JavaScriptCore 中的推测
本文旨在探讨 JavaScriptCore 虚拟机环境下的推测性编译,简称推测。推测性编译是提高动态语言或任何具有足够动态特性的语言运行速度的理想方法。在本文中,我们将研究 JavaScript 的推测。历史上,这种技术或与其密切相关的变体已成功应用于 Smalltalk、Self、Java、.NET、Python 和 Ruby 等语言。从 90 年代开始,许多 Java 实现之间激烈的基准测试驱动竞争,有助于形成一套关于如何为动态性较小的语言构建推测性编译器的理解。尽管 JavaScript 比 Java 动态得多,但本世纪初开始的 JavaScript 性能大战通常倾向于越来越激进地应用对 Java 非常有效的相同推测性编译技巧。看起来推测可以应用于任何使用运行时检查且难以进行静态推理的语言实现。
这是一篇旨在揭示复杂主题的长文。它基于一个两小时的编译器讲座(幻灯片也可提供 PDF 版本)。我们假定读者对编译器概念(如中间表示,尤其是静态单赋值形式,简称 SSA)、静态分析和代码生成有所了解。目标读者是任何希望更好理解 JavaScriptCore 的人,或任何考虑使用这些技术来加速其自身语言实现的人。本文中描述的大多数概念并非 JavaScript 独有,本文也不假定读者预先了解 JavaScriptCore。
在深入探讨推测的细节之前,我们将概述推测和 JavaScriptCore。这将为本文的主要部分提供背景,该部分通过将推测分解为五个部分来描述:字节码(通用 IR)、控制、性能分析、编译和 OSR(栈上替换)。最后,我们将对相关工作进行简要回顾。
推测概述
推测背后的直觉是利用传统编译器技术,使动态语言尽可能快地运行。构建高性能编译器是一门成熟的艺术,因此我们希望尽可能多地重用这方面的成果。但对于像 JavaScript 这样的语言,我们无法直接做到这一点,因为缺乏类型信息意味着编译器无法对任何基本操作(甚至是 + 或 == 等)进行有意义的优化。推测性编译器使用性能分析来动态推断类型。生成的代码使用动态类型检查来验证分析出的类型。如果程序使用的类型与我们分析的不同,我们将丢弃优化后的代码并重新尝试。这使得优化编译器能够处理动态类型程序的静态类型表示。
尽管我们描述的技术是用于实现动态类型语言的,但类型是本文的一个主要主题。当语言包含静态类型时,它可以为程序员提供安全属性,或帮助优化编译器发挥作用。我们只关注类型对性能的影响,JavaScriptCore 中的推测策略可以广义地理解为推断 C 程序可能拥有的类型,但使用的是专为我们的优化编译器构建的内部类型系统。更一般地说,本文中描述的技术可以用于启用任何类型的配置文件引导优化,包括与类型无关的优化。但本文和 JavaScriptCore 都侧重于那种最自然地被视为与类型相关的性能分析和推测(例如变量是否是整数,指针指向的对象形状,操作是否有副作用等)。
为了更深入地探讨这一点,我们首先考虑类型的影响。然后我们看看推测如何为我们提供类型。
类型的影响
我们希望为动态类型语言提供一种优化编译器流水线,这种流水线通常存在于高性能静态类型语言(如 C 语言)的预编译(ahead-of-time)编译器中。这种优化器的输入通常是某种内部表示(IR),它能精确地说明每个操作的类型,或者至少是一种可以从中推断出每个操作类型的表示。
为了理解类型的影响以及推测性编译器如何处理它们,请考虑以下 C 函数
int foo(int a, int b)
{
return a + b;
}
在 C 语言中,int 等类型用于描述变量、参数、返回值等。在优化编译器有机会处理上述函数之前,类型检查器会填补空白,以便 + 操作将使用一个 IR 指令来表示,该指令知道它正在添加 32 位有符号整数(即 int)。这种知识至关重要
- 类型信息告诉编译器的代码生成器如何为该指令发出代码。由于
int类型,我们知道要使用整数加法指令(而不是浮点加法或其他)。 - 类型信息告诉优化器如何为输入和输出分配寄存器。整数意味着使用通用寄存器。浮点数意味着使用浮点寄存器。
- 类型信息告诉优化器该指令可能有哪些优化。精确了解其作用使我们能够知道可以用哪些其他操作来代替它,允许我们对程序正在进行的数学运算进行一些代数推理,并允许我们在输入为常量时将指令折叠为常量。如果存在
+具有副作用的类型(例如在 C++ 中),那么这是整数+的事实意味着它是纯的。许多适用于+的编译器优化如果它不是纯的就无法工作。
现在考虑用 JavaScript 编写的相同程序
function foo(a, b)
{
return a + b;
}
我们不再拥有类型的奢侈。程序没有告诉我们 a 或 b 的类型。类型检查器无法将 + 操作标记为任何特定的东西。它可以根据 a 和 b 的运行时类型执行许多不同的操作
- 它可能是一个 32 位整数加法。
- 它可能是一个浮点数加法。
- 它可能是一个字符串连接。
- 它可能是一个带有方法调用的循环。这些方法可以是用户定义的,并可能执行任意副作用。如果
a或b是对象,就会发生这种情况。

Branch 操作类似于 if,并且具有条件为真/假结果的出边。基于此,优化器不可能知道该做什么。指令选择意味着要么为整个操作发出一个函数调用,要么发出一个昂贵的控制流子图来处理所有各种情况(图 1)。我们不知道哪种寄存器文件最适合输入或结果;我们可能会选择通用寄存器,然后执行额外的移动指令,以便在必须进行浮点加法时将数据放入浮点寄存器。不可能知道一个加法是否会产生与另一个相同的结果,因为它们有带有副作用方法调用的循环。每当 + 操作发生时,我们都必须考虑到整个堆可能已被修改的可能性。
简而言之,除非我们能以某种方式为所有值和操作提供类型,否则将优化编译器用于 JavaScript 是不切实际的。为了使这些类型有用,它们需要帮助我们避免诸如 + 这样的基本操作看起来需要控制流或副作用。它们还需要帮助我们理解要使用哪些指令或寄存器文件。推测性编译器通过将这种推理应用于语言中的所有动态操作来提高速度——从表示为基本操作(如 + 或内存访问,如 o.f 和 o[i])到涉及内部函数或可识别代码模式(如调用 Function.prototype.apply)的操作。
推测类型
本文重点关注那些收集到的信息最自然地被理解为类型信息的推测,例如变量是否是整数以及被指向对象具有哪些属性(以及顺序)。让我们更深入地理解这方面的两个方面:性能分析和优化何时以及如何发生,以及推测类型意味着什么。

让我们思考一下 JavaScript 的推测性编译的含义。JavaScript 实现假装是解释器;它们接受 JS 源代码作为输入。但在内部,这些实现结合使用了解释器和编译器。最初,代码在不进行任何推测性基于类型的优化但会收集类型性能分析的执行引擎中运行。这通常是解释器,但并非总是如此。一旦一个函数拥有足够令人满意的性能分析数据,引擎就会为该函数启动一个优化编译器。优化编译器基于与 C 编译器中相同的基本原理,但它不是从类型检查器接收类型并作为命令行工具运行,而是从性能分析器接收类型,并在与它正在编译的程序相同的进程中运行在一个线程中。一旦该编译器完成优化机器代码的发出,我们就会将该函数的执行从性能分析层切换到优化层。运行中的 JavaScript 代码无法观察到这一切的发生,除非它测量执行时间。(然而,我们用于测试 JavaScriptCore 的环境包含许多用于内省已编译内容的钩子。)图 2 说明了 JavaScript 运行时性能分析和优化如何以及何时发生。
大致来说,推测性编译意味着我们的示例函数将被转换为类似以下的形式
function foo(a, b)
{
speculate(isInt32(a));
speculate(isInt32(b));
return a + b;
}
棘手之处在于推测到底意味着什么。一个简单的选择是我们称之为钻石推测。这意味着每次我们执行一个操作时,我们都会有一个根据性能分析器告诉我们的信息而专门化的快速路径,以及一个处理通用情况的慢速路径
if (is int)
int add
else
Call(slow path)
为了了解其运作方式,我们来看一个略有不同的例子
var tmp1 = x + 42;
... // things
var tmp2 = x + 100;
在这里,我们两次使用 x,两次都将其添加到一个已知整数。假设性能分析器告诉我们 x 是一个整数,但我们无法静态证明这一点。我们还假设 x 的值在两次使用之间没有改变,并且我们已经静态证明了这一点。

x 为整数的钻石推测。图 3 展示了如果我们使用钻石推测来推测 x 是一个整数时会发生什么:我们得到一条执行整数加法的快速路径,以及一条回退到辅助函数的慢速路径。这样的推测能以适度的成本产生适度的加速。成本之所以适度,是因为如果推测错误,只有对 x 的操作会付出代价。这种方法的麻烦在于,重复使用 x 时必须重新检查它是否是整数。重新检查是必要的,因为在things块和more things块都发生了控制流合并。
解决这个问题的原始解决方案是拆分,即程序中things和more things之间的区域会被复制以避免分支。这种方法的一个极端版本是跟踪,其中函数在任何分支之后的所有剩余部分都会被复制。这些技术的麻烦在于复制代码开销很大。我们希望最小化同一段代码被编译的次数,以便能够快速编译大量代码。JavaScriptCore 最接近拆分的操作是尾部复制,如果代码很小,它通过复制钻石推测之间的代码来优化它们。
优于钻石推测或拆分的替代方案是 OSR(栈上替换)。使用 OSR 时,失败的类型检查会从优化函数中退出,回到非优化代码中的等效点(即性能分析层的函数版本)。

x 为整数的 OSR 推测。图 4 展示了当我们使用 OSR 推测 x 是一个整数时会发生什么。由于 x 是整数和不是整数的情况之间没有控制流合并,第二次检查变得冗余并可以消除。缺乏合并意味着到达第二次检查的唯一方式是第一次检查通过。
OSR 推测赋予了我们的传统优化编译器静态类型。在任何基于 OSR 的类型检查之后,编译器可以假定所检查的属性现在是事实。此外,由于 OSR 检查失败不影响语义(我们退出到相同代码的相同点,只是优化更少),我们可以将这些检查提升到我们想要的任意高位置,并且只需通过用相应的类型检查来守护所有对其的赋值,就可以推断出变量总是具有某种类型。
请注意,本文和 JavaScriptCore 中我们所称的OSR 退出,在其他地方通常被称为去优化。我们更倾向于在代码库中使用OSR 退出这个术语,因为它强调了通过一种特殊技术(OSR)退出优化函数这一点。而去优化这个术语听起来像是我们在撤销优化,这仅在特定执行从优化代码跳转到未优化代码这一狭义上是正确的。本文中我们将沿用 JavaScriptCore 的术语。
JavaScriptCore 根据我们对推测正确性的信心程度,使用 OSR 或钻石推测。OSR 推测具有更高的收益和更高的成本:收益更高是因为可以消除重复检查,但成本也更高,因为 OSR 比调用辅助函数更昂贵。然而,只有在实际发生退出时才需要支付成本。OSR 推测的优势如此显著,因此我们将其作为主要推测策略,如果我们的性能分析表明对推测缺乏信心,则钻石推测作为备用方案。

基于 OSR 的推测依赖于这样一个事实:传统编译器已经擅长处理旁路退出。陷阱指令(例如 Java 虚拟机中的空检查优化)、异常和多个返回语句都是编译器已支持从函数退出的示例。
假设我们使用字节码作为未优化分析执行层和优化层之间共享的通用语言,那么退出目标可以是字节码指令边界。图 5 展示了这如何工作。优化编译器生成的机器代码包含针对不太可能条件的推测检查。其思想是进行大量推测。例如,序言(图中 enter 指令)可能会推测参数的类型——每个参数一个推测。一个 add 指令可能会推测其输入的类型以及结果不会溢出。我们的类型性能分析可能会告诉我们某个变量总是具有某种类型,因此一个源没有被证明具有该类型的 mov 指令可能会推测该值在运行时具有该类型。访问数组元素(我们称之为 get_by_val)可能会推测该数组确实是一个数组,索引是整数,索引在边界内,并且该索引处的值不是空洞(在 JavaScript 中,从从未赋值的数组元素加载意味着遍历数组的原型链以查看是否能在那里找到该元素——我们通过推测不必这样做来避免这种情况发生大部分时间)。调用函数可能会推测被调用者是我们期望的,或者至少它具有适当的类型(即它是我们可以调用的东西)。
虽然在不破坏优化编译器基本假设的情况下退出函数是直接的,但进入却非常困难。在函数的主要入口点之外的任何地方进入函数都会在入口点之间的任何合并点对优化产生负面影响。如果允许在每个字节码指令边界进入,这将通过强制每个指令边界对类型做出最坏情况的假设来抵消 OSR 退出的好处。即使仅在循环头允许 OSR 进入也会破坏许多循环优化。这意味着在退出后通常不可能重新进入优化执行。我们仅在回报很高的情况下支持进入,例如当我们的性能分析器告诉我们在编译时循环尚未终止。简而言之,传统编译器设计用于单入口多出口过程这一事实意味着 OSR 进入很困难但 OSR 退出很容易。
JavaScriptCore 和大多数推测性编译器都支持在热点循环处进行 OSR 进入,但由于它对于大多数应用程序来说并非一项必不可少的功能,我们将把了解其实现方式留作练习供读者参考。

本文主要部分从推测的五个组成部分(图 6)进行描述:虚拟机的字节码或通用 IR,它允许未优化分析层和优化层之间共享对性能分析和退出站点含义的理解;用于在启动时执行函数、收集性能分析数据并作为退出目标的未优化性能分析层;用于决定何时调用优化编译器的控制系统;结合传统优化编译器并增强以支持基于性能分析的推测的优化层;以及当推测检查失败时允许优化编译器使用性能分析层作为退出目标的OSR 退出技术。
JavaScriptCore 概述

JavaScriptCore 采用了分层思想,并为 JavaScript 提供了四个层级(WebAssembly 有三个层级,但这超出了本文的范围)。分层有两个好处:主要好处是(如前一节所述)能够实现推测;次要好处是允许我们针对每个函数细致调整吞吐量-延迟权衡。有些函数的运行时间很短——例如直线型的一次性初始化代码——以至于在这些函数上运行任何编译器都会比解释它们更昂贵。有些函数被频繁调用,或者有很长的循环,以至于它们的总执行时间远远超过使用激进优化编译器编译它们所需的时间。但在这两者之间也存在许多处于灰色区域的函数:它们运行时间不足以使激进编译器有利可图,但足够长,以至于一些中间编译器设计可以提供加速。JavaScriptCore 有四个层级,如图 7 所示:
- LLInt,即低级解释器,是一个遵循 JIT 编译器 ABI 的解释器。它与 JIT 在同一个栈上运行,并使用一组已知寄存器和栈位置来存储其内部状态。
- Baseline JIT,也称为字节码模板 JIT,它为每个字节码指令发出一个机器代码模板,而无需尝试推断函数中多个指令之间的关系。它编译整个函数,使其成为一个方法 JIT。Baseline 不进行 OSR 推测,但确实基于 LLInt 的性能分析进行了一些钻石推测。
- DFG JIT,即数据流图 JIT,它基于 LLInt、Baseline 的性能分析(在某些罕见情况下甚至使用 DFG JIT 和 FTL JIT 收集的性能分析数据)进行 OSR 推测。它可以 OSR 退出到 Baseline 或 LLInt。DFG 有一个名为 DFG IR 的编译器 IR,它允许对推测进行复杂的推理。DFG 避免执行昂贵的优化,并做了许多折衷以实现快速代码生成。
- FTL JIT,即超光速 JIT,它执行全面的编译器优化。它专为峰值吞吐量而设计。FTL 绝不会为了提高编译时间而牺牲吞吐量。这个 JIT 重用了 DFG JIT 的大部分优化并增加了更多。FTL JIT 使用多种 IR(DFG IR、DFG SSA IR、B3 IR 和 Assembly IR)。
一个理想的实际例子是这个程序
"use strict";
let result = 0;
for (let i = 0; i < 10000000; ++i) {
let o = {f: i};
result += o.f;
}
print(result);
由于循环内部的对象分配,它将运行很长时间,直到 FTL JIT 能够编译它。FTL JIT 将消除该分配,因此循环会很快完成。优化前漫长的运行时间几乎保证了 FTL JIT 将尝试编译该程序的全局函数。此外,由于函数简洁明了,我们所有的推测都是正确的,并且没有 OSR 退出。

图 8 展示了此基准测试在 JavaScriptCore 中执行的时间线。程序开始在 LLInt 中执行。大约一千次循环迭代后,循环触发器导致我们为这段代码启动一个 Baseline 编译器线程。一旦完成,我们会在 for 循环的头部进行 OSR 进入到 Baseline JIT 编译的代码中。Baseline JIT 也计算循环迭代次数,再经过大约一千次迭代后,我们启动 DFG 编译器。这个过程重复,直到我们进入 FTL。当我测量时,我发现 DFG 编译器所需的时间大约是 Baseline 编译器的 4 倍,而 FTL 所需的时间大约是 DFG 的 6 倍。虽然这个例子是人为设计和理想化的,但基本思想适用于任何运行时间足够长的 JavaScript 程序,因为 JavaScriptCore 的所有层级都支持完整的 JavaScript 语言。

