。其他分配器,例如 LLVM 和 GCC 中使用的那些,没有如此详细的文档,因此集成到 Air 中会花费更长的时间。我们的初始实现直接将 IRC 论文中的伪代码转化为实际代码。我们当前的性能结果显示 LLVM 和 B3 生成的代码质量没有显著差异,这似乎意味着这个寄存器分配器与 LLVM 的 Greedy 寄存器分配器做得一样好。除了添加一个非常基本的修复阶段并调整实现以减少对哈希表的依赖之外,我们没有改变算法。我们喜欢 IRC 使建模在补丁点和疯狂的 X86 指令中遇到的寄存器约束变得容易,并且 IRC 通过合并变量来消除无意义的变量赋值是一个很棒的智能解决方案。IRC 也足够快,它不会阻止我们实现相对于 LLVM 将编译时间减少一个数量级的目标。本文末尾的性能评估部分将更详细地介绍我们的 IRC 实现与 LLVM 的 Greedy 寄存器分配器之间的权衡。请在此处查看我们的 IRC 实现。
我们计划重新审视寄存器分配器的选择。我们应该选择在实际网络工作负载上性能最佳的寄存器分配器。根据我们目前的性能结果,我们有一个未解决的 bug,关于在 Air 中尝试 LLVM 的 Greedy 寄存器分配器。
B3 设计总结
B3 旨在实现我们之前从 LLVM 获得的同类优化,同时以更短的时间生成代码。它还支持 FTL JIT 特定的优化,例如对自修改代码效果的精确建模。下一节将描述 B3 如何融入 FTL JIT。
将 B3 JIT 融入 FTL JIT
FTL JIT 已经被设计为对其后端的中间表示进行抽象。我们这样做是因为 LLVM 的 C API 过于冗长,并且对于 FTL 认为应该是一条指令的操作(例如从指针和偏移量加载值)通常需要许多指令。使用我们的抽象意味着我们可以使其更简洁。这种相同的抽象使我们能够“替换”B3 JIT,而无需重写整个 FTL JIT。
对 FTL JIT 的大部分更改都以有益的重构形式进行,利用了 B3 的补丁点。LLVM 补丁点要求 FTL 拦截 LLVM 的内存分配,以便获取一个指向名为“stackmap”的内存块的指针。获取该内存块的方式因平台而异,因为 LLVM 会将其节命名策略与平台使用的动态链接器相匹配。然后 FTL 必须解析二进制 stackmap 内存块,以生成 B3 所谓的 StackmapGenerationParams 的对象导向描述:每个补丁点处正在使用的寄存器列表、高级操作数到寄存器的映射,以及发出每个补丁点机器码所需的信息。我们本可以围绕 B3 编写一个层,使用 B3 Patchpoints 生成类似 LLVM 的 stackmap,但我们选择重写 FTL 中使用补丁点的那些部分。使用 B3 的补丁点要容易得多。例如,以下是使用补丁点发出双精度浮点数到整数指令所需的全部代码。B3 不原生支持它,因为此类指令的具体行为在不同目标之间差异很大。
LValue Output::doubleToInt(LValue value)
{
PatchpointValue* result = patchpoint(Int32);
result->append(value, ValueRep::SomeRegister);
result->setGenerator(
[] (CCallHelpers& jit, const StackmapGenerationParams& params) {