JavaScriptCore 的架构使得拥有多个层级成为可能。图 9 说明了这种架构。所有层级共享相同的字节码作为输入。该字节码由一个编译器流水线生成,该流水线将许多语言特性(例如生成器和类等)进行去语法糖处理。在许多情况下,只需修改字节码生成前端即可添加新的语言特性。一旦链接,任何层级都可以理解该字节码。字节码可以直接由 LLInt 解释,或者由 Baseline JIT 编译,Baseline JIT 主要只是将每个字节码指令转换为预设的机器码模板。LLInt 和 Baseline JIT 共享大量代码,主要是在字节码指令执行的慢速路径中。DFG JIT 将字节码转换为其自己的 IR,即 DFG IR,并在发出代码之前对其进行优化。在许多情况下,DFG 选择不进行推测的操作会使用与 Baseline JIT 相同的代码生成辅助函数来发出。即使是 DFG 进行推测的操作,也经常与 Baseline JIT 共享慢速路径。FTL JIT 重用 DFG 的编译器流水线并为其添加新的优化,包括多个具有自己优化流水线的新 IR。尽管 FTL JIT 比 DFG 或 Baseline 更复杂,但它与那些 JIT 共享慢速路径实现,在某些情况下甚至共享我们选择不进行推测的操作的代码生成。尽管各个层级尽可能尝试共享代码,但它们并非必须如此。以字节码中的 get_by_val(访问数组元素)指令为例。它在字节码活跃性分析(了解 get_by_val 的活跃性规则)、LLInt(有一个非常大的实现,可以处理许多常见的数组类型并为它们提供良好的代码)、Baseline(使用多态内联缓存)和 DFG 字节码解析器中都有重复的定义。DFG 字节码解析器将 get_by_val 转换为 DFG IR 的 GetByVal 操作,该操作在 DFG 和 FTL 后端以及许多知道如何优化和建模 GetByVal 的阶段中都有单独的定义。唯一能让这些实现保持一致的是良好的约定和广泛的测试。
为了让大家对各个层级的相对吞吐量有所了解,我将分享一些多年来出于好奇心收集的非正式性能数据。
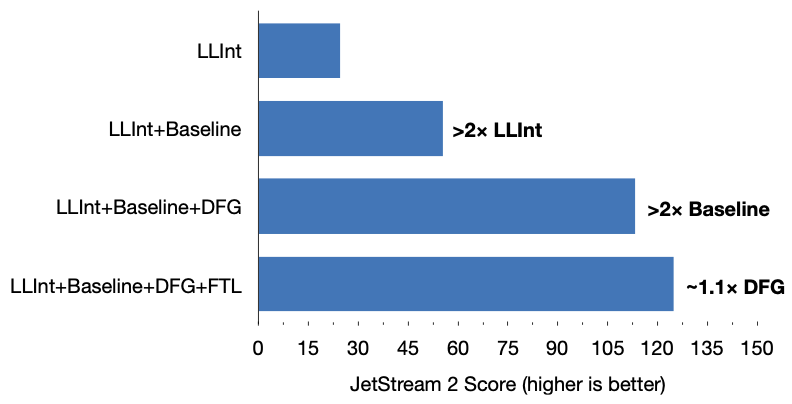
我们将使用 JetStream 2 基准测试套件,因为它是 JavaScriptCore 主要优化的套件。我们首先考虑一个实验,逐步启用层级,从 LLInt 开始运行 JetStream 2。图 10 显示了结果:Baseline 和 DFG 比它们下方的层级好 2 倍以上,FTL 比 DFG 好 1.1 倍。
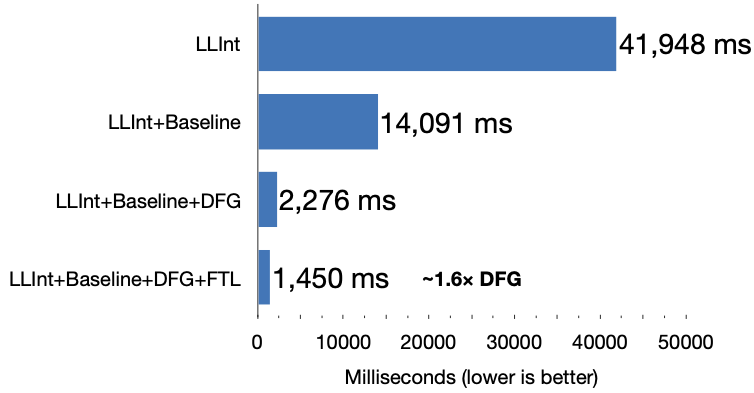
FTL 的优势可能不大,但它们是独一无二的。如果没有 FTL,我们将无法实现相同的峰值吞吐量。一个很好的例子是 gaussian-blur 子测试。这是 FTL 为其构建的一种计算测试。在我们首次引入该基准测试并且尚未有机会对其进行调优时,我设法测量了其性能。因此,这让我们得以一窥我们各层级对尚未经过基准测试调优的代码所期望的加速。图 11 显示了结果。所有的 JIT 都实现了惊人的加速:Baseline 比 LLInt 快 3 倍,DFG 比 Baseline 快 6 倍,FTL 比 DFG 快 1.6 倍。
DFG 和 FTL 相互补充。DFG 被设计为一种快速运行的编译器,它通过排除最激进的优化(如全局寄存器分配、逃逸分析、循环优化或任何需要 SSA 的东西)来实现这一点。这意味着 DFG 在峰值吞吐量方面总是会被具有这些功能的编译器击败。FTL 的任务是,如果一个函数运行时间足够长以至于值得,就提供这些优化。这确保了除非假设的竞争实现拥有相同数量的层级,否则它们无法超越我们。如果你想制作一个比 FTL 编译速度更快的编译器,那么你将失去峰值吞吐量,但如果你想制作一个比 DFG 生成更好代码的编译器,那么你将在启动时间上受到重创。你需要两者兼备才能在竞争中保持优势。
另一种看待这些层级性能的方式是:平均而言,在每个层级中执行一条字节码指令需要多长时间?这告诉我们一个层级所实现的吞吐量,而完全不考虑启动时间。这可能难以估计,但我尝试通过重复运行每个 JetStream 2 基准测试并随机限制每个函数的最高层级来实现。然后我采用了一种随机计数机制来估算每次运行中每个层级执行的字节码指令数量。结合这些运行的执行时间,这给出了一个简单的线性回归问题,形式如下:
ExecutionTime = (Latency of LLInt) * (Bytecodes in LLInt)
+ (Latency of Baseline) * (Bytecodes in Baseline)
+ (Latency of DFG) * (Bytecodes in DFG)
+ (Latency of FTL) * (Bytecodes in FTL)
其中 LLInt 的延迟 表示在 LLInt 中执行一条字节码指令所需的平均时间。
在排除了大部分时间花费在 JavaScript 执行之外的基准测试(如正则表达式和 wasm 基准测试)并调整了基准测试的权重方式(我最终决定单独解决每个基准测试并计算系数的几何平均值,因为这与 JetStream 2 的权重匹配)之后,我得出的解决方案是:
Execution Time = (3.97 ns) * (Bytecodes in LLInt)
+ (1.71 ns) * (Bytecodes in Baseline)
+ (.349 ns) * (Bytecodes in DFG)
+ (.225 ns) * (Bytecodes in FTL)
换句话说,Baseline 执行代码的速度比 LLInt 快约 2 倍,DFG 执行代码的速度比 Baseline 快约 5 倍,而 FTL 执行代码的速度比 DFG 快约 1.5 倍。请注意,这些数据与我们在 gaussian-blur 中看到的数据大致相同。这是有道理的,因为那是一个峰值吞吐量基准测试。
尽管这不是一篇关于垃圾回收的博客文章,但了解垃圾回收器的工作原理仍然很有价值。JavaScriptCore 选择了一种垃圾回收策略,使得虚拟机的其余部分(包括所有对推测的支持)更容易实现。垃圾回收器具有以下使推测更容易的特性:
- 回收器保守地扫描栈。这意味着编译器无需担心如何向回收器报告指针。
- 回收器不移动对象。这意味着如果一个数据结构(如编译器 IR)有多种可能的方式引用某个对象,我们只需向回收器报告其中一种即可。
- 回收器运行到不动点。这使得为推测创建的对象是否应该保持存活制定精确规则成为可能。
- 回收器的对象模型用 C++ 表示。JavaScript 对象看起来像 C++ 对象,而 JS 对象指针看起来像 C++ 指针。
这些特性使得编译器和运行时更容易编写,这非常好,因为推测需要我们编写大量的编译器和运行时代码。即使有本文中描述的优化,JavaScript 仍然是一种足够慢的语言,以至于垃圾回收器性能很少是瓶颈。因此,我们的垃圾回收器做出了许多权衡,以便更容易地处理我们引擎中性能关键的部分(例如推测)。例如,为了获得一个小的垃圾回收器优化而使某些编译器优化更难实现是不明智的,因为编译器对典型 JavaScript 程序的性能影响更大。
总结:JavaScriptCore 有四个层级,其中两个进行推测性优化,所有层级都参与性能分析数据的收集。前两个层级是解释器和字节码模板 JIT,而后两个是针对不同吞吐量-延迟权衡进行优化的编译器。
推测性编译
现在我们已经建立了关于推测和 JavaScriptCore 的一些基本背景知识,本节将深入探讨细节。首先,我们将讨论 JavaScriptCore 的字节码。然后,我们将展示用于启动优化编译器的控制系统。接下来将详细介绍 JavaScriptCore 的性能分析层如何工作,主要侧重于它们如何收集性能分析数据。最后,我们将讨论 JavaScriptCore 的优化编译器及其 OSR 方法。
字节码
推测需要一个性能分析层和一个优化层。当性能分析层报告性能分析数据时,它需要能够说明这些数据是针对代码的哪个部分。当优化编译器希望编译 OSR 退出时,它需要能够以两个层级都能理解的方式识别退出站点。为了解决这两个问题,我们需要一个通用的 IR,它应具备以下特性:
- 所有层级都使用其作为输入。
- 只要它所代表的函数仍然存活,就保持持久。
- 不可变(至少对于所有层级都感兴趣的部分)。
在本文中,我们将使用字节码作为通用 IR。这并非强制要求;抽象语法树甚至 SSA 也可以作为通用 IR。我们将深入探讨我们如何为 JavaScriptCore 设计字节码。JavaScriptCore 的字节码是基于寄存器的、紧凑的、无类型的、高级的、可直接解释的,并且可转换的。
我们的字节码是基于寄存器的,这意味着操作通常写成
add result, left, right
其含义是
result = left + right
其中 result、left 和 right 是虚拟寄存器。虚拟寄存器可能指局部变量、参数或常量池中的常量。函数声明它们需要多少个局部变量。局部变量既用于命名变量(如 var、let 或 const 变量),也用于表达式树评估产生的临时变量。
我们的字节码是紧凑的:每个操作码和操作数通常编码为一个字节。我们有宽前缀来允许 16 位或 32 位操作数。这很重要,因为 JavaScript 程序可能很大,并且字节码必须与其所代表的函数存活时间一样长。
我们的字节码是无类型的。虚拟寄存器从不具有静态类型。操作码通常不具有静态类型,除了少数对其输出有明确类型保证的操作码(例如,| 运算符总是返回 int32,因此我们的 bitor 操作码返回 int32)。这很重要,因为字节码旨在成为所有层级的通用真理来源。性能分析层在我们进行类型推断之前运行,因此字节码不能包含比 JavaScript 语言更多的类型。
我们的字节码几乎与 JavaScript 一样高级。虽然我们对许多 JavaScript 特性使用去语法糖,但我们只在通过去语法糖实现不被认为会牺牲性能时才这样做。因此,即使我们字节码的“基本”特性也是高级的。例如,add 操作码拥有 JavaScript + 运算符的所有功能,包括它可能意味着一个带有副作用的循环。
我们的字节码是可直接解释的。解释器执行的字节码流与我们将保存到缓存中(以便稍后跳过解析)并馈送给编译器层级的字节码流是相同的。
最后,我们的字节码是可转换的。通常,中间表示使用控制流图,并使其易于插入和删除指令。但字节码并非如此:它是一个使用非平凡的可变宽度编码的指令数组。不过,我们确实有一个字节码编辑 API,并将其用于生成器化(我们的生成器去语法糖字节码到字节码的传递)。我们可以想象此功能也可用于其他去语法糖或字节码插装实验。
与非字节码 IR 相比,字节码的主要优势在于它易于
- 识别 OSR 退出目标。 JavaScriptCore 中的 OSR 退出要求在某个任意字节码指令处进入未优化的字节码执行引擎(如解释器)。使用字节码指令索引作为命名退出目标的方式是直观的,因为它只是一个整数。
- 计算退出时的活跃状态。基于寄存器的字节码倾向于具有密集的寄存器编号,因此使用位向量分析活跃性是直接的。这通常很快,并且不需要大量内存。例如,缓存字节码活跃性分析的结果是实用的。
JavaScriptCore 的字节码格式由不同的执行层级独立实现。例如,Baseline JIT 不会尝试使用 LLInt 来创建其机器码模板;它只是自己发出这些模板,并且不试图与 LLInt 完全匹配(行为相同但实现不同)。这些层级确实共享大量代码——特别是用于内联缓存和慢速路径的代码——但它们并非必须如此。字节码指令在四个层级中具有算法上不同的实现是很常见的。例如,LLInt 可能会使用一个大型的 switch 语句来实现某个指令,该 switch 处理所有可能的类型;Baseline 可能会使用一个基于类型进行修补的内联缓存来实现相同的指令;而 DFG 和 FTL 可能会尝试将内联推测、内联缓存和发出对所有类型进行 switch 的代码结合起来。这种情况在 add 和其他算术操作以及 get_by_val/put_by_val 中都发生。允许这种独立性使得每个层级都能利用其独特的特性来提高运行速度。当然,这种方法也意味着添加新的字节码或改变字节码语义需要修改所有层级。因此,我们尝试通过将新的语言特性去语法糖化为现有的字节码构造来实现它们。
可以将任何合理的 IR 作为推测性编译器的通用 IR,包括抽象语法树或 SSA,但 JavaScriptCore 使用字节码,因此本文的其余部分将讨论字节码。
控制
推测性编译需要一个控制系统来决定何时运行优化编译器。控制系统必须平衡相互竞争的考量:在有利可图时尽快编译函数,避免编译运行时间不足以从中受益的函数,避免编译类型分析不足的函数,以及在先前编译的推测被证明错误时重新编译函数。本节描述了 JavaScriptCore 的控制系统。根据我们的经验,我们描述的大多数启发式方法对于使推测性编译有利可图都是必要的。否则,优化编译器会过于频繁、不够频繁或以不正确的速率对正确的函数进行介入。本节详细描述了 JavaScriptCore 的层级提升启发式方法,因为我们怀疑要重现我们的性能,需要所有这些启发式方法。
JavaScriptCore 计数函数和循环的执行次数 来决定何时编译。函数编译后,我们计数退出次数 来决定何时丢弃已编译的函数。最后,我们计数重新编译次数 来决定未来对函数重新编译的退避程度。
执行计数
JavaScriptCore 为每个函数维护一个执行计数器。该计数器按以下方式递增:
- 每次调用函数都会为执行计数器增加 15 点。
- 每次循环执行都会为执行计数器增加 1 点。
一旦计数器达到某个阈值,我们就会触发层级提升。阈值是动态确定的。为了理解我们的阈值,首先考虑它们的静态版本,然后看看我们如何根据其他信息调整这些阈值。
- LLInt→Baseline 层级提升需要 500 点。
- Baseline→DFG 层级提升需要 1000 点。
- DFG→FTL 层级提升需要 100000 点。
多年来,我们已经找到根据其他信息来源动态调整这些阈值的方法,例如:
- 上次遇到该函数时是否进行了 JIT 编译(根据我们的缓存)。我们称之为
wasJITed。 - 函数的大小。我们称之为
S。我们使用字节码操作码加上操作数的数量作为大小。 - 它已被重新编译了多少次。我们称之为
R。 - 可用可执行内存量。我们用
M表示我们总共有多少可执行内存,U是如果我们编译此函数,我们估计将使用(总共)的量。 - 性能分析是否“足够完整”。
我们根据 wasJITed 选择 LLInt→Baseline 阈值。如果我们不知道(函数不在缓存中),则使用基本阈值 500。否则,如果函数 wasJITed,则使用 250(以加速层级提升),否则使用 2000。此优化对于提高页面加载时间特别有用。
Baseline→DFG 和 DFG→FTL 使用基于 S、R、M 和 U 的相同缩放因子。缩放因子定义如下:
(0.825914 + 0.061504 * sqrt(S + 1.02406)) * pow(2, R) * M / (M - U)
我们将此因子乘以 1000 用于 Baseline→DFG,乘以 100000 用于 DFG→FTL。让我们分解一下这个缩放因子的作用:
首先,我们根据大小的平方根进行缩放。表达式 0.825914 + 0.061504 * sqrt(S + 1.02406) 给出的缩放因子对于小于约 350 字节码的函数(我们认为是“容易”编译的函数)在 1 到 2 之间。缩放因子使用平方根,因此它增长得比较平缓。我们也尝试过线性缩放因子,但效果差得多。适度延迟大型函数的编译是值得的,但过度延迟则不值得。请注意,理想的延迟不仅与编译成本有关。它也与运行足够长的时间以获得良好的性能分析数据有关。也许平方根在这里表现良好有深层原因,但我们真正关心的是,按此量进行缩放可以使程序运行得更快。
然后,我们根据函数重新编译的次数引入指数退避。pow(2, R) 表达式意味着每次重新编译都会使阈值翻倍。
之后,我们引入了一个双曲线缩放因子 M / (M - U),以帮助避免可执行内存完全耗尽的情况。这很重要,因为 JavaScriptCore 的某些配置在可执行内存池较小的情况下运行。这个表达式意味着如果我们使用一半的可执行内存,阈值就会翻倍。如果我们使用 3/4 的可执行内存,阈值就会翻四倍。这使得填满可执行内存有点像达到光速:数学上,当你越来越接近填满它时,阈值就会越来越接近无穷大。然而,值得注意的是,这对于真正的大型程序来说是不完美的,因为这些程序可能有其他分配可执行内存的原因,而本启发式方法未涵盖。在并行编译多个事物的情况下,该启发式方法也并不完美。使用此因子可以增加我们能够处理的程序的最大大小,即使可执行内存池很小,但这并非万能药。
最后,如果执行计数确实达到了这个动态计算的阈值,我们会检查某些类型的性能分析(具体来说是值和数组性能分析,将在接下来的性能分析部分详细讨论)是否足够完整。我们认为如果函数中超过 3/4 的性能分析点有数据,则性能分析是足够完整的。如果未达到此阈值,我们将重置执行计数器。我们让这个过程重复五次。优化编译器倾向于推测未分析的代码是不可达的。如果这些代码确实永远不会运行,这样做是有益的,但我们希望在这样做之前非常确定,因此我们为具有部分性能分析的函数提供 5 倍的预热时间。
这是一个令人兴奋的启发式组合!这些启发式方法是在 JSC 分层开发早期添加的。它们都是在构建 FTL 之前添加的,并且 FTL 继承了这些启发式方法,只是增加了 100 倍的乘数。添加每个启发式方法都是因为它产生了加速或内存使用减少,或两者兼而有之。我们尝试移除已知不再能提供加速的启发式方法,据我们所知,所有这些方法仍然有助于提高我们跟踪的基准测试的性能。
退出计数
当我们使用 DFG 或 FTL 编译一个函数后,我们所做的某个推测可能错了。这将导致函数 OSR 退出回到 LLInt 或 Baseline(我们更喜欢 Baseline,但在 GC 期间可能会丢弃 Baseline 代码,在这种情况下,从 DFG 和 FTL 的退出将回到 LLInt)。我们发现处理错误推测的最佳方法是丢弃优化后的代码,稍后使用更好的性能分析数据再次尝试优化。我们通过计数退出次数来检测 DFG 或 FTL 函数是否应该重新编译。退出计数阈值是:
- 对于正常退出,我们要求
100 * pow(2, R)次退出才能重新编译。 - 如果退出导致 Baseline JIT 进入其循环触发器(即退出后我们陷入了一个热循环),则会进行特殊计数。我们只允许
5 * pow(2, R)次此类退出,之后我们才会重新编译。请注意,这可能意味着退出五次并且每次都触发循环优化触发器,或者意味着退出一次并且触发循环优化触发器五次。
重新编译的第一步是抛弃 DFG 或 FTL 函数。这意味着未来所有对该函数的调用都将转而调用 Baseline 或 LLInt 函数。
重新编译
如果一个函数被抛弃,我们会增加重新编译计数器(我们表示为 R)并重置 Baseline JIT 中的层级提升功能。这意味着该函数将在 Baseline 中继续运行一段时间(比上次优化前的时间长一倍)。它将收集新的性能分析数据,我们能够将这些数据与之前收集的数据结合起来,以更准确地了解函数中类型的行为。
值得看一个实际的例子。我们已经在图 8 中展示了一个理想的层级提升案例,其中一个函数被每个编译器精确编译一次,并且没有 OSR 退出或重新编译。现在我们将展示一个事情进展不顺利的例子。选择这个例子是因为它是一个特别糟糕的异常值。这并不是我们期望引擎正常运行的方式。我们预计偶尔会出现以下这种有趣的糟糕情况,因为推测的成功或失败是随机的,而随机行为意味着会出现糟糕的异常值。
_handlePropertyAccessExpression = function (result, node)
{
result.possibleGetOverloads = node.possibleGetOverloads;
result.possibleSetOverloads = node.possibleSetOverloads;
result.possibleAndOverloads = node.possibleAndOverloads;
result.baseType = Node.visit(node.baseType, this);
result.callForGet = Node.visit(node.callForGet, this);
result.resultTypeForGet = Node.visit(node.resultTypeForGet, this);
result.callForAnd = Node.visit(node.callForAnd, this);
result.resultTypeForAnd = Node.visit(node.resultTypeForAnd, this);
result.callForSet = Node.visit(node.callForSet, this);
result.errorForSet = node.errorForSet;
result.updateCalls();
}
此函数属于 JetStream 2 的 WSL 子测试。它是 WSL 编译器 AST 遍历的一部分。在内联 Node.visit 后,它最终成为一个大型函数。当我在我的电脑上运行此函数时,我发现 JSC 在该函数达到稳定状态之前进行了 8 次编译:
- 在 LLInt 中运行该函数一段时间后,我们使用 Baseline 对其进行编译。这是简单的一部分,因为 Baseline 不需要重新编译。
- 我们使用 DFG 进行编译。不幸的是,DFG 编译退出了 101 次并被抛弃。退出是由于 DFG 在
this上发出的错误类型检查。 - 我们再次使用 DFG 进行编译。这次,由于对
result的检查,我们退出了两次。这不足以触发抛弃,并且它不会阻止升级到 FTL。 - 我们使用 FTL 进行编译。不幸的是,由于一个监视点失败,这次编译被抛弃了。监视点(在后面的章节中将详细讨论)是编译器请求运行时在发生不良情况时通知它的一种方式,而不是发出检查。失败的监视点会导致立即抛弃。这让我们回到了 Baseline。
- 我们再次尝试 DFG。由于对
result的错误检查,我们退出了七次,就像步骤 3 中一样。这仍然不足以触发抛弃,并且它不会阻止升级到 FTL。 - 我们使用 FTL 进行编译。这次由于对
node的错误类型检查,我们退出了 402 次。我们抛弃并回到 Baseline。 - 我们再次使用 DFG 进行编译。这次没有退出。
- 我们再次使用 FTL 进行编译。没有进一步的退出或重新编译。
除了编译次数之外,这一系列事件还有一些有趣的怪癖。请注意,在步骤 3 和 5 中,我们由于对 result 的错误检查而遇到了退出,但 FTL 的编译都没有遇到这些退出。这似乎说不通,因为 FTL 至少会执行 DFG 所做的所有推测,而且不会导致抛弃的推测也不会对未来的推测造成负面影响。同样令人惊讶的是,DFG 没有遇到在步骤 6 中导致 FTL 被抛弃的推测。FTL 可能会比 DFG 进行更多的推测,但这通常只发生在内联函数中,而对 node 的这种推测似乎不在内联代码中。对所有这些令人惊讶的怪癖的一个可能解释是函数正在经历阶段性变化:在执行的某些部分,它看到一组类型,而在执行的另一部分,它看到一组有所不同的类型。这是一个常见问题。类型不是随机的,它们通常是时间的函数。
JavaScriptCore 的编译器控制系统旨在为推测“正常工作”的函数和像本例中需要额外时间的函数都能获得良好的结果。总而言之,控制系统就是关于计算执行次数、退出次数和重新编译次数,然后要么启动更高层级的编译器(“层级提升”),要么抛弃优化代码并返回到 Baseline。
性能分析
本节介绍 JavaScriptCore 的性能分析层。性能分析层有以下职责:
- 提供一个非推测性执行引擎。这对于启动(在我们进行任何推测之前)和 OSR 退出非常重要。OSR 退出需要退出到一个不进行推测的地方,这样我们就不会对同一操作有连续的退出链。
- 记录有用的性能分析数据。如果性能分析数据能使我们进行有利可图的推测,那么它就是有用的。如果进行推测能使程序运行更快,那么推测就是有利可图的。
在 JavaScriptCore 中,LLInt 和 Baseline 是性能分析层,而 DFG 和 FTL 是优化层。然而,DFG 和 FTL 也会收集一些性能分析数据,通常只在免费执行且目的是为了完善性能分析层收集的数据时才进行。
本节组织如下。首先,我们将解释 JavaScriptCore 的性能分析层如何执行代码。然后,我们将解释性能分析的理念。最后,我们将深入探讨 JavaScriptCore 性能分析的实现细节。
性能分析执行的工作原理
JavaScriptCore 使用 LLInt 和 Baseline 层进行性能分析。LLInt 解释字节码,而 Baseline 编译字节码。这两个层级共享几乎相同的 ABI,因此可以在任何字节码指令边界从一个跳到另一个。
LLInt:低级解释器
LLInt 是一个遵循 JIT ABI 的解释器(类似于 HotSpot 的解释器)。为此,它采用一种名为 offlineasm 的可移植汇编语言编写。Offlineasm 嵌入了一种函数式宏语言(您可以传递宏闭包)。offlineasm 编译器是用 Ruby 编写的,可以编译到多种 CPU 以及 C++。本节将讲述为什么这种疯狂的设计能产生良好的结果。
LLInt 同时为 JavaScriptCore 实现了多个目标:
- LLInt 对 JIT 友好。LLInt 在与 JIT 相同的栈上运行(碰巧是 C 栈)。LLInt 甚至与 JIT 在寄存器约定上达成一致。这使得 LLInt 调用 JIT 编译的函数以及反向调用都非常廉价。它使得 LLInt→Baseline 和 Baseline→LLInt 的 OSR 变得微不足道,并使得任何 JIT→LLInt 的 OSR 成为可能。
- 即使我们无法进行 JIT 编译,LLInt 也允许我们执行 JavaScript 代码。JavaScriptCore 在无 JIT 模式(我们称之为“迷你模式”)下具有一些优势:它更难被利用,并且使用更少的内存。一些 JavaScriptCore 客户端偏好迷你模式。JSC 也用于我们没有 JIT 支持的 CPU 上。LLInt 在这些 CPU 上表现出色。
- LLInt 减少了内存使用。你从 JavaScript 生成的任何机器码都会很大。记住,JavaScript 之所以被称为“高级”而机器码被称为“低级”是有原因的:它指的是当你将 JavaScript 降级到机器码时,每个 JavaScript 表达式都会产生许多指令。拥有 LLInt 意味着我们不必为所有 JavaScript 代码生成机器码,这为我们节省了内存。
- LLInt 启动迅速。LLInt 直接解释我们的字节码格式。它的设计使得我们可以从磁盘映射字节码并让解释器指向它。LLInt 对于在浏览器中实现出色的页面加载时间至关重要。
- LLInt 是可移植的。它可以编译为 C++。
用 C++ 编写 LLInt 本来是很自然的事情,因为 JavaScriptCore 的大部分代码都是用 C++ 编写的。但这将意味着解释器会有一个由 C++ 编译器构建和控制的 C++ 栈帧。这将引入两个大问题:
- 从 LLInt 到 Baseline JIT 进行 OSR 或反之亦然将变得不清楚,因为 OSR 必须知道如何解码和重新编码 C++ 栈帧。我们不怀疑只要足够聪明就能做到这一点,但这会精确地限制 OSR 的工作方式,而且它不是一个容易维护的机制。
- 在 LLInt 中运行的 JS 函数将有两个栈帧而不是一个。其中一个栈帧必须进入 C++ 栈(因为它是 C++ 栈帧)。我们有多种选择来管理 JS 栈帧(我们可以尝试在 C++ 帧之上
alloca它,或者在其他地方分配它),但这不可避免地会增加成本:调用解释器将需要做双倍的工作。这种方法的一个常见优化是让解释器到解释器的调用通过在旁边管理一个单独的 JS 栈来重用相同的 C++ 栈帧。然后你可以让 JIT 使用那个单独的 JS 栈。这在从解释器调用到 JIT 或反之亦然时仍然会留下成本。
避免这些问题的一个自然方法是用汇编语言编写解释器。这基本上就是我们所做的。但是 JavaScript 解释器是一个复杂的庞然大物。如果将 JavaScriptCore 移植到新的 CPU 意味着用另一种汇编语言重写解释器,那将是可怕的。此外,我们希望使用抽象来编写它。如果用 C++ 编写,我们可能会有多个函数、模板和 lambda 表达式,并且我们希望它们都被内联。因此,我们设计了一种新语言 offlineasm,它具有以下特性:
- 可移植汇编,带有我们自己的助记符和寄存器名称,与我们在 JIT 中进行可移植汇编的方式相匹配。一些高级助记符需要降级。Offlineasm 保留了一些临时寄存器用于降级。
macro构造。最好将其视为一个接受一些参数并返回 void 的 lambda 表达式。然后将可移植汇编语句视为输出该汇编的打印语句。因此,宏是为产生效果而执行的,而该效果就是生成一个汇编程序。这些是 offlineasm 在编译时的执行语义。
宏允许我们编写具有丰富抽象的代码。考虑 LLInt 中的这个例子:
macro llintJumpTrueOrFalseOp(name, op, conditionOp)
llintOpWithJump(op_%name%, op, macro (size, get, jump, dispatch)
get(condition, t1)
loadConstantOrVariable(size, t1, t0)
btqnz t0, ~0xf, .slow
conditionOp(t0, .target)
dispatch()
.target:
jump(target)
.slow:
callSlowPath(_llint_slow_path_%name%)
nextInstruction()
end)
end
这是一个我们用于实现 jtrue 和 jfalse 以及操作码的宏。此列表中只有三行实际的汇编代码:btqnz(分支测试四字非零)和两个标签(.target 和 .slow)。这还展示了头等宏的使用:在第二行,我们调用 llintOpWithJump 并将其宏闭包作为第三个参数传递。拥有像 macro 这样的 lambda 式构造的优点是,我们不需要太多其他东西就能获得愉快的编程体验。LLInt 大约是用 5000 行 offlineasm 编写的(如果只计算 64 位版本)。
总而言之,LLInt 是一个用 offlineasm 编写的解释器。LLInt 理解 JIT ABI,因此 LLInt 和 JIT 之间的调用和 OSR 都很廉价。LLInt 允许 JavaScriptCore 更快地加载代码、使用更少的内存并在更多平台上运行。
Baseline:字节码模板 JIT
Baseline JIT 相对于 LLInt 实现了加速,但代价是一些内存和生成机器码所需的时间。Baseline 的加速得益于两个因素:
- 消除了解释器调度。解释器调度是解释中最昂贵的部分,因为用于选择操作码实现的间接分支对于 CPU 来说很难预测。这是 Baseline 比 LLInt 更快的主要原因。
- 全面支持多态内联缓存。在解释器中实现复杂的内联缓存是可能的,但目前我们最好的内联缓存实现是 JIT 共享的那个。
Baseline JIT 通过将每条字节码指令转换为机器码模板来编译字节码。例如,一条字节码指令,例如:
add loc6, arg1, arg2
被转换为类似如下的形式:
0x2f8084601a65: mov 0x30(%rbp), %rsi
0x2f8084601a69: mov 0x38(%rbp), %rdx
0x2f8084601a6d: cmp %r14, %rsi
0x2f8084601a70: jb 0x2f8084601af2
0x2f8084601a76: cmp %r14, %rdx
0x2f8084601a79: jb 0x2f8084601af2
0x2f8084601a7f: mov %esi, %eax
0x2f8084601a81: add %edx, %eax
0x2f8084601a83: jo 0x2f8084601af2
0x2f8084601a89: or %r14, %rax
0x2f8084601a8c: mov %rax, -0x38(%rbp)
这段代码中唯一会因 add 指令而异的部分是对操作数的引用。例如,0x30(%rbp)(那是 x86 中帧指针加 0x30 处的内存位置)是字节码中 arg1 的机器码表示。
Baseline JIT 除了发出代码模板之外,很少进行其他优化。例如,它在指令边界之间不进行寄存器分配。Baseline JIT 会做一些局部优化,例如如果数学操作的某个操作数是常量,或者通过使用 LLInt 收集的性能分析信息。Baseline 也很好地支持代码修补,这对于实现内联缓存至关重要。我们将在本节后面详细讨论内联缓存。
总而言之,Baseline JIT 是一个大部分未优化的 JIT 编译器,它专注于消除解释器调度开销。这足以使其比 LLInt 提速约 2 倍。
性能分析理念
JSC 中的性能分析设计为廉价且有用。
JavaScriptCore 的性能分析旨在在常见情况下几乎不产生或不产生开销。在开启性能分析但从不使用其结果进行优化的情况下运行,其吞吐量应与所有性能分析被禁用时大致相同。我们希望性能分析是廉价的,因为即使在一个长时间运行的程序中,许多函数也只运行一次或时间过短,无法使优化 JIT 有利可图。有些函数可能在优化它们所需的时间内完成运行。性能分析不能昂贵到让这类函数运行得更慢。
性能分析旨在帮助编译器进行能够加速程序运行的推测,同时考虑到正确推测带来的加速和错误推测带来的减速。我们可以将推测形式化地理解为一场赌注。如果性能分析能够将推测转化为一场有价值的赌注,那么它就是有用的。有价值的赌注是指期望值 (EV) 为正的赌注。这是另一种说法,即平均结果是有利可图的,因此如果我们重复无限次赌注,我们就会变得更富有。从形式上讲,赌注的期望值是:
p * B - (1 - p) * C
其中 p 是获胜概率,B 是获胜收益,C 是失败成本(B 和 C 均为正值)。当且仅当满足以下条件时,赌注才是有价值的:
p * B - (1 - p) * C > 0
让我们用这个公式来看待投机。我们选择是否进行“押注”的场景是:我们正在编译一条字节码指令,我们有一些分析(profiling)表明我们应该进行投机,并且我们必须选择是否投机。假设 B 和 C 都与执行一条字节码指令一次的延迟(纳秒)有关。如果我们进行了一些投机并且结果正确,B 是对该延迟的改进。如果我们进行的投机是错误的,C 是对该延迟的倒退。当然,在我们进行投机后,它会运行多次,有时可能正确,有时可能错误。但 B 仅指正确情况下的加速,而 C 仅指错误情况下的减速。测量 B 和 C 的基准是:如果字节码指令是用优化 JIT 编译的,但没有进行那种基于 OSR-exit 的特定投机,那么它的延迟。
例如,我们可能有一个小于(less-than)操作,我们正在考虑是否推测两个输入都不是双精度浮点数(double)。我们当然可以在不进行这种投机的情况下编译小于操作,所以这就是基准。如果我们选择投机,那么 B 是当两个输入都不是双精度浮点数时,该字节码平均执行延迟的加速。同时,C 是当至少一个输入是双精度浮点数时,该字节码平均执行延迟的减速。
对于 B,我们来计算一些边界。下限是零,因为有些投机是无利可图的。B 的一个相当不错的一阶上限是基准 JIT 和 FTL 之间每条字节码指令延迟的差异。通常,字节码指令从基准到 FTL 的全面加速是多重投机以及非投机性编译器优化的结果。因此,一个单一的投机导致基准和 FTL 之间性能的全部差异,这是 B 的一个相当保守的上限。之前我们说过,在我的电脑上运行 JetStream 2 基准测试时,一条字节码指令在 Baseline 中平均需要 1.71 纳秒执行,在 FTL 中需要 0.225 纳秒执行。所以我们可以说
B <= 1.71 ns - .225 ns = 1.48 ns
现在我们来估算 C。C 是指如果我们已经进行了投机并且经历了投机失败,执行字节码指令需要多花多少纳秒。失败意味着执行 OSR 退出桩(stub),然后以 Baseline 或 LLInt 模式重新执行相同的字节码指令。接着,函数中所有后续的字节码都将在 Baseline 或 LLInt 中执行,而不是 DFG 或 FTL。大约每 100 次退出,我们就会放弃(jettison)并最终重新编译。编译是并发的,但运行并发编译器肯定会减慢主线程,即使没有锁竞争。为了完全捕获 C,我们必须计算 OSR 退出本身的成本,然后摊销函数其余部分执行速度降低的成本以及最终重新编译的成本。幸运的是,通过修改 DFG 前端,使其以低概率随机插入无意义的 OSR 退出,并通过让 JSC 报告退出次数,可以很容易地直接测量这一点。我对 JetStream 2 的每个基准测试都进行了这项实验。在没有人工退出(synthetic exits)的情况下运行,我们得到一个执行时间和退出次数。在有人工退出的情况下运行,我们得到一个更长的执行时间和更多的退出次数。这两点之间的斜率是对 C 的估计。这是我在计算 B 的实验所用的同一台机器上发现的结果
[DFG] C = 2499 ns
[FTL] C = 9998 ns
注意 C 比 B 大得多!这可不是微小的差异。对于 DFG,我们谈论的是三个数量级,对于 FTL,是四个数量级。这描绘了一幅清晰的画面:投机是一场收益微薄、成本巨大的赌博。
对于 DFG,这意味着我们需要
p > 0.9994
投机才是一项有价值的押注。对于 FTL,p 必须更接近 1。基于此,我们对投机的理念是:除非我们认为,否则我们不会进行投机。
p ~ 1
由于投机失败的成本如此巨大,我们只会在知道不会失败的情况下进行投机。投机的加速之所以发生,是因为我们进行了大量确定的押注,其中只有极小一部分会失败。
这对分析(profiling)意味着什么,是相当清楚的。
- 分析需要关注记录我们想要进行的任何投机的反例。如果分析告诉我们反例曾发生过,我们就不想进行投机,因为如果它曾发生过,那么这种投机的期望值(EV)可能就是负的。这意味着我们不关心收集概率分布。我们只想知道坏事是否曾发生过。
- 分析需要运行很长时间。人们通常希望 JIT 编译器能更快地编译热点函数。我们不这样做的原因之一是,我们需要大约 3-4 个“九”(例如 99.9% 或 99.99%)的置信度,以确信反例没有发生。回想一下,我们升级到 DFG 的阈值大约是 1000 次执行。这可能并非巧合。
最后,由于分析(profiling)是一种押注,因此以一种健康的赌徒心态来对待它很重要:一项投机在特定程序中成功或失败的事实,并不能告诉我们这项投机是好是坏。投机的好坏仅基于它们的平均行为。过分关注分析在特定程序中表现是否良好,可能会导致采取平均表现不佳的方法。
JavaScriptCore 中的分析源
JavaScriptCore 从多个不同来源收集分析数据。这些分析源采用不同的设计。有时,一个分析源是独一无二的数据来源,但有时,分析源能够提供一些冗余数据。我们只在所有分析源都认为投机总是会成功时才进行投机。以下部分将详细描述我们的分析源。
情况标志(Case Flags)
情况标志用于分支投机。这适用于任何时候,当实现一个 JS 操作的最佳方式涉及分支和多条路径时,例如数学操作必须处理整数或双精度浮点数。最简单的分析和投机方法是让分析层实现分支的两端,并在每端设置不同的标志。这样,如果其他路径的标志未设置,优化层就知道它可以有利地推测只需要一条路径。在明显存在首选投机的情况下——例如,推测整数加法未溢出显然优于推测它溢出——我们只需要在我们不喜欢的路径(例如溢出路径)上设置标志。
让我们更详细地考虑情况标志的两个例子:整数溢出和对非对象值的属性访问。
假设我们正在编译一个已知接受整数作为输入的加法操作。通常,LLInt 解释器或 Baseline 编译器“知道”这一点的方式是,我们讨论的加法操作实际上是更大加法实现的一部分,在此之前我们已经检查过输入是整数。这是分析层会使用的逻辑,以 C++ 代码的形式编写,以便于解析:
int32_t left = ...;
int32_t right = ...;
ArithProfile* profile = ...; // This is the thing with the case flags.
int32_t intResult;
JSValue result; // This is a tagged JavaScript value that carries type.
if (UNLIKELY(addOverflowed(left, right, &intResult))) {
result = jsNumber(static_cast<double>(left) +
static_cast<double>(right));
// Set the case flag indicating that overflow happened.
profile->setObservedInt32Overflow();
} else
result = jsNumber(intResult);
优化代码时,我们将检查此指令的 ArithProfile 对象。如果 !profile->didObserveInt32Overflow() 为真,我们将发出类似以下的代码:
int32_t left = ...;
int32_t right = ...;
int32_t result;
speculate(!addOverflowed(left, right, &result));
即,我们将进行加法并在溢出时分支到退出。否则,我们将直接发出双精度浮点数路径的代码:
double left = ...;
double right = ...;
double result = left + right;
无条件地进行双精度浮点数运算并不那么昂贵;实际上,在我尝试过的基准测试中,它比进行整数运算和检查溢出更便宜。整数之所以有利可图,唯一原因是它们在位操作和指针算术中更便宜。由于 CPU 不接受浮点数或双精度浮点数用于位和指针运算,如果 JavaScript 程序以这种方式使用,我们首先需要将双精度浮点数转换为整数(当数字用作数组索引时会出现指针运算)。此类转换即使在原生支持这些转换的 CPU 上也相对昂贵。通常,使用分析或任何静态分析很难判断程序计算出的数字将来是否会用于位或指针运算。因此,最好使用带溢出检查的整数运算,这样如果该数字流向需要整数的操作,我们就无需支付昂贵的转换费用。但如果我们得知任何此类操作溢出——即使是偶尔溢出——我们发现无条件切换到双精度浮点数运算在整体上更高效。也许溢出的存在与这些操作的结果不被送入位运算或指针运算之间存在强相关性。
一个更简单的例子是情况标志如何在属性访问中使用。正如我们将在内联缓存(inline caches)部分讨论的,属性访问具有相关的元数据,我们用它来跟踪其行为细节。该元数据也包含标志,例如 sawNonCell 位,如果属性访问曾将非对象视为基数,我们就会将其设置为 true。如果该标志被设置,优化编译器就知道不要推测该属性访问会看到对象。这通常会强制该属性访问采取各种保守策略,但这比在这种情况下错误投机并退出要好。许多情况标志都类似于 sawNonCell:它们随意地作为某个现有数据结构中的一个位添加,以帮助优化编译器了解哪些路径已被执行。
总而言之,情况标志用于记录我们想要进行的投机的反例。在分析层无论如何都必须进行分支的情况下,它们是一种实现分析的自然方法。
情况计数(Case Counts)
JavaScriptCore 中情况标志的前身是情况计数。它的思想与标志相同,但不是仅仅设置一个位来表示发生了不好的事情,而是进行计数。如果计数从未超过某个阈值,我们就会进行投机。
情况计数是在我们意识到除非成功概率基本为 1,否则投机的期望值(EV)会很糟糕之前编写的。例如,我们曾认为在大多数情况下我们知道自己是正确的情况下,我们就可以进行投机。情况计数的初始版本具有可变阈值——我们会计算与执行次数的比率以获得情况发生率。这不如固定阈值有效,因此我们切换到固定计数阈值 100。随着时间的推移,我们将阈值降低到 20 或 10,然后最终发现阈值实际上应该为 1,此时我们切换到了情况标志。
一些功能仍然使用情况计数。我们仍然使用情况计数来判断 this 参数是否是异域的(this 的某些值要求函数在序言中执行可能产生副作用的转换)。我们仍然有情况计数作为数学操作溢出的备用,尽管这几乎肯定与我们的数学溢出情况标志冗余。我们最终很可能会从 JavaScriptCore 中移除情况计数。
值分析(Value Profiling)
值分析完全是为了推断 JavaScript 值(JSValues)的类型。由于 JS 是一种动态语言,JSValues 具有运行时类型。我们使用 64 位 JSValue 表示,它利用位编码技巧来存储双精度浮点数、整数、布尔值、null、undefined,或指向单元格(cell)的指针,这些单元格可能是 JavaScript 对象、符号或字符串。我们将值编码到 JSValue 中的行为称为装箱(boxing),将解码行为称为拆箱(unboxing)(请注意,装箱在其他引擎中特指在堆中分配一个“盒式对象”来存储值的行为;我们使用装箱这个术语更像是其他人所说的标记(tagging))。为了有效地优化 JavaScript,我们需要有一种推断类型的方法,以便编译器可以对其进行静态假设。值分析跟踪特定程序点所看到的值的集合,以便我们可以预测该程序点将来会看到哪些类型。

我们将值分析与一种名为预测传播的静态分析结合起来。关键在于,如果为某些不透明操作提供了起点,预测传播可以推断出大多数操作的良好类型猜测。
- 进入函数的参数。
- 大多数加载操作的结果。
- 大多数调用操作的结果。
没有任何静态分析仅仅在一个函数上运行就能猜测从普通 JavaScript 数组加载或调用普通 JavaScript 函数可能具有什么类型。值分析旨在帮助静态分析猜测那些不透明操作的类型。图 12 展示了这在一个示例数据流图中的表现。静态分析无法判断大多数 GetByVal 和 GetById 操作的类型,因为这些操作是从堆中动态类型的位置加载的。但是,如果我们确实知道这些操作返回什么,那么我们就可以使用简单的加法类型规则(例如,如果它以整数作为输入并且情况标志告诉我们没有溢出,那么它将产生整数)来推断整个图的类型。
让我们将值分析分解为详细介绍值是如何精确分析的、预测传播如何工作以及预测传播的结果如何使用。
记录值分析。其核心是,值分析就是让某个程序点(可以是解释器中的某个点,也可以是 Baseline JIT 发出的代码)记录它所看到的值。我们将值记录到一个单一的“桶”(bucket)中,以便每次分析点运行时,它都会覆盖上次看到的值。在 LLInt 中,代码看起来像这样:
macro valueProfile(op, metadata, value)
storeq value, %op%::Metadata::profile.m_buckets[metadata]
end
让我们看看值分析如何应用于 get_by_val 字节码指令。这是 LLInt 中 get_by_val 的部分代码:
llintOpWithMetadata(
op_get_by_val, OpGetByVal,
macro (size, get, dispatch, metadata, return)
macro finishGetByVal(result, scratch)
get(dst, scratch)
storeq result, [cfr, scratch, 8]
valueProfile(OpGetByVal, t5, result)
dispatch()
end
... // more code for get_by_val
get_by_val 的实现包含一个 finishGetByVal 辅助宏,它将结果存储在栈上的正确位置,然后分派到下一条指令。请注意,它还在完成之前调用 valueProfile 来记录结果。
每个 ValueProfile 对象都有一对“桶”(buckets)和一个预测类型。一个“桶”用于正常执行。LLInt 中的 valueProfile 宏使用这个“桶”。另一个“桶”用于 OSR 退出:如果由于我们从值分析中获得的类型上的投机而退出,我们会将导致 OSR 退出(OSR exit)的值回馈到 ValueProfile 的第二个“桶”中。
每次我们的执行计数器(用于控制何时调用下一层)计数到大约 1000 点时,执行计数慢路径(slow path)会更新该函数中所有值分析的预测类型。更新值分析意味着计算“桶”中值的预测类型,并将该类型与之前预测的类型合并。因此,经过反复的预测类型更新,该类型将足够广泛,以便对代码所看到的多个不同值有效。
预测类型使用 SpeculatedType 类型系统。SpeculatedType 是一个 64 位整数,我们用其低 40 位表示一组 40 种基本类型。图 13 中显示的基本类型代表了不重叠的可能 JSValues 集合。通过设置任何位的组合,可以得到 240 种 SpeculatedType。