jit.truncateDoubleToInt32(params[1].fpr(), params[0].gpr());
});
result->effects = Effects::none();
return result;
}
请注意,查询用于输入(params[1].fpr())和用于输出(params[0].gpr())的寄存器是多么容易。大多数补丁点都比这个复杂得多,因此拥有清晰的 API 使这些补丁点更容易管理。
性能结果
在撰写本文时,仍然可以通过编译时标志在 LLVM 和 B3 之间切换。这使得 LLVM 和 B3 可以进行直接对比。本节总结了在两台机器上使用三个基准测试套件进行的性能测试结果。
我们在两台不同的 Mac 上进行了测试:一台是老款 Mac Pro,配备 12 个超线程核心(两个 6 核 Xeon)和 32 GB 内存;另一台是稍新的 MacBook Air,配备 1.3 GHz Core i5 和 8 GB 内存。Mac Pro 有 24 个逻辑 CPU,而 MacBook Air 只有 4 个。测试不同类型的机器很重要,因为可用 CPU 的数量、内存的相对速度以及特定 CPU 型号擅长的任务都会影响最终结果。我们曾看到 WebKit 的更改在一类机器上提高了性能,而在另一类机器上却导致性能下降。
我们使用了三个不同的基准测试套件:JetStream、Octane 和 Kraken。JetStream 和 Kraken 没有重叠,测试不同类型的代码。Kraken 有大量的数值代码,运行时间相对较短——这是 JetStream 所缺乏的。Octane 测试与 JetStream 类似,但侧重点不同。我们认为 WebKit 应该在所有基准测试中表现良好,因此我们始终使用广泛的基准测试作为我们实验方法的一部分。
所有测试都在 WebKit 的相同修订版 r195946 中将 LLVM 与 B3 进行比较。测试在浏览器中运行,以使其尽可能真实。
JetStream 中的编译时间
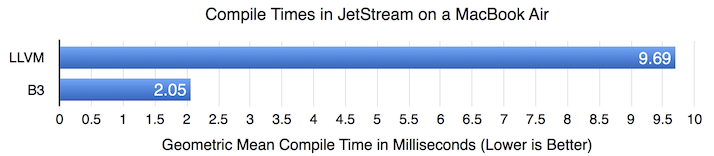
我们对 B3 的假设是,我们可以构建一个减少编译时间的编译器,这将使 FTL JIT 能够惠及更广泛的应用程序。上图显示了 JetStream 中热函数的几何平均编译时间。LLVM 的编译时间比 B3 长 4.7 倍。虽然这与我们最初设想的将编译时间减少 10 倍的目标有所差距,但这仍然是一个巨大的改进。接下来的部分将展示这种编译时间缩减与 B3 整体良好的代码生成质量如何结合,从而在 JetStream 和其他基准测试中产生速度提升。
JetStream 性能
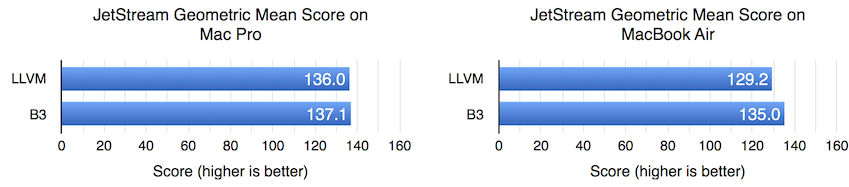
在 Mac Pro 上,LLVM 和 B3 之间的性能几乎没有差异。但在 MacBook Air 上,B3 提供了 4.5% 的整体速度提升。我们可以根据 JetStream 的延迟和吞吐量组件进一步细分。本节还探讨了寄存器分配性能,并考虑了 JetStream 在各种 LLVM 配置下的性能。
JetStream 延迟

JetStream 的延迟组件包含许多运行时间较短的测试。一个耗时过长的 JIT 编译器会从多个方面影响延迟分数