这使我们能够发明任何对优化有用的类型。例如,我们区分值为 0 或 1 的 32 位整数(BoolInt32)和值为其他任何值的 32 位整数(NonBoolInt32)。它们共同组成了 Int32Only 类型,该类型仅设置了这两个位。BoolInt32 在整数转换为布尔值的情况下很有用。
预测传播。我们使用值分析来填充 DFG 编译器管道中预测传播阶段的空白。预测传播是一种抽象解释器,它跟踪程序中每个变量可能具有的类型集合。它是不健全的,因为它产生的类型只是预测(它可以产生任何类型的组合,最坏的情况是我们会进行过多的 OSR 退出)。然而,可以说我们对其进行了优化以使其健全;它越健全,我们的 OSR 退出就越少。预测传播利用值分析的结果,填补了抽象解释器无法推断的事物(从堆加载、调用返回的结果、函数的参数等)。关于健全性,如果在一个值分析永不出错的世界中预测传播是不健全的,我们就会认为这是一个 bug。当然,在现实中,我们知道值分析会出错,所以我们也知道预测传播是不健全的。
让我们考虑一些预测传播可以根据操作输入的类型确定其结果类型的情况。


array[index] 的操作码)的一些预测传播规则。此图仅显示了 GetByVal 规则的一小部分示例。图 14 显示了 DFG IR 中 Add 操作的一些规则。预测传播和情况标志告诉我们关于 Add 输出的一切信息。如果输入是整数且溢出标志未设置,则输出是整数。如果输入是其他类型的数字或发生溢出,则输出是双精度浮点数。我们不需要其他任何东西(如值分析)来理解 Add 的输出类型。
图 15 显示了 GetByVal 的一些规则,它是 array[index] 的 DFG 表示。在这种情况下,有些数组类型可以保存任何类型的值。因此,即使知道它是一个 JSArray,也不足以知道数组内部值的类型。此外,如果 index 是字符串,那么这可能是访问 array 对象或其原型之一上的某个命名属性,而这些属性可能具有任何类型。正是在 GetByVal 这样的情况下,我们利用值分析来猜测结果类型。
预测传播与值分析相结合,使 DFG 能够在程序中变量使用的每个点推断出预测类型。这使得那些本身不进行任何分析的操作仍然能够执行基于类型的投机。当然,也可以让能够对类型进行投机的字节码指令收集情况标志(或使用其他机制)来驱动这些投机——这种方法可以更精确——但值分析意味着我们不必为每个需要基于类型投机的操作都这样做。
使用预测类型。考虑 DFG IR 中的 CompareEq 操作,它用于 DFG 对 eq、eq_null、neq、neq_null、jeq、jeq_null、jneq 和 jneq_null 字节码的下层转换。这些字节码本身不进行任何分析。但 CompareEq 是 DFG 中最激进的类型投机者之一。CompareEq 可以对其看到的类型进行投机,而无需进行自己的分析,因为它使用的值要么具有值分析结果,要么具有由预测传播填充的预测类型。
DFG 中的类型投机写法如下:
CompareEq(Int32:@left, Int32:@right)
这个例子意味着 CompareEq 将推测两个操作数都是 Int32。CompareEq 支持以下投机,以及我们此处未列出的其他投机:
CompareEq(Boolean:@left, Boolean:@right)
CompareEq(Int32:@left, Int32:@right)
CompareEq(Int32:BooleanToNumber(Boolean:@left), Int32:@right)
CompareEq(Int32:BooleanToNumber(Untyped:@left), Int32:@right)
CompareEq(Int32:@left, Int32:BooleanToNumber(Boolean:@right))
CompareEq(Int32:@left, Int32:BooleanToNumber(Untyped:@right))
CompareEq(Int52Rep:@left, Int52Rep:@right)
CompareEq(DoubleRep:DoubleRep(Int52:@left), DoubleRep:DoubleRep(Int52:@right))
CompareEq(DoubleRep:DoubleRep(Int52:@left), DoubleRep:DoubleRep(RealNumber:@right))
CompareEq(DoubleRep:DoubleRep(Int52:@left), DoubleRep:DoubleRep(Number:@right))
CompareEq(DoubleRep:DoubleRep(Int52:@left), DoubleRep:DoubleRep(NotCell:@right))
CompareEq(DoubleRep:DoubleRep(RealNumber:@left), DoubleRep:DoubleRep(RealNumber:@right))
CompareEq(DoubleRep:..., DoubleRep:...)
CompareEq(StringIdent:@left, StringIdent:@right)
CompareEq(String:@left, String:@right)
CompareEq(Symbol:@left, Symbol:@right)
CompareEq(Object:@left, Object:@right)
CompareEq(Other:@left, Untyped:@right)
CompareEq(Untyped:@left, Other:@right)
CompareEq(Object:@left, ObjectOrOther:@right)
CompareEq(ObjectOrOther:@left, Object:@right)
CompareEq(Untyped:@left, Untyped:@right)
其中一些投机,例如 CompareEq(Int32:, Int32:) 或 CompareEq(Object:, Object:),允许编译器直接发出整数比较指令。其他投机,例如 CompareEq(String:, String:),则发出字符串比较循环。我们有很多变体来优化处理那些不仅在 JS 中可能发生,而且我们已经在实践中频繁遇到的奇怪比较,例如数字和布尔值之间的比较,以及一个值总是数字而另一个值可以是数字或布尔值之间的比较。我们还为双精度浮点数之间的比较、已进行哈希值共享(hash-consed)的字符串之间的比较(所谓的 StringIdent,可以通过比较字符串指针进行比较)以及我们不知道如何进行投机的比较(CompareEq(Untyped:, Untyped:))提供了额外的优化。
值分析的基本思想——将最后看到的值存储到“桶”中,然后用它来引导静态分析——我们也将它用于分析数组访问的行为。数组分析和数组分配分析类似于值分析,因为它们都将最后的结果保存在一个“桶”中。与值分析一样,来自这些分析的数据也被整合到预测传播中。
总而言之,值分析使我们能够通过仅在那些其输出无法通过抽象解释预测的字节码指令处收集分析数据,来预测变量在所有使用点的类型。这构成了 DFG(以及 FTL,因为它重用 DFG 的前端)如何推测 JSValues 类型的基础。
内联缓存(Inline Caches)
属性访问和函数调用是 JavaScript 中特别难以优化的部分。
- 对象表现得就好像它们只是从字符串到 JSValues 的有序映射。查询、插入、删除、替换和迭代都是可能的。程序经常执行这些操作,所以它们必须快速。在某些情况下,程序使用对象的方式与使用哈希表在其他语言中的方式相同。在另一些情况下,程序使用对象的方式与在 Java 或一些类型合理的面向对象语言中相同。大多数程序两者兼而有之。
- 函数调用是多态的。你无法对将调用哪个函数做出静态保证。
这两种动态特性都可以通过Deutsch 和 Schiffman 的内联缓存(ICs)进行优化。对于动态属性访问,我们将其与结构(structures)结合,这基于 Chambers, Ungar 和 Lee 的 Self 实现中的映射(maps)概念。我们也遵循Hölzle、Chambers 和 Ungar:我们的内联缓存是多态的,并且我们使用这些缓存中的数据作为在特定属性访问或调用点观察到的类型的分析数据。
值得稍微深入探讨一下内联缓存的强大之处。内联缓存是独立于投机编译的优秀优化。它们使 LLInt 和 Baseline 运行得更快。内联缓存是我们最强大的分析源,因为它们可以精确收集关于每次访问或调用所遇到的所有类型的信息。请注意,我们之前说过好的分析必须成本低廉。我们认为内联缓存是负成本分析,因为内联缓存使 LLInt 和 Baseline 运行得更快。没有比这更便宜的了!
本节重点介绍动态属性访问的内联缓存,因为它比函数调用更复杂(属性访问使用结构、多态内联缓存(PICs)和投机编译;函数调用仅使用多态内联缓存和投机编译)。我们将动态属性访问的内联缓存讨论组织如下。首先,我们描述结构如何工作。然后,我们展示 JavaScriptCore 对象模型以及它如何包含结构。接下来,我们展示内联缓存如何工作。然后,我们展示优化编译器如何使用来自内联缓存的分析数据。之后,我们展示内联缓存如何支持多态性和多变性。最后,我们讨论内联缓存如何与垃圾收集器集成。
结构。JavaScript 中的对象只是从字符串到 JSValues 的映射。查询、插入、删除、替换和迭代都是可能的。我们希望优化那些如果语言能让程序员指定类型就会有类型的对象使用方式。

考虑如何实现属性访问,例如
var tmp = o.x;
或者
o.x = tmp;
使其快速的一种方法是使用哈希表。当 JavaScript 程序使用对象更像哈希表而不是对象时(即它频繁插入和删除属性),这无疑是一种必要的备用机制。但我们可以做得更好。
这个问题在动态编程语言中经常出现,并且有一个成熟的解决方案。Chambers, Ungar 和 Lee 的 Self 实现的关键见解是,程序中的属性访问点通常只会看到具有相同形状的对象。考虑图 16 中具有 x 和 y 属性的对象。当然,可以按两种可能的顺序插入 x 和 y,但人们倾向于选择一种顺序并坚持下去(例如 x 优先)。当然也可能有具有 z 属性的对象,但编写为处理 {x, y} 对象的程序部分的属性访问不太可能被重用于处理 {x, y, z} 的部分。对于许多不同类型的对象,共享代码是可能的,但非共享代码更常见。因此,我们将对象表示分为两部分:
- 对象本身,它只包含属性值和一个结构指针。
- 结构,它是一个哈希表,将属性名(字符串)映射到拥有该结构的对象中的索引。

图 17 显示了使用结构表示的对象。对象只包含对象属性值和指向结构的指针。结构指示属性名及其顺序。例如,如果我们要查询图 17 中 {1, 2} 对象的属性 x 的值,我们会加载指向其结构 {x, y} 的指针,并向该结构查询 x 的索引。索引是 0,{1, 2} 对象中索引 0 处的值是 1。
结构的一个关键特性是它们是哈希值共享的。如果两个对象具有相同顺序的相同属性,它们很可能拥有相同的结构。这意味着检查对象是否具有特定结构是 O(1) 操作:只需从对象头加载结构指针并将其与已知值进行比较。
结构还可以指示对象处于字典(dictionary)或不可缓存字典(uncacheable dictionary)模式,这基本上是哈希表性能不良的两个级别。在这两种情况下,结构不再进行哈希值共享,而是与它的对象进行一对一配对。字典对象可以添加新属性而结构不改变(属性在原地添加到结构中)。不可缓存字典对象可以删除属性而结构不改变。在这篇博客中,我们不会详细讨论这些模式。
总而言之,结构是哈希表,将属性名映射到对象中的索引。对象属性查找使用对象的结构来找到属性的索引。结构进行哈希值共享,以实现快速结构检查。

JavaScriptCore 对象模型。JavaScriptCore 使用具有 64 位头部信息(header)的对象,其中包含一个 32 位结构 ID 和 32 位额外状态,用于垃圾回收(GC)、类型检查和数组。图 18 展示了对象模型。命名对象属性可能最终位于内联槽(inline slots)或外联槽(out-of-line slots)中。对象根据分配点周围的简单静态分析获得一定数量的内联槽。如果添加的属性不适合内联槽,我们会分配一个蝴蝶(butterfly)来存储额外的外联属性。访问蝴蝶中的外联属性需要额外的一次加载。
图 19 显示了一个只包含两个内联属性的示例对象。如果你使用对象字面量 {f:5, g:6},或者在分配位置附近合理地赋值给 f 和 g 属性,你就会得到这种对象。

简单内联缓存。让我们考虑以下代码:
var v = o.f;
假设所有流向此处的对象都具有结构 42,就像图 19 中的对象一样。内联缓存此属性访问完全是为了发出如下代码:
if (o->structureID == 42)
v = o->inlineStorage[0]
else
v = slowGet(o, "f")
但我们怎么知道 o 会有结构 42 呢?JavaScript 不会静态地提供这些信息。内联缓存通过在代码运行时填充来获取这些信息。有多种技术可以实现这一点,所有这些都归结为自修改代码。让我们看看 LLInt 和 Baseline 是如何做到的。
在 LLInt 中,get_by_id 的元数据包含一个缓存的结构 ID 和一个缓存的偏移量。缓存的结构 ID 被初始化为一个荒谬的值,任何结构都不能拥有该值。如果对象具有缓存的结构,get_by_id 的快速路径(fast path)会在缓存的偏移量处加载属性。否则,我们走慢路径(slow path)进行完全查找。如果该完全查找是可缓存的,它会将结构 ID 和偏移量存储在元数据中。
Baseline JIT 做了一些更复杂的事情。当发出 get_by_id 时,它会预留一块机器码空间,内联缓存稍后会用真实代码填充这块空间。这块空间最初的代码只有一个无条件跳转到慢路径。慢路径执行完全动态查找。如果这被认为是可缓存的,预留的空间就会被替换为执行正确结构检查并在正确偏移量处加载的代码。这是一个最初用 Baseline 编译的 get_by_id 示例:
0x46f8c30b9b0: mov 0x30(%rbp), %rax
0x46f8c30b9b4: test %rax, %r15
0x46f8c30b9b7: jnz 0x46f8c30ba2c
0x46f8c30b9bd: jmp 0x46f8c30ba2c
0x46f8c30b9c2: o16 nop %cs:0x200(%rax,%rax)
0x46f8c30b9d1: nop (%rax)
0x46f8c30b9d4: mov %rax, -0x38(%rbp)
这段代码做的第一件事是检查 o(存储在 %rax 中)是否真的是一个对象(使用 test 和 jnz)。接着请注意无条件 jmp 后跟两条长 nop 指令。这个跳转会进入与 o 不是对象时我们所分支到的慢路径相同的路径。慢路径运行后,它被重新打补丁为:
0x46f8c30b9b0: mov 0x30(%rbp), %rax
0x46f8c30b9b4: test %rax, %r15
0x46f8c30b9b7: jnz 0x46f8c30ba2c
0x46f8c30b9bd: cmp $0x125, (%rax)
0x46f8c30b9c3: jnz 0x46f8c30ba2c
0x46f8c30b9c9: mov 0x18(%rax), %rax
0x46f8c30b9cd: nop 0x200(%rax)
0x46f8c30b9d4: mov %rax, -0x38(%rbp)
现在,对象检查之后是一个结构检查(使用 cmp 检查结构是否为 0x125),以及在偏移量 0x18 处的一次加载。
内联缓存作为分析源。我们用于维护内联缓存的元数据是一个极好的分析源。让我们仔细看看这意味着什么。

get_by_id 生成代码六次。图 20 展示了多层引擎中内联缓存的简单使用,其中 DFG JIT 忘记了从 Baseline 内联缓存中学到的一切,只编译了一个空白内联缓存。这种方法效率合理,当 LLInt 和 Baseline 的内联缓存告诉我们存在无法管理的多态性时,我们会回退到这种方法。在深入探讨如何分析多态性之前,让我们看看投机编译器实际上是如何处理像图 20 中那样简单的单态内联缓存的,在那种情况下,我们只看到一个结构(S1),并且 IC 发出的代码是微不足道的(从 %rax 偏移量 10 处加载)。
当 DFG 前端(DFG 和 FTL 共享)看到一个可以使用 IC 实现的 get_by_id 操作时,它会读取为该 get_by_id 生成的所有 IC 的状态。“所有 IC”指的是当前堆中存在的所有 IC。这通常意味着只读取 LLInt 和 Baseline 的 IC,但如果存在为这个 get_by_id 生成了 IC 的 DFG 或 FTL 函数,那么我们也会读取那个 IC。如果函数由于内联而被多次编译,则可能发生这种情况——我们可能正在编译函数 bar,其中内联了对函数 foo 的调用,而 foo 已经用 FTL 编译过,并且 FTL 为我们的 get_by_id 发出了一个 IC。
如果一个 get_by_id 的所有 IC 都一致认为该操作是单态的,并且它们告诉我们使用的结构,那么 DFG 前端会将 get_by_id 转换为不会被重新打补丁的内联代码。这在图 21 中显示。请注意,这个简单的 get_by_id 被下层转换(lowered)为两个 DFG 操作:CheckStructure,如果给定对象没有所需的结构则 OSR 退出;以及 GetByOffset,它只是一个带有已知偏移量和字段名的加载操作。

CheckStructure 和 GetByOffset 在 DFG IR 中被精确理解:
- CheckStructure 是加载对象结构 ID 的操作,并伴随一个分支,用于将该结构 ID 与一个常量进行比较。编译器知道结构是什么。在 CheckStructure 之后,编译器知道可以安全地加载该结构所声明的任何对象属性。
- GetByOffset 是从 JavaScript 对象的内联或外联属性加载数据的操作。编译器知道正在加载的是哪种属性、其偏移量是多少以及该属性的名称是什么。
DFG 完全了解如何建模这些操作以及它们之间的依赖关系:
- DFG 知道这两个操作都不会产生副作用,但 CheckStructure 代表一个条件性旁路退出,并且两个操作都会读取堆。
- DFG 知道对同一结构进行两次 CheckStructure 是冗余的,除非它们之间存在某些操作可能会改变对象结构。DFG 对如何优化掉冗余结构检查了解很多,即使在两次检查之间存在函数调用的情况下也是如此(稍后会详细介绍)。
- DFG 知道两个 GetByOffset 操作,如果它们涉及相同的属性和对象,那么它们是从相同的内存位置加载的。DFG 知道如何对这些属性进行别名分析,因此它可以精确地知道 GetByOffset 的内存位置何时被破坏。
- DFG 知道如果它想提升(hoist)一个 GetByOffset,那么它必须确保对应的 CheckStructure 首先被提升。它使用抽象解释来完成此操作,因此这些操作之间无需存在依赖边。
- DFG 知道如何为 CheckStructure 和 GetByOffset 生成机器码(在 DFG 层)或 B3 IR(在 FTL 层)。在 B3 中,CheckStructure 变为 Load、NotEqual 和 Check,而 GetByOffset 通常只变为 Load。

将 IC 下层转换为 CheckStructure 和 GetByOffset 的最大好处是消除了冗余。我们消除的最常见冗余是多个 CheckStructure。许多代码会从同一对象进行多次加载,例如:
var f = o.f;
var g = o.g;
使用 IC,我们会检查结构两次。图 22 显示了当投机编译器内联这些 IC 时发生的情况。我们只剩下一个 CheckStructure 而不是两个,这得益于以下事实:
- CheckStructure 是一种 OSR 投机。
- CheckStructure 不是一个 IC。编译器确切地知道它做什么,因此可以对其进行建模,从而可以消除它。
让我们暂停一下,回顾这项技术到目前为止给我们带来了什么。我们最初使用一种语言,其中属性访问似乎需要哈希表查找。一个 o.f 操作需要调用某个执行哈希等的程序。但是,通过结合内联缓存、结构和投机编译,我们得到的结果是某些 o.f 操作无非就是像 C++ 或 Java 中那样的偏移量加载。但这假设 o.f 操作是单态的。本节的其余部分将考虑最小多态性(minimorphism)、多态性(polymorphism)和多变性(polyvariance)。
最小多态性。某些多态访问比其他更容易处理。有时,一个访问会看到两个或更多的结构,但所有这些结构都在相同的偏移量处拥有该属性。其他时候,一个访问会看到多个结构,而这些结构在属性的偏移量上不一致。如果一个访问看到不止一个结构,并且所有结构在属性的偏移量上都一致,我们就说该访问是最小多态的(minimorphic)。
我们的内联缓存通过生成一个根据结构进行切换的桩(stub)来处理所有形式的多态性。但在 DFG 中,最小多态访问是特殊的,因为它们仍然符合完全内联的条件。考虑一个访问 o.f,它看到结构 S1 和 S2,并且两者都同意 f 在偏移量 0 处。那么我们会有:
CheckStructure(@o, S1, S2)
GetByOffset(@o, 0)
如果 @o 不包含列出的任何结构,这个最小多态的 CheckStructure 将触发 OSR 退出。我们对 CheckStructure 的优化通常适用于单态和最小多态变体。因此,与单态性相比,最小多态性通常不会对性能造成太大损害。
多态性。但如果某个访问看到不同的结构,并且这些结构在不同的偏移量处具有该属性呢?考虑对 o.f 的一次访问,它看到结构 S1 = {f, g}、S2 = {f, g, h} 和 S3 = {g, f}。如果只是 S1 或 S2,这将是一个最小多态访问,但 S3 的 f 位于不同的偏移量。在这种情况下,FTL 会将其转换为:
MultiGetByOffset(@o, [S1, S2] => 0, [S3] => 1)
在 DFG IR 中,然后将其下层转换为类似以下内容:
if (o->structureID == S1 || o->structureID == S2)
result = o->inlineStorage[0]
else
result = o->inlineStorage[1]
在 B3 IR 中。实际上,我们会使用 B3 的 Switch,因为这是 B3 中这种代码模式的规范形式。
请注意,我们只在 FTL 中进行这项优化。原因是我们希望多态访问在 DFG 中保持为 IC,以便我们可以使用它们来收集更精细的分析数据。