- 它延迟了优化代码的可用性,导致程序花费额外时间运行慢速代码。
- 它给内存总线带来压力,并减慢了运行基准测试的线程上的内存访问速度。
- 编译器线程并非完全并发。它们有时可能与主线程调度在同一 CPU 上。它们有时可能获取锁,导致主线程阻塞。
B3 似乎改善了 Mac Pro 和 MacBook Air 上的 JetStream 延迟分数,尽管对 MacBook Air 的影响要大得多。
JetStream 吞吐量
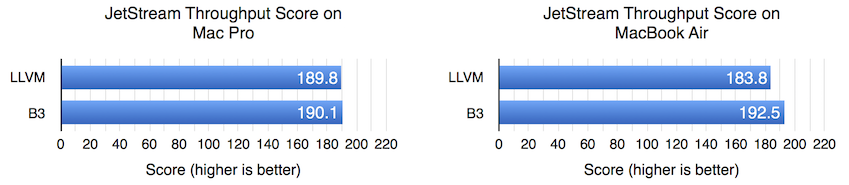
JetStream 的吞吐量测试运行时间足够长,因此编译它们所需的时间应该无关紧要。但就测试提供预热周期而言,持续时间是固定的,与硬件无关。因此,在较慢的硬件上,我们预计并非所有热代码都能在预热周期完成时编译完成。
在 Mac Pro 上,无论我们选择哪个后端,吞吐量分数似乎都相同。但在 MacBook Air 上,B3 显示出 4.7% 的优势。
Mac Pro 的性能结果似乎暗示 LLVM 和 B3 生成的代码质量大致相当,但我们无法确定。虽然可能性不大,但 B3 有可能在稳态性能方面造成 X% 的减速,而由于编译器延迟的减少,又获得了 X% 的加速,两者恰好相互抵消。我们认为更可能的是 LLVM 和 B3 生成的代码质量大致相当。
我们怀疑在 MacBook Air 上,编译时间非常重要。由于许多 JetStream 测试都有一个 1 秒的预热期,期间不记录性能,因此足够快的计算机(如 Mac Pro)将能够完全隐藏编译时间的影响。只要所有相关编译在一秒内完成,没有人会知道是花了一整秒还是只花了一小部分时间。但在足够慢的计算机上,或者像 MacBook Air 或 iPhone 这样没有 24 个逻辑 CPU 的计算机上,热函数的编译可能在 1 秒预热后仍在进行。此时,编译所花费的每一刻都会从分数中扣除,因为在主线程上运行较慢的代码以及必须与编译器线程竞争内存带宽的复合效应。编译时间减少 4.7 倍,再加上 MacBook Air 的低并行度,可能解释了为什么它能从 B3 中获得 JetStream 吞吐量加速,即使在 Mac Pro 上分数相同。
JetStream 中的寄存器分配性能
我们的吞吐量结果似乎表明,B3 和 LLVM 寄存器分配器生成的代码质量没有显著差异。这引出了一个问题:哪个寄存器分配器最快?我们测量了 JetStream 中寄存器分配所花费的时间。就像我们对编译时间所做的那样,我们关联了 JetStream 所有热函数中的寄存器分配时间,并计算了 LLVM 的 Greedy 寄存器分配器与 B3 的 IRC 所花费时间比率的几何平均值。
LLVM 和 B3 都拥有昂贵的寄存器分配器,但 LLVM 的 Greedy 寄存器分配器平均运行速度更快——在 MacBook Air 上,LLVM 时间与 B3 时间的比率约为 0.6。这不足以弥补 LLVM 在其他方面的性能不足,但它确实表明我们应该在 WebKit 中实现 LLVM 的 Greedy 分配器,看看是否能带来速度提升。我们也可能会继续调整我们的 IRC 分配器,因为仍然有许多改进可以进行,例如移除哈希表的剩余使用,并切换到更好的数据结构来表示干扰。