bar 并使用 IC 收集关于 get_by_id 的多变分析数据后,FTL 可以在内联到 bar 中的 foo 中内联该内联缓存。多变性。多变性是指分析能够根据函数的调用来源以不同方式推断函数。我们通过在 DFG 层进行内联并保持多态 IC 为 IC 来实现这一点。考虑以下示例。函数 foo 访问 o.f,该访问是多态的,并看到结构 S1 = {f, g}、S2 = {f, g, h} 和 S3 = {g, f}:
function foo(o)
{
// o can have structure S1, S2, or S3.
return o.f;
}
这个函数很小,所以只要我们的分析告诉我们正在调用它(或可能正在调用它,因为调用内联支持内联多态调用),它就会被内联。假设我们有另一个函数 bar,它总是将结构 S1 = {f, g} 的对象传递给 foo:
function bar(p)
{
// p.g always happens to have structure S1.
return foo(p.g);
}
图 23 显示了发生的情况。当 DFG 编译 bar(步骤 3)时,它会根据其 call 操作码的分析(步骤 2)内联 foo。但它会将 foo 的 get_by_id 作为一个 IC 留下,因为 foo 的 Baseline 版本告诉我们它是多态的(也是步骤 2)。但随后,由于 DFG 为 foo 的 get_by_id 创建的 IC 是从 bar 调用该函数的上下文,它只看到了 S1(步骤 4)。因此,当 FTL 编译 bar 并内联 foo 时,它知道这个 get_by_id 可以用针对 S1 的单态结构检查进行内联(步骤 5)。
内联缓存还支持更奇特的属性访问形式,例如从原型链中的对象加载、调用访问器、添加/替换属性,甚至删除属性。
内联缓存、结构和垃圾回收。内联缓存导致对象被分配和引用,仅用于内联缓存。结构是这类对象中最臭名昭著的例子。结构尤其成问题,因为它们需要强引用对象的原型和其全局对象。在某些情况下,一个结构可能只能从某个内联缓存中访问,而该内联缓存将永不再次运行(但我们无法证明这一点),并且存在一个仅被该结构引用的庞大全局对象。很难判断这是否意味着该结构必须被删除。如果应该删除,则必须重置内联缓存。如果任何优化代码内联了该内联缓存,那么该代码必须被废弃(jettisoned)并重新编译。幸运的是,我们的垃圾收集器允许我们精确地描述这种情况。由于垃圾收集器运行到不动点(fixpoint),我们只需添加一个约束:只有当结构的全局对象和原型已经被标记时,从内联缓存到结构的指针才标记该结构。否则,该指针表现得像一个弱指针。因此,只有当访问该结构的唯一方式是通过内联缓存,并且相应的全局对象和原型已失效时,内联缓存才会被重置。这是我们的垃圾收集器如何设计以简化投机的一个例子。
总而言之,内联缓存是我们所有层级都采用的一种优化。除了使代码运行更快,内联缓存还是一个高精度的分析源,可以告诉我们操作所遇到的类型情况。结合结构,内联缓存使我们能够将动态属性访问转换为易于优化的指令。
观测点(Watchpoints)
我们允许内联缓存和投机编译器在堆上设置观测点(watchpoints)。JavaScriptCore 中的观测点无非是一种注册机制,用于接收某个事件发生的通知。大多数观测点都设计成只在第一次发生不好的事情时触发;之后,观测点只会记住不好的事情曾发生过。因此,如果一个优化编译器想要做某件只有在某个不好的事情从未发生过的情况下才有效的事情,并且该不好的事情有一个观测点,编译器会检查该观测点是否仍然有效(即坏事尚未发生),然后将其生成的代码与该观测点关联起来(这样,只有当代码编译完成时观测点仍然有效,代码才会被安装,并且一旦观测点触发,代码就会被废弃)。运行时允许在大量活动上设置观测点。以下几点突出:
- 可以对结构设置观测点,以便在任何对象从该结构切换到另一个结构时获得通知。这只适用于其对象从未转换到任何其他结构的结构。这称为结构转换观测点。它将一个结构确立为结构转换树中的叶子节点。
- 可以对结构中的属性设置观测点,以便在属性被覆盖时获得通知。覆盖属性很容易检测,因为这种情况第一次发生时,通常涉及重新修补
put_by_id内联缓存,使其进入属性替换模式。这称为属性替换观测点。 - 可以对全局变量的可变性设置观测点。
将这些观测点结合起来,使投机编译器能够对恰好不可变的对象属性进行常量折叠。让我们考虑一个简单的例子:
Math.pow(42, 2)
这里,Math 是一个全局属性查找。编译器已知基础对象:它是调用代码所属的全局对象。接着,Math.pow 是在 Math 对象上查找 pow 属性。全局对象的 Math 属性或 Math 对象的 pow 属性被覆盖的可能性极低。全局对象和 Math 对象都具有其独有的结构(既因为这些结构是特殊对象而具有特殊魔力,也因为这些对象通常具有一组全局唯一的属性),这保证了它们具有叶子结构,因此可以设置结构转换观测点。因此,除了病态程序,表达式 Math.pow 会被投机编译器编译成一个常量。这使得许多东西变得快速:
- 在 JetStream 2 的 TypeScript 编译器基准测试中,使用对象和对象属性进行命名和范围枚举很常见,例如
TypeScript.NodeType.Error。观测点使这些在投机编译器看来像一个常量。 - 像
o.foo(things)这样的方法调用通常会转换为对o的结构检查和一次直接调用。一旦结构被检查,观测点会确定对象的原型具有一个名为foo的属性,并且该属性具有某个常量值。 - 内联缓存使用观测点来移除其生成的桩中的一些检查。
- 即使在两个 CheckStructure 之间存在副作用,DFG 也可以使用观测点来移除冗余的 CheckStructure。如果我们设置了结构转换观测点,那么我们知道任何效应都不能改变拥有此结构的任何对象的结构。
- 观测点用于 JavaScript 的许多杂项边缘情况,例如遇到问题。
总而言之,观测点允许内联缓存和投机编译器通过在状态变化时获得通知,将堆的某些部分折叠为常量。
退出标志(Exit Flags)
我们引擎中所有的分析源都有可能出错。分析源出错的原因是:
- 程序可能在我们收集分析数据和我们基于其进行投机之间改变行为。
- 分析具有一定的随机性,并且程序运气不佳,导致错误的分析。
- 分析源存在逻辑错误,使其无法察觉某些事情的发生。
- 我们忽视了为某些东西实现分析器,而是盲目投机。
这些问题中的第一个——行为随时间变化——是不可避免的,并且在任何足够大的程序中,某些函数肯定会发生这种情况。大型程序往往会经历阶段性变化,例如某个子例程可能从一个使用特定类型集的较大库的一部分被调用,转变为从使用不同类型的另一部分被调用。这些情况不可避免地导致退出。另外三个问题都是分析“失效”的不同变体。我们不希望我们的分析失效,但我们毕竟是人。回想一下,投机要获得良好的期望值(EV),正确概率必须接近 1。因此,仅仅依赖不完美的生命体编写的分析是不够的。退出标志是对其余分析的一种检查,它们旨在确保我们最终能正确处理所有程序。
在 JavaScriptCore 中,每个 OSR 退出都带有一个退出类型(exit kind)标签。当一个 DFG 或 FTL 函数退出次数足够多而被废弃(jettisoned)时,我们会记录所有发生的退出类型以及语义上导致退出的字节码位置(例如,如果我们在字节码 #63 对 add 进行类型检查,但随后提升(hoist)了该检查,使其最终在字节码 #45 处退出,那么我们会将原因归咎于 #63 而不是 #45)。每当 DFG 或 FTL 决定是否执行某种投机时,它们都应该检查我们正在编译的字节码处是否存在针对该投机的退出标志。我们的退出标志检查机制往往比我们的分析机制严格得多,而且更容易做对——DFG 的每个阶段都可以快速访问退出标志。
以下是 DFG 中实际 OSR 退出检查的一个例子:
speculationCheck(
OutOfBounds, JSValueRegs(), 0,
m_jit.branch32(
MacroAssembler::AboveOrEqual,
propertyReg,
MacroAssembler::Address(storageReg, Butterfly::offsetOfPublicLength())));
请注意,第一个参数是 OutOfBounds。这是一个退出类型的示例。这是另一个例子,这次来自 FTL:
speculate(NegativeZero, noValue(), nullptr, m_out.lessThan(left, m_out.int32Zero));
同样,第一个参数是退出类型。这次是 NegativeZero。我们有26 种退出类型,其中大多数描述了类型检查条件(有些用于 OSR 的其他用途,如异常处理)。
在选择是否进行投机时,我们通过查询正在编译的字节码位置是否曾发生过退出,来使用退出类型。对于那个字节码,我们通常将退出标志的存在作为完全不进行投机的一个理由。我们实际上允许自己稍微过度补偿。退出标志是对其余分析器的一种检查。它们告诉编译器,分析器之前在这里犯过错误,因此,对于这个代码位置,不应再信任它。
分析总结
JavaScriptCore 的分析(profiling)旨在做到廉价且有用。我们最好的分析源倾向于要么涉及最小的插桩(instrumentation)(例如仅仅设置一个标志或将值存储到已知位置),要么与优化紧密结合(例如内联缓存)。我们的分析器收集了大量丰富的信息,在某些情况下我们甚至会冗余地收集信息。我们的分析旨在帮助我们避免进行即使只错一次也会导致错误的投机。
编译与 OSR
既然我们已经介绍了字节码、控制和分析,我们就可以进入真正有趣的部分:如何构建一个出色的投机优化编译器。我们将结合对两个优化编译器的描述,同步讨论投机的 OSR 方面。
本节分为三部分。首先,我们简要地介绍 DFG IR,这是 DFG 和 FTL 层都使用的中间表示。接着,我们详细描述 DFG 层,包括它如何处理 OSR。最后,我们描述 FTL 层如何工作。
DFG IR
强大的优化编译器最重要的组成部分是 IR。我们希望拥有最出色的 JavaScript 投机优化编译器,因此我们对 IR 有以下目标:
- IR 必须描述程序中所有对优化器感兴趣的部分。像其他高质量的优化 IR 一样,DFG IR 对数据流、别名、副作用、控制流和调试信息都有良好的支持。此外,它也善于表达分析数据、投机决策和 OSR。
- IR 必须是可变的。任何在首次将程序下层转换为 IR 时可以表达的内容,也应该在后续的某些优化过程中可以表达。我们倾向于在下层转换到 IR 期间做出的决策可以在后续通过优化进行细化。
- IR 必须具有一些验证支持。必须能够在验证器中捕获常见错误,而不是调试生成的代码。
- IR 必须是专用构建的。如果存在一个优化,其最全面的实现需要更改 IR 或其核心数据结构之一,那么我们必须能够在不征求任何人许可的情况下进行这种更改。
请注意,IR 的可变性与其描述能力以及验证的难易程度密切相关。任何试图将一段代码转换为另一段更好代码的优化,都需要能够确定新代码是否能有效替代旧代码。通常,IR 承载的信息越多,越容易验证,编写用于保护优化的分析就越容易。
让我们通过一个简单的例子来看看 DFG IR 是什么样的:
function foo(a, b)
{
return a + b;
}
这会产生如下字节码:
[ 0] enter
[ 1] get_scope loc3
[ 3] mov loc4, loc3
[ 6] check_traps
[ 7] add loc6, arg1, arg2
[ 12] ret loc6
请注意,只有最后两行(add 和 ret)是重要的。让我们看看从下层转换(lowering)这两条字节码指令得到的 DFG IR:
23: GetLocal(Untyped:@1, arg1(B<Int32>/FlushedInt32), R:Stack(6), bc#7)
24: GetLocal(Untyped:@2, arg2(C<BoolInt32>/FlushedInt32), R:Stack(7), bc#7)
25: ArithAdd(Int32:@23, Int32:@24, CheckOverflow, Exits, bc#7)
26: MovHint(Untyped:@25, loc6, W:SideState, ClobbersExit, bc#7, ExitInvalid)
28: Return(Untyped:@25, W:SideState, Exits, bc#12)
在此示例中,我们将 add 操作码下层转换为四个操作:两个 GetLocals 用于从栈中获取参数值(我们延迟加载它们,这是第一个需要它们的操作),一个投机性的 ArithAdd 指令,以及一个 MovHint 用于告知编译器的 OSR 部分关于 ArithAdd 的信息。ret 操作码仅被下层转换为一个 Return 操作。
在 DFG 术语中,指令通常被称为节点(nodes),但我们交替使用节点、指令和操作这些术语。DFG 节点同时是数据流图中的节点和控制流图中的指令,其语义定义为“仿佛”它们以特定顺序执行。

让我们更详细地考虑 ArithAdd(图 24)。这条指令很有趣,因为它正是 DFG 旨在优化的类型:它代表了一个动态且不纯粹(可能调用函数)的 JavaScript 操作,但在这里我们使用 Int32: 类型投机推断它没有副作用。这表明在做任何其他事情之前,这条指令会检查其输入是否为 32 位整数。请注意,DFG 指令的类型投机应理解为函数重载。ArithAdd 也允许两个操作数是双精度浮点数或其他类型的整数。就好像 ArithAdd 是一个 C++ 函数,它有接受一对整数、一对双精度浮点数等的重载。不可能为任何操作数添加任何类型投机,因为这可能导致不支持的指令重载。
这个 ArithAdd 的另一个有趣特性是,它确切地知道它来源于哪条字节码指令以及它将退出到哪里。这些是 IR 中的单独字段(语义和用于退出的来源),但当它们相等时,我们将其合并转储为一个,在此指令的情况下为 bc#7。
任何可能退出的 DFG 节点都将带有 Exits 标志。请注意,我们保守地设置此标志。例如,我们示例中的 Return 设置了此标志,并不是因为 Return 会退出,而是因为我们还没有发现有必要对该指令的退出分析进行更精确的处理。

DFG IR 可以同时被理解为一系列应按给定顺序“仿佛”执行的操作,以及一个带有反向指针的数据流图。我们运行示例的数据流图视图如图 25 所示。这种视图很有用,因为许多优化都关注于提出这样的问题:“哪些指令产生了此指令所消耗的值?” 这些数据流边是值在 DFG IR 中移动的主要方式。此外,以这种方式表示程序使得添加 SSA 形式变得自然,我们在 FTL 中就是这样做的。

DFG,无论是无 SSA 形式还是 SSA 形式,都构成了 DFG 和 FTL 编译器的主要部分。如图 26 所示,两个 JIT 都共享相同的前端,用于解析字节码和进行一些优化。区别在于 DFG 优化器之后发生的事情。在 DFG 层,我们直接发出机器码。在 FTL 层,我们转换为 DFG SSA IR(它几乎与 DFG IR 相同,但使用 SSA 表示数据流),并进行更多优化,然后通过另外两个优化器(B3 和 Assembly IR 或 Air)进行下层转换。剩余部分将讨论 DFG 和 FTL 编译器。关于 DFG 编译器的部分涵盖了 DFG 和 FTL 的共同部分。
DFG 编译器
DFG 编译器的目的是快速消除大量的类型检查。快速编译是 DFG 与 FTL 的区别特征。为了实现快速编译,DFG 缺少 SSA,只能进行非常有限的代码移动,并且对大多数优化(公共子表达式消除、寄存器分配等)使用块局部版本。尽管编译速度快,DFG 在两个重点领域表现出色:它如何处理 OSR 以及它如何使用静态分析。
本节将通过更详细地探讨以下三个概念来解释 DFG:
- OSR 退出作为编译器中的一级概念。
- 静态分析作为优化的主要驱动力。
- 快速编译,以便我们尽快获得优化的好处。
OSR 退出
OSR 的核心是通过让失败的检查侧向退出,从而扁平化控制流。OSR 是一项难以正确实现的优化。在概念层面进行推理尤其困难。本节旨在揭开 OSR 退出的神秘面纱。我们将解释 DFG 编译器处理 OSR 的方法,其中包括 DFG 层特有的部分以及与 FTL 共享的部分。FTL 部分将解释我们用于进行更激进优化的这种方法的扩展。
我们的讨论如下。首先,我们使用一个高层示例来说明 OSR 退出究竟是什么。接下来,我们将描述 OSR 退出在机器层面的含义,这将带我们深入了解优化编译器如何处理 OSR 的细节。我们将展示一个基于栈映射(stackmaps)的简单 OSR 退出 IR 概念,以说明我们试图实现的目标,然后我们将描述 DFG IR 如何压缩栈映射。最后,我们讨论 OSR 退出如何与观测点和失效集成。
高层 OSR 示例。为了开始揭开 DFG 退出的神秘面纱,让我们将其视为我们正在对一个 C 程序进行的优化。假设我们编写了这样的代码:
int foo(int* ptr)
{
int w, x, y, z;
w = ... // lots of stuff
x = is_ok(ptr) ? *ptr : slow_path(ptr);
y = ... // lots of stuff
z = is_ok(ptr) ? *ptr : slow_path(ptr);
return w + x + y + z;
}
假设我们想优化掉第二个 is_ok 检查。我们可以通过复制第一个 is_ok 检查之后的所有代码来实现这一点:一个副本静态地假设 is_ok 为真,而另一个副本则假设它为假或不做任何假设。这可能会使快速路径看起来像:
int foo(int* ptr)
{
int w, x, y, z;
w = .. // lots of stuff
if (!is_ok(ptr))
return foo_base1(ptr, w);
x = *ptr;
y = ... // lots of stuff
z = *ptr;
return w + x + y + z;
}
其中 foo_base1 是原始 foo 函数在第一个 is_ok 检查之后的部分。它将该点的活动状态作为参数,看起来像这样:
int foo_base1(int* ptr, int w)
{
int x, y, z;
x = is_ok(ptr) ? *ptr : slow_path(ptr);
y = ... // lots of stuff
z = is_ok(ptr) ? *ptr : slow_path(ptr);
return w + x + y + z;
}
我们在这里所做的就是 OSR 退出。我们通过在 !is_ok 时退出(尾调用 foo_base1)来优化快速路径上的控制流(移除一个 is_ok 检查)。OSR 退出需要:
- 退出点,本例中如
foo_base1。它应该是一个能够完成当前函数执行而不会陷入相同投机的东西。 - 退出时的活动状态,本例中如
ptr和w。没有它,退出目标就无法从我们离开的地方继续。
这就是高层级的 OSR 退出。我们正在尝试允许优化编译器发出检查,在失败时退出函数,以便编译器可以假设稍后不再需要相同的检查。
机器层面的 OSR。现在让我们看看 OSR 退出在较低层面是什么样子。图 27 显示了在特定字节码索引处的 OSR 示例。

OSR 的核心是替换当前的栈帧和寄存器状态(对应于优化层中的某个字节码索引),替换为不同的帧和寄存器状态(对应于分析层中的同一点)。这完全是关于将活动数据从一种格式洗牌到另一种格式,并跳转到正确的位置。
知道跳到哪里很容易:每个 DFG 节点(也称指令或操作)都有一个forExit,或简称为exit,的来源,它告诉我们要退出到哪个字节码位置。在内联的情况下,这甚至可能是一个字节码栈。
活动数据需要多费一些功夫。我们必须知道活动数据的集合是什么,以及它在分析层和优化层中的格式是什么。结果发现,知道活动数据集合是什么以及如何在分析层中表示它很容易,但从优化层中提取该数据却很困难。
首先让我们考虑什么是活动数据。图 27 中的示例表明,我们正在 add 处退出,并且在此之前有 loc3、loc4 和 loc8 是活动的。我们可以通过进行活跃性分析来确定任何字节码指令处的活动数据。JavaScriptCore 为此目的进行了优化的字节码活跃性分析。
请注意,分析层中的帧布局是对字节码状态的有序表示。具体来说,locN 仅表示 framePointer - 8 * N,而 argN 仅表示 framePointer + FRAME_HEADER_SIZE + 8 * N,其中 FRAME_HEADER_SIZE 通常为 40。分析层中函数之间的帧布局唯一区别在于帧大小,这由每个字节码函数中的一个常量决定。给出帧指针和字节码虚拟寄存器名称,总能找出分析层将在栈上何处存储该变量。这使得很容易弄清楚如何将任何字节码活动状态转换为 Baseline JIT 或 LLInt 所期望的状态。
困难的部分是优化层(optimizing tier)的状态。优化编译器可能会:
- 以任何顺序分配栈。即使变量在栈上,它也可能在任何位置。
- 对变量进行寄存器分配。在这种情况下,栈上可能没有任何位置包含该变量的值。
- 对变量进行常量折叠。在这种情况下,栈上或寄存器文件中可能不存在包含该变量值的任何位置。
- 以某种创造性的方式表示变量的值。例如,您的程序可能有一个类似于
x = y + z的语句,但编译器选择从不实际发出加法,除非在用到时才进行。这在 x86 或 ARM 上的模式匹配指令选择中很容易发生,因为某些指令(如内存访问)可以作为地址计算的一部分免费执行一些加法。我们对对象分配做了一个更激进的版本:有些程序变量在语义上指向一个对象,但由于我们的编译器很智能,我们从未实际分配任何对象,并且对象的字段可能已寄存器分配、常量折叠或以创造性的方式表示。
我们希望允许优化编译器做这样的事情,因为我们希望 OSR 退出能够促进优化而不是阻碍优化。事实证明这很棘手:我们如何才能让优化编译器执行它喜欢的所有优化,同时仍能告诉我们如何恢复字节码状态?
从优化编译器中提取优化状态到字节码状态转换的技巧是利用原始字节码到 IR 的转换。SSA 类的 IR(如 DFG IR)和字节码之间的主要区别在于它表示数据流关系而不是变量。字节码说 add x, y, z,而 DFG IR 会有一个 Add 节点,指向产生 y 和 z 的节点(如图 25 所示)。从字节码到 DFG IR 的转换伪代码如下:
case op_add: {
VirtualRegister result = instruction->result();
VirtualRegister left = instruction->left();
VirtualRegister right = instruction->right();
stackMap[result] = createAdd(
stackMap[left], stackMap[right]);
break;
}
这使用了将基于变量的 IR 转换为基于数据流的 IR 的标准技术:转换器维护一个从源 IR 中的变量到目标 IR 中的数据流节点的映射。我们暂时称之为 stackMap。通过模拟字节码的数据流来处理每个字节码指令:我们从 stackMap 中加载左右操作数,这为我们提供了这些局部变量值的 DFG 节点。然后我们创建一个 ArithAdd 节点并将其存储到 stackMap 中的结果局部变量中,以模拟字节码希望将结果存储到该局部变量的事实。图 28 显示了在我们的运行示例中对 add 字节码运行此操作的前后。

add 运行 SSA 转换之前和之后的 stackMap 示例,以及围绕结果 ArithAdd 的数据流图的插图。stackMap(像我们在这些示例中所做的那样,裁剪到字节码的活跃性)表示在字节码执行的任何时刻可能需要恢复的活跃状态集。它告诉我们,对于每个活跃的字节码局部变量,要使用哪个 DFG 节点来恢复该局部变量的值。支持 OSR 的一个简单方法是为每个可能退出的 DFG 节点提供一个数据流边,指向活跃性裁剪后的 stackMap 中的每个节点。
这不是 DFG 实际做的事情;DFG 节点没有用于栈映射的数据流边。字面上这样做会因为内存使用量而过于昂贵,因为基本上每个 DFG 节点都可能退出,而且栈映射有 O(活跃状态) 的条目。DFG 的实际方法基于栈映射的增量压缩。但是,值得仔细考虑这种未压缩栈映射方法将如何工作,因为它构成了 FTL 策略的一部分,并且它为理解 DFG 更复杂的方法提供了一个良好的心智模型。因此,我们将花一些时间描述 DFG IR,就好像它真的有栈映射一样。然后我们将展示如何使用增量压缩来表达栈映射。
使用未压缩栈映射的 OSR 退出。 想象一下 DFG 节点确实有用于栈映射的额外操作数。那么我们将有一个像下面的 ArithAdd,假设 bc#42 是退出源,并且 loc3、loc4 和 loc8 是活跃的,如图 27 和 28 所示。
c: ArithAdd(@a, @b, loc3->@s, loc4->@a, loc8->@b, bc#42)
在这种 IR 中,我们让 ArithAdd 的前两个操作数按预期方式行为(它们是加法的实际操作数),而我们将所有其他操作数视为栈映射。退出源 bc#42 是一个控制流标签。总而言之,这告诉 ArithAdd 在何处退出(bc#42)以及栈映射(@s、@a 和 @b)。编译器将 ArithAdd 和栈映射操作数视为 ArithAdd 从编译器正在编译的函数中存在一个
一种思考方式是 C 伪代码。我们是说 ArithAdd 和任何其他可能退出的指令的语义就好像它们在执行任何效果之前做了以下事情:
if (some conditions)
return OSRExit(bc#42, {loc3: @s, loc4: @a, loc8: @b});
其中 `return` 语句是从已编译函数中的提前返回。因此,这通过尾调用(跳转到) `OSRExit` 来终止已编译函数的执行。该操作将控制权转移到 bc#42 并传递给定的栈映射。

这在编译器中很容易建模。我们不分配任何控制流构造来表示条件检查和旁路退出,而是在分析 ArithAdd 或任何其他可能退出的节点时隐式地假设它存在。请注意,在 JavaScript 中,基本上每条指令都可能退出,JavaScriptCore 的 “可能退出” 分析对大多数操作默认为 true。图 29 展示了这种样子。我们将有三种控制流边,而不是通常的两种:
- 基本块之间的正常控制流边。这是您通常认为的“控制流”。这些边在 IR 中显式表示,也就是说,每个块都有一个实际的数据结构(通常是后继向量和前驱向量)来指示它参与的控制流边。
- 块内指令的隐式直通控制流。这对于带有基本块的编译器是标准的。
- 由于 OSR 产生的一种新型控制流边,它从块中的指令指向 OSR 退出着陆点。这意味着稍微改变了基本块的定义。通常,基本块的唯一后继是控制流图中的那些。我们的基本块也有一堆 OSR 退出后继。这些后继不存在于控制流图中,但由于退出指令中存在的退出源,我们有它们的名称。指向这些退出源的边从块的中间退出,因此它们可能会在块末端之前终止块的执行。
编译器将 OSR 着陆点理解为具有以下行为:
- 它结束 DFG IR 中此函数的执行。这是关键,因为它意味着我们的控制流图中没有必须考虑退出后果的合并点。
- 它可能读写整个世界。DFG 必须关心读取(因为它们可能观察到退出之前发生的一切)但不需要关心写入(因为它们影响退出 DFG 之后的执行)。
- 它读取一组值,即作为栈映射传递的那些值。
这种理解是抽象的,所以编译器只会假设最坏情况(退出后内存中的每个位置都被读写,并且栈映射中所有值的所有位都被刻石)。
这种方法很棒,因为它允许在编译 OSR 退出时精确重建基线状态,并且它基本上不会抑制优化,因为它“仅仅”涉及向控制流图添加一种新的隐式控制流边。
这种方法允许在退出时简单地重建状态,因为编译 DFG 节点的后端会以处理所有其他边的方式来处理栈映射数据流边(例如我们示例中的 loc3->@s)。因此,在 ArithAdd 处,后端将知道要使用哪些寄存器、栈槽或常量值来具体化栈映射值。它知道如何这样做,原因与它知道如何具体化两个实际的加法操作数相同。
如果我们考察编译器希望执行的最常见的优化,我们会发现只有一种主要优化受到这种 OSR 退出方法的严重抑制。我们先回顾一下这种方法不会破坏的优化。仍然可以在 ArithAdd 上执行公共子表达式消除 (CSE)。仍然可以将其从循环中提升出来,尽管如果这样做,我们就必须编辑退出元数据(退出目的地和栈映射将不得不被覆盖为它们在循环预头中的任何值)。仍然可以以许多重要的方式将 ArithAdd 建模为纯粹的,例如,如果 ArithAdd 之前和之后有两个加载,那么我们可以假设它们是冗余的。ArithAdd 只能在退出路径上产生影响,在这种情况下,第二次加载无关紧要。如果 ArithAdd 不可达,仍然可以消除它。
我们无法轻易做到的唯一事情是编译器所谓的
int tmp = a + b;
// nobody uses tmp.
- 即使加法结果未使用,也必须假定 ArithAdd 的推测检查是活跃的。我们可能会对后续检查进行一些优化,因为我们发现它被此 ArithAdd 执行的检查所涵盖。这是我们对 OSR 检查所做的一项相当基础的优化,也是 OSR 最终扁平化控制流的原因。但我们不费心记录此 ArithAdd 的检查何时用于解锁后续优化,因此我们必须假设某些后续操作已经依赖于 ArithAdd 执行其所有检查。这意味着:假设某个操作 A 的结果被一个死操作 B 使用。B 仍然必须对其输入执行它正在执行的任何检查,这将使 A 保持活跃,即使 B 已死。这对 ArithAdd 来说尤其具有破坏性,因为 ArithAdd 通常会执行溢出检查。您必须进行加法才能检查溢出。因此,ArithAdd 从来都不是真正的死代码。考虑另一种选择:如果我们不考虑 ArithAdd 的溢出检查对抽象状态的影响,那么我们将无法执行我们的 范围分析,该分析使用从溢出检查推断出的信息来删除数组边界检查,反之亦然。
- ArithAdd 几乎肯定会出现在某些后续操作的 stackmap 中,就像 DFG 程序中的几乎每个节点一样,除非该节点代表字节码中已死的内容。在字节码中死亡的可能性特别小,因为在字节码中我们必须假设一切都是多态的并且可能产生副作用。那么
add实际上并没有死:毕竟它可能是一个带有函数调用的循环。
DFG 和 FTL 仍然执行 DCE,但这很困难,通常只对最昂贵的构造才值得。对于那些我们可以证明结果未被使用的罕见情况,我们支持将操作衰减到仅保留其检查。我们还支持沉降到 OSR,其中一个操作被一个
总结对优化的影响:我们仍然可以执行大多数优化。受影响最严重的优化是 DCE,但即便如此,我们也找到了在最重要的情况下使其工作的方法。
这种简单方法的唯一真正缺点是重复:几乎每个 DFG 操作都可能退出,并且退出时的状态很容易有数十或数百个变量,特别是如果我们进行了大量内联。将栈映射存储在每个 DFG 节点中将导致编译器内存使用和处理时间出现 O(n2) 爆炸。请注意,这种爆炸的发生有点像 JavaScript 特有的问题,因为 JavaScript 在每次操作(即使是简单的操作,如 add 或 get_by_id)我们必须进行的推测数量上都是不寻常的。如果推测是我们很少做的事情,就像在 Java 中它们主要用于虚方法调用一样,那么简单的方法就可以了。
DFG IR 中的栈映射压缩。 我们解决重复栈映射尺寸爆炸的方案是使用增量编码。栈映射变化不大。在我们的运行示例中,add 只是销毁了 loc8 并定义了 loc7。销毁可以通过分析字节码发现,因此无需记录。我们只需要记录此操作定义了 loc7 为 ArithAdd 节点。
我们使用名为 MovHint 的操作作为我们的增量编码。它告诉哪个字节码变量由哪个 DFG 节点定义。例如,让我们看看我们在图 28 中为 add 发出的 MovHint:
c: ArithAdd(@a, @b, bc#42)
MovHint(@c, loc7, bc#42)
我们需要仔细考虑如何表示 MovHints,以便它们易于保留和修改。我们的方法是两方面的:
- 我们将 MovHint 视为一个存储效应。
- 我们明确标记 IR 中我们期望基于从 MovHint 增量构建的状态可以合法退出的点。
我们首先看看如何利用存储效应的概念来让编译器理解 MovHint。想象一个假设的 DFG IR 解释器,以及它如何执行 OSR 退出。关键思想是,在该解释器中,DFG 程序的状态不仅包括从 DFG 节点到其值的映射,还包括一个 OSR 退出状态缓冲区,其中包含按字节码变量名称索引的值。该 OSR 退出状态缓冲区正好包含分析层将使用的栈帧。MovHint 的解释器语义是将其操作数的值存储到 OSR 退出状态缓冲区中的某个槽位。这样,DFG 解释器能够始终与程序状态的优化表示同步维护一个最新的字节码栈帧。尽管不存在这样的解释器,但我们确保我们编译 MovHint 的方式会产生与该解释器所做的事情语义一致的结果。
MovHint 不会被编译成存储指令。但任何处理或遇到 MovHints 的阶段都只需将其理解为对某个抽象位置的存储。它是一个存储指令的事实意味着它不是死代码。它是一个存储指令的事实意味着它可能需要与其他存储或加载指令进行排序。许多我们为了在编译器优化过程中可靠地保留 MovHints 所需的理想属性,都自然而然地来自于我们告诉所有阶段它只是一个存储指令的事实。
编译器为 MovHint 生成零代码。相反,我们结合字节码活跃性分析和 MovHints 的
DFG IR 的 OSR 方法意味着 OSR 退出在 DFG IR 的某些点是可能的,而在其他点则不是。考虑一些示例:
- 一条字节码指令可能定义多个字节码变量。当降低到 DFG IR 时,我们会有两个或更多的 MovHints。在这些 MovHints 之间不可能有退出,因为 OSR 退出状态在那一点上只被部分更新。
- 在执行了可观察效应(例如存储到 JS 对象属性)的 DFG 操作之后但在其相应的 MovHint 之前退出是不可能的。如果我们退出到当前退出源,我们将再次执行该效应(这是错误的),但如果退出到下一个退出源,我们将忽略将结果存储到正确的字节码变量中。
我们需要让 DFG 转换很容易知道在代码的任何点插入可能退出的操作是否合法。例如,我们可能想要编写在每次使用 @x 之前添加检查的工具。如果该使用是 MovHint,那么我们需要知道在那个 MovHint 之前添加那个检查可能是不可以的。我们的方法基于这样的观察:字节码指令的降低会在 DFG IR 中产生该指令的两个执行阶段:
- 推测阶段:在字节码执行开始时,推测既必要又可能。推测是必要的,因为这些推测守护着我们在该字节码指令的后续 DFG 节点中所做的优化。推测是可能的,因为我们还没有执行指令的任何副作用,所以我们可以安全地退出到该字节码指令的开头。
- 效应阶段:一旦我们执行了任何效应,我们就无法再进行任何推测。这种效应可以是实际效应(如存储到属性或进行调用)或 OSR 效应(如 MovHint)。
为了帮助验证这一点,DFG IR 中的所有节点都有一个 exitOK 标志,用于记录它们是否认为自己处于推测阶段(exitOK 为 true)或者是否认为自己可能处于效应阶段(exitOK 为 false)。如果我们不确定,将 exitOK 设置为 false 是可以的,但要将 exitOK 设置为 true,我们必须完全确定。IR 验证检查 exitOK 必须在执行效应的操作后变为 false,并且只有在规定的点(例如退出源发生变化,表明我们已经结束了一个指令的效应阶段并开始了下一个指令的推测阶段)才再次变为 true,并且任何可能退出的节点都不能将 exitOK 设置为 false。这个验证器有助于防止错误,例如处理可以降低到多个有副作用的 DFG 节点的字节码操作时。一个例子是当 put_by_id(即类似于 o.f = v)被推断为是一个转换(属性 f 不存在于 o 上,因此我们需要添加它),这导致两个效应:
- 将值
v存储到属性o.f的内存位置。 - 改变
o的结构以指示它现在拥有一个f。
DFG IR 中的这段代码看起来会是这样:
CheckStructure(@o, S1)
PutByOffset(@o, @v, f)
PutStructure(@o, S2, ExitInvalid)
请注意,PutStructure 将被标记为 ExitInvalid,这是我们在 IR 转储中表示 exitOK 为 false 的方式。如果 PutStructure 没有设置 exitOK 为 false,将导致验证错误,因为 PutByOffset(在它之前)是一个副作用。这阻止我们犯错误,例如将 @o 的所有用途替换为可能推测的操作,例如:
a: FooBar(@o, Exits)
CheckStructure(@a, S1)
b: FooBar(@o, Exits)
PutByOffset(@b, @v, f)
c: FooBar(@o, Exits)
PutStructure(@c, S2, ExitInvalid)
在这个例子中,我们使用了一些新的 FooBar 操作,它可能会退出,作为 @o 的过滤器。以这种方式对代码进行插桩可能看起来很荒谬,但这是 DFG IR 的目标:
- 允许将节点的使用替换为产生等效值的其他节点的使用。让我们假设 FooBar 是一个恒等操作,它也做一些可能退出的检查。
- 允许在任何地方插入新节点。
因此,这里唯一的错误是 @c 紧跟在 PutByOffset 之后。验证器会抱怨它没有被标记为 ExitInvalid。它应该被标记为 ExitInvalid,因为前一个节点 (PutByOffset) 具有副作用。但是如果你给 @c 添加 ExitInvalid,那么验证器会抱怨一个节点可能在 ExitInvalid 的情况下退出。任何尝试插入这种 FooBar 的阶段都将拥有所需的所有 API,以意识到它将遇到这些故障。例如,它可以询问它要插入自身之前的节点 (PutStructure) 是否具有 ExitInvalid。由于它是 ExitInvalid,我们可以做以下任何一件事,而不是将 @c 插入到 PutStructure 之前:
- 我们可以使用其他做 FooBar 几乎相同工作但没有退出的节点。
- 我们可以更早地插入 @c,这样它仍然可以退出。
我们来看看第二种选择会是什么样子:
a: FooBar(@o, Exits)
CheckStructure(@a, S1)
b: FooBar(@o, Exits)
c: FooBar(@o, Exits)
PutByOffset(@b, @v, f)
PutStructure(@c, S2, ExitInvalid)
通常,处理 !exitOK 代码区域只需如此。
请注意,在某些情况下,例如 FooBar 绝对需要在副作用之后进行检查,DFG IR 确实支持 退出到 字节码 指令 的 中间。 在某些情况下,我们别无选择,只能使用该功能。 这涉及引入额外的非字节码状态,该状态可以通过 OSR 退出传递,在副作用之前/之后发出 OSR 退出状态更新,使用一个退出源指示我们正在退出到字节码指令执行中间的某个检查点,并实现在 OSR 退出期间从检查点开始执行字节码的方式。这绝对是可能的,但不是我们希望每次 DFG 节点需要执行副作用时都必须做的事情。因此,规范的 DFG IR 使用意味着在某些字节码指令执行期间存在 !exitOK 阶段(即副作用阶段)。
观察点和失效。 到目前为止,我们已经考虑了编译器发出的检查的 OSR 退出。但 DFG 编译器也允许通过在 JavaScript 堆中设置观察点来推测。如果它发现某些理想的东西——例如 Math.sqrt 指向 sqrt 内联函数——它通常可以在不发出检查的情况下将其纳入优化。唯一需要的是编译器在其想要证明的事物上设置一个观察点(即 Math 和 sqrt 不会改变)。当观察点触发时,我们希望使已编译代码失效。这意味着使代码永远不再运行:
- 不再有新的函数调用会转到优化版本,并且
- 所有返回到该优化函数的调用都被重定向到基线代码。
确保新调用避免优化代码很容易:我们只需修补所有对函数的调用,使其转而调用分析后的代码(如果可用,则为 Baseline,否则为 LLInt)。处理返回是有趣的部分。
处理失效的一种方法是遍历栈以查找所有返回到失效代码的返回,并将这些返回重新指向 OSR 退出。由于我们使用了副作用阶段,这会给我们带来麻烦:在 DFG IR 执行的一个阶段中,可能连续发生多个副作用而无法退出。因此,DFG 处理失效的方法是让当前字节码指令的剩余副作用在优化代码中完成执行,然后在下一条字节码指令开始之前立即触发 OSR 退出。