这些结果表明,IRC 对于新编译器来说仍然是一个不错的选择,因为它易于实现,不需要大量调优,并且能提供令人满意的性能结果。值得注意的是,IRC 大约有 1300 行代码,而如果考虑到分配器本身(超过 2000 行)及其支持数据结构的代码,LLVM 的 Greedy 则接近 5000 行。
与 LLVM 快速指令选择器的比较
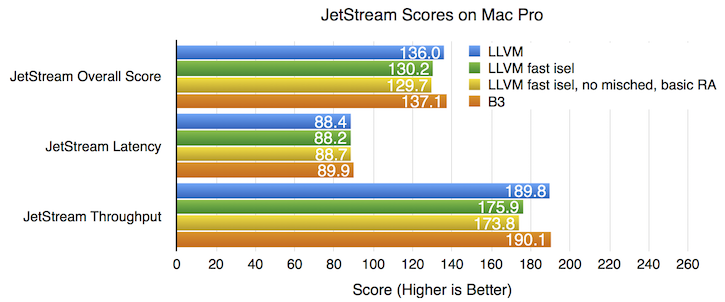
我们对 JetStream 的最终比较考虑了 FTL JIT 在“快速指令选择(fast isel)”配置下运行 LLVM 的能力,我们在 ARM64 上使用此配置。此配置通过禁用一些 LLVM 优化来减少编译时间
- 使用快速指令选择器代替选择 DAG 指令选择器。当我们切换到快速指令选择时,我们也会始终启用 LowerSwitch 阶段,因为快速指令选择无法处理 switch 语句。
- misched 阶段被禁用。
- 使用基本寄存器分配器代替 Greedy 寄存器分配器。
我们测试了仅切换到快速指令选择,以及切换到快速指令选择并同时进行另外两项更改。如上图所示,使用快速指令选择会损害吞吐量:JetStream 吞吐量分数下降 7.9%,导致总分下降 4.5%。同时禁用其他优化似乎会进一步损害吞吐量:吞吐量分数下降 9.1%,总分下降 4.9%,尽管这些差异接近误差范围。B3 能够在不损害性能的情况下减少编译时间:在这台机器上,B3 和 LLVM 的吞吐量分数非常接近,难以判断优劣。
Kraken 性能
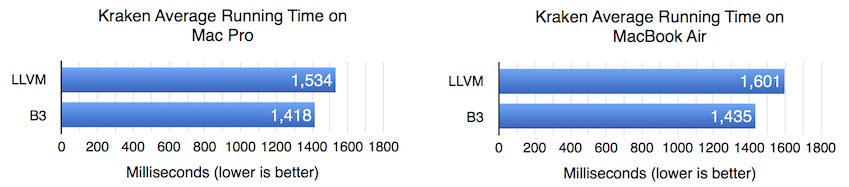
Kraken 基准测试对 FTL JIT 来说一直是个挑战,因为它的测试运行时间相对较短,但却包含了大量需要 WebKit 仅在 FTL JIT 中才能进行的优化类型的代码。事实上,我们在最初考虑开发 B3 时就想到了 Kraken。因此,B3 提供了速度提升并不令人意外:在 Mac Pro 上提升 8.2%,在 MacBook Air 上提升 11.6%。
Octane 性能
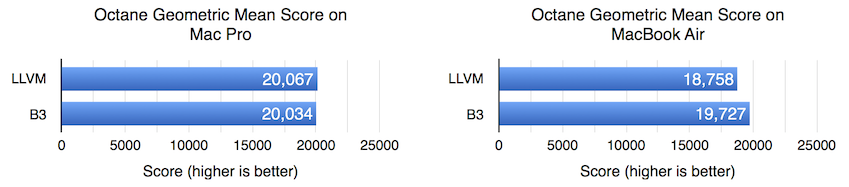
Octane 与 JetStream 有很多重叠:JetStream 吞吐量组件的大约一半来自 Octane。Octane 的结果在 Mac Pro 上没有差异,在 MacBook Air 上 B3 提速 5.2%,这与我们在 JetStream 吞吐量中看到的结果相似。
结论
B3 在我们测试的基准上生成了与 LLVM 同样出色的代码,并通过减少编译时间使 WebKit 整体运行更快。我们很高兴在 FTL JIT 中启用了新的 B3 编译器。拥有我们自己的低级编译器后端使我们在某些基准测试上获得了即时提升。我们希望未来它能让我们更好地为 Web 调整我们的编译器基础设施。
B3 尚未完全成熟。我们仍需完成 B3 到 ARM64 的移植。B3 通过了所有测试,但我们尚未完成在 ARM 上的性能优化。一旦所有使用 FTL 的平台都切换到 B3,我们计划从 FTL JIT 中移除 LLVM 支持。
如果您对 B3 的更多信息感兴趣,我们计划维护最新的文档——每个改变 B3 工作方式的提交都必须相应地更改文档。文档侧重于B3 IR,我们希望尽快添加Air 文档。