DFG IR 中的失效功能通过 InvalidationPoint 指令启用,该指令由 DFG 前端自动插入到每个退出源的开始处,如果该退出源之前有可能导致观察点触发的副作用。InvalidationPoint 被建模为条件 OSR 退出,并被赋予一个 OSR 退出跳转标签,就像有一个分支将其链接起来一样。但是,InvalidationPoint 不会发出代码。相反,它记录了机器代码中 InvalidationPoint 将被发出的位置。当一个函数失效时,所有这些标签都会被无条件跳转到 OSR 退出所覆盖。
图 30 展示了 OSR 退出概念(如推测和副作用阶段)如何与 InvalidationPoint 结合用于三条假想字节码指令。我们故意使用荒谬的指令,因为我们想展示各种可能性。让我们详细考虑 wat。wat 的第一个 DFG IR 节点是 InvalidationPoint,因为它之前的字节码 (foo) 有副作用,所以自动插入。然后 wat 执行 CheckArray,它可能退出但没有副作用。因此,下一个 DFG 节点 Wat 仍然处于推测阶段。Wat 在 DFG IR 中处于一个完美的位置:它被允许执行推测和副作用。它可以执行推测,因为 wat 的退出源的任何前一个节点都没有执行副作用。它也可以执行副作用,但之后它的节点(Stuff 和 Derp)不能再推测。但是,它们可以执行更多的副作用。由于 wat 有副作用,InvalidationPoint 会立即插入到下一个字节码 (bar) 的开头。请注意,在此示例中,Foo、Wat 和 StartBar 都处于完美位置(它们可以退出并产生副作用)。由于 Stuff、Derp 和 FinishBar 处于副作用区域,如果它们尝试推测,编译器将断言。
请注意,InvalidationPoint 会使代码布局变得棘手。在 x86 上,失效使用的无条件跳转是五个字节。因此,我们必须确保失效标签之后的五个字节内没有其他跳转标签。否则,失效可能会导致其中一个标签指向一个 5 字节失效跳转的中间。我们通过添加 nop 填充来解决此问题,以在用于失效的标签和任何其他类型的标签之间创建至少 5 字节的间隙。
总结来说,DFG IR 为 OSR 退出提供了广泛的支持。我们有紧凑的增量编码来表示 OSR 退出状态的变化。退出目的地被编码为每个 DFG 节点中的退出源字段。由于失效而导致的 OSR 退出通过自动插入 InvalidationPoint 来处理。
静态分析
DFG 使用大量静态分析来补充其推测方式。本节涵盖了 DFG 中影响特别大的三种静态分析:
- 我们使用
预测传播 ,根据某些值的分析数据来填充所有值的预测类型。这有助于我们确定在哪里进行类型推测。 - 我们使用
抽象解释器 (在 JavaScriptCore 行话中简称AI )来发现冗余的 OSR 推测。这有助于我们发出更少的 OSR 检查。DFG 和 FTL 的管道都包含多个优化阶段,可以发现并删除冗余检查,但抽象解释器是最强大的一个。抽象解释器是 DFG 层的主要优化,并在 FTL 中经过少量增强后重用。 - 我们使用
clobberize 来获取 DFG 操作的别名信息。给定一个 DFG 指令,clobberize 可以描述其别名属性。在几乎所有情况下,该描述在时间和空间上都是 O(1) 的。该描述隐式地描述了一个丰富的依赖图。
预测传播器和抽象解释器都通过前向传播类型信息来工作。它们都建立在 抽象解释 的原理之上。理解至少部分理论很有用,所以我们做一个简短的回顾。抽象解释器类似于普通解释器,但它们以抽象方式描述程序状态,而不是考虑精确值。一个 Kildall 经典的例子 涉及只记住哪些变量具有已知的常量值,并忘记任何可能具有多个值的变量。抽象解释器运行到
现在我们来详细介绍这两种抽象解释器和别名分析。
预测传播。 预测传播器的抽象状态包括变量到推测类型(图 13)的映射。推测类型是基本类型的集合。这些集合表示一个值被预测具有哪些类型。预测传播器不敏感流;它对所有程序语句都只有一个抽象状态副本。因此,每个语句的执行都会考虑整个输入类型集合(即使来自无法到达我们的程序语句),并将结果与结果变量的推测类型结合起来。请注意,预测传播器的输入是数据流 IR,因此对同一变量的多次赋值不一定会合并。
预测传播器不必是健全的。预测传播器错误的最终结果是,我们要么:
- 进行过于强烈的推测,导致频繁退出并重新编译。
- 进行过于弱的推测,导致程序永远运行得比可能的速度慢。
请注意,第二种结果通常更糟。重新编译然后推测更少至少意味着程序最终以最优的推测集运行。推测过于弱并且从不重新编译意味着我们永远无法达到最优。
抽象解释器。 DFG AI 是 DFG 层最重要的优化。尽管 JavaScriptCore 中有许多抽象解释器,但就总代码量和客户端数量而言,这个是最大的——因此对我们而言,它就是
DFG AI 的抽象状态包含变量到 抽象值 的映射,其中每个抽象值表示变量可能拥有的 JSValue 的集合。这些集合描述了我们通过过去的检查所证明的类型信息。我们在控制流合并点合并抽象状态。不动点后的解是最小解(具有不动点的最小可能集合)。DFG AI 是流敏感的:它为每个指令边界维护一个单独的抽象状态。AI 一次性查看整个控制流图,但不查看当前编译的函数及其内联的内容。AI 也是 稀疏条件 的。
DFG 抽象值表示有四个子值:
- 该值是否已知为常量,如果是,该常量是什么。
- 可能的类型集合(即 SpeculatedType 位图,如图 13 所示)。
- 该值指向的对象可能拥有的索引类型(也称为数组模式)集合。
- 该值指向的对象可能拥有的结构集合。该集合具有特殊的无限集合能力。
最后两个子值可以被副作用修改。DFG AI 假设所有对象都已逸出,因此如果发生可能改变索引类型和结构的副作用,那么我们必须
我们对这四个子值的解释如下:抽象值表示位于这四个子值集合交集中的 JSValue 集合。这意味着在解释抽象值时,我们可以选择只查看我们感兴趣的子值。例如,消除结构检查的优化只需要查看结构集字段。

DFG AI 同时为我们提供了常量和类型传播。类型传播用于移除检查、简化检查,并将动态操作替换为更快的版本。
图 31 展示了 DFG AI 允许我们消除的检查示例。请注意,除了消除明显的同一基本块检查冗余(图 31(a))之外,AI 还允许我们消除跨多个块的冗余(如图 31(b) 和 (c))。例如,在图 31(c) 中,AI 能够证明 @x 在基本块 #7 的顶部是一个 Int32,因为它合并了来自 BB#5 和 #6 的 @x 的 Int32 状态。检查消除通常通过修改 IR 来执行,以便后续阶段无需询问 AI 就能知道哪些检查是真正必要的。
DFG AI 有许多客户端,包括 DFG 后端和 FTL 到 B3 的降低。成为 AI 客户端意味着可以访问它对任何程序点上任何变量或 DFG 节点可能拥有的 JSValue 集合的估计。后端利用这一点来简化未被移除的检查。例如,后端可能会看到一个 Object-or-Undefined,询问 AI,然后发现 AI 已经证明它必须是对象或字符串。后端将能够结合这两条信息,只发出一个 is-object 检查,而忽略该值是 undefined 的可能性。
类型传播还允许我们将动态堆访问替换为内联访问。DFG IR 中大多数快速属性访问都源于内联缓存反馈告诉我们应该推测,但有时 AI 能够证明比分析器告诉我们的更强的东西。这在内联代码中尤其可能发生。
Clobberize。 Clobberize 是 DFG 用来描述指令可能读取和写入程序状态的哪些部分的别名分析。这使我们能够看到指令之间除了数据流所表达的依赖关系之外的额外依赖关系。依赖信息告诉编译器哪些指令重新排序是合法的。Clobberize 在 DFG 和 FTL 中都有许多客户端。在 DFG 中,它用于公共子表达式消除,例如。
为了理解 clobberize,值得考虑编译器需要记住程序控制流的哪些部分。控制流图向我们展示了程序的一种可能排序,我们知道这种排序是合法的。但 DFG 和 FTL 层都希望移动代码。DFG 层主要只在基本块内移动代码,而不是在它们之间移动,而 FTL 层也可以在基本块之间移动代码。即使有了 DFG 的块局部代码移动,也需要知道的不仅仅是程序的当前排序。还需要知道如何更改该排序。
其中一些问题已由数据流图解决。DFG IR 提供了一个数据流图,显示了指令之间
- 内存存储。
- 内存加载。
- 可能引起任何副作用的调用。
- OSR 效应(如 MovHint)。
数据流边不涉及这些依赖关系。数据流也无法判断哪些指令具有任何副作用。因此,如果指令具有副作用,数据流图就无法告诉我们指令的有效排序。
如何处理由副作用引起的依赖关系这个问题与 JavaScript 编译——以及一般的推测编译——尤其相关,因为推测为我们提供了别名信息的精确度。例如,尽管 JavaScript 的 o.f 操作可能产生任何副作用,但在推测之后我们通常知道它只能影响名为 f 的属性。此外,JavaScript 导致我们必须发出大量对内部对象模型的字段的加载,并且知道这些加载何时冗余以便尽可能多地删除它们是很重要的。因此,我们需要能够询问任何可能访问内部 VM 状态的操作,该状态是否可能被任何其他操作修改,并且我们希望这个答案尽可能精确,同时接近 O(1) 的时间复杂度。
Clobberize 是一种静态分析,通过告知我们指令如何重新排序的约束来增强数据流和控制流图。Clobberize 的妙处在于它避免将依赖信息存储在指令本身中。因此,尽管编译器可以随时通过运行分析来查询依赖信息,但它无需做任何事情来维护它。

World 的子集,World 又细分为 Heap、Stack 和 SideState。例如,JS 函数调用表示它们 write(Heap) 和 read(World)。Heap 的子堆包括像 JSObject_butterfly 这样的东西,它们指的是 JSC 对象模型内部的字段,不直接对用户可见,以及像 NamedProperties 这样的东西,这是一个包含函数访问的每个命名属性的子堆。对于每个 DFG 指令,clobberize 报告零个或多个读或写。每个读或写说明它正在访问哪个 抽象堆。抽象堆是内存位置的集合。对抽象堆的读(或写)意味着程序将从该抽象堆中的零个或多个实际位置读(或写)。抽象堆形成一个层次结构,World 位于顶部(图 32)。对 World 的写意味着该效果可以写入任何内容,因此任何读都可能看到该写。层次结构可以非常具体。例如,GetByOffset 和 PutByOffset 这样的完全推断的直接属性访问形式报告它们分别读写一个命名属性的抽象堆。因此,对不同名称属性的访问被认为是不会产生别名的。如果其中一个堆是另一个的后代,则这些堆被认为是别名的。
值得欣赏的是,clobberize 与控制流相结合,只是一种编码依赖图的方式。为了从 clobberize 信息构建依赖图,我们应用以下规则。如果指令 B 在控制流中出现在指令 A 之后,那么我们认为 B 对 A 有一个依赖边(B 依赖于 A),如果:
- B 读取的任何堆与 A 写入的任何堆重叠,或者
- B 写入的任何堆与 A 读取或写入的任何堆重叠。
反之,任何依赖图都可以使用 clobberize 来表达。一个荒谬但正确的表示将涉及为依赖图中的每条边提供其自己的抽象堆,并让边的源写入堆,而汇读取堆。但是,使 clobberize 成为依赖图如此高效表示的原因是,我们尝试表示的每个依赖都可以通过对少量抽象堆的读写直观地描述。
这些抽象堆要么是具体的内存位置集合(例如,“foo”抽象堆是用于表示名为“foo”的属性值的内存位置集合),要么是隐喻性的。让我们探讨一些抽象堆的隐喻性用法:
- MovHint 想要表达它不是死代码,它必须与其他 MovHints 排序,并且它必须与任何实际的程序副作用排序。我们在 clobberize 中通过让 MovHint 写入
SideState来表达这一点。SideState是World的一个子堆,但与其他事物不相交,并且我们让任何希望与 OSR 退出状态排序的操作读取或写入与SideState重叠的内容。请注意,DFG 假设可能退出的操作隐式地read(World),即使 clobberize 没有这样说,因此 MovHint 对SideState的写入确保了与退出的排序。 - NewObject 希望表示将其从循环中提升出来是无效的,因为 NewObject 的两次连续执行可能会产生不同的结果。但 NewObject 并非会污染整个世界;例如,如果我们在 NewObject 的两侧对同一属性进行两次访问,那么我们希望第二次访问被消除。DFG IR 中有许多 NewObject 类的操作也具有此行为。因此,我们引入了一个名为
HeapObjectCount的新抽象堆,并表示 NewObject 象征性地递增(读写)HeapObjectCount。HeapObjectCount被视为Heap的子堆,但它与描述任何 JS 可见状态的子堆是分离的。这足以阻止 NewObject 的提升,同时仍然允许其周围发生有趣的优化。

clobberize 和控制流图的结合提供了一种可扩展且直观的表达依赖图的方式。它之所以可扩展,是因为我们实际上不必表达任何边。例如,考虑一个可以读取任何命名 JavaScript 属性的动态访问指令,例如图 33 中的 Call 指令。Clobberize 可以在 O(1) 的空间和时间复杂度内表示这一点。但是,依赖图必须从该指令创建一条边到任何在其之前或之后访问任何命名属性的指令。简而言之,clobberize 提供了依赖图的好处,而无需分配内存来表示边。
这些抽象堆也可以 高效地收集成一个集合,我们用它来总结基本块和循环的别名效应。
总而言之,DFG 非常重视静态分析。推测决策是结合了分析和预测传播抽象解释器做出的。此外,我们有一个用于优化的抽象解释器,简称为 DFG 抽象解释器,它作为冗余检查消除的主要引擎。抽象解释器非常适合 DFG,因为它为我们提供了一种向前传播类型信息的方法。最后,DFG 使用 clobberize 分析来描述依赖关系和别名。
快速编译
DFG 的设计旨在快速编译,以便快速实现 OSR 推测的优势。为了帮助减少编译时间,DFG 专注于它执行的优化以及执行方式。迄今为止讨论的静态分析和 OSR 退出优化代表了 DFG 最强大的功能。DFG 对其他一切(如指令选择、寄存器分配和删除非检查的冗余代码)都采取了快速而粗糙的处理方式。受益于编译器在这些优化方面做得好的函数,如果它们运行时间足够长以升级到 FTL,它们将获得这些优化。
DFG 对快速编译的关注是自然形成的,是许多独立的吞吐量-延迟权衡的结果。最初,JavaScriptCore 只有 Baseline JIT,后来 Baseline 作为分析层,DFG 作为优化层。在此期间,DFG 经历了显著演进,并在 FTL 引入后经历了进一步演进。虽然没有一个单一的决定导致了 DFG 当前的设计,但我们认为它最显著地受到了短时间运行基准测试的调优和 FTL 引入的影响。
DFG 针对多样化的工作负载进行了调优。一方面,它针对长时间运行的测试进行了调优,其中推测编译器获得了一整秒的免费预热时间(例如旧的 V8 基准测试,它们以 Octane 和 JetStream 的形式存在,尽管没有免费预热),但另一方面,它也针对 SunSpider 和页面加载测试等较短时间运行的基准测试进行了调优。SunSpider 侧重于在非常短的时间内运行的小型程序,几乎没有预热的机会。比 DFG 进行更多优化的编译器往往在 SunSpider 上输给它,因为它们在 SunSpider 完成运行之前未能完成优化。我们继续使用与 SunSpider 精神相似的测试,如 Speedometer 和 JetStream。Speedometer 具有相似的代码大小与运行时间比,因此与 SunSpider 一样,它从 DFG 中受益匪多。JetStream 包含 SunSpider 的一个子集,并在所有其他测试中都非常强调短时间运行的代码。这并不是说我们不关心长时间运行的代码。只是我们改进 DFG 的方法是尝试使用相同的引擎在短时间运行和长时间运行的事物上都获得加速。由于任何长时间运行的优化都会使短时间运行的测试性能下降,我们通常避免向 DFG 添加任何长时间运行的优化。但我们确实添加了许多复杂优化的廉价版本,在短时间运行和长时间运行的工作负载上都提供了可观的加速。
FTL 的引入巩固了 DFG 作为优化较少编译器的地位。只要 DFG 能够快速生成相当不错的代码,我们就可以将大量昂贵的优化放入 FTL 中。FTL 漫长的编译时间意味着许多程序运行时间不足以从 FTL 中受益。因此,DFG 旨在为这些程序提供推测性优化提升,所需时间远少于类似 FTL 的编译器。想象一个只有一个优化编译器的虚拟机。除非那个编译器编译速度与 DFG 一样快,并且生成的代码与 FTL 一样好,否则它最终在某些工作负载上会比 JavaScriptCore 稳定地慢。如果那个编译器编译速度与 DFG 一样快但没有 FTL 的吞吐量,那么任何运行时间足够长的程序在 JavaScriptCore 中都会运行得更快。如果那个编译器生成的代码与 FTL 一样好但编译速度比 DFG 慢,那么任何运行时间足够短以至于可以分层到 DFG 但不能分层到那个编译器的程序在 JavaScriptCore 中都会运行得更快。JavaScriptCore 拥有多个编译器层,因为我们相信无法构建一个编译速度与 DFG 一样快同时生成与 FTL 一样好的代码的编译器。
总而言之,DFG 专注于快速编译,这源于其调优的历史以及它作为 FTL JIT 下一层的地位。

DFG 编译器的速度归结于其在 IR 中对块局部性(block-locality)的强调。DFG 层使用的 DFG IR 具有两级数据流图:
- 局部数据流图。局部数据流图用于基本块内部。这个图在 IR 中是一等公民,在处理 DFG 的 C++ 代码中的数据流时,有时似乎这是唯一的数据流图。基本块内部的 DFG IR 类似于 SSA 形式,因为指令和它们分配的变量之间存在 1:1 的映射,数据流通过让值的使用者指向产生这些值的指令(
节点 )来表示。这种表示不允许您在不同块中使用指令产生的值,除非通过繁琐的“逃逸口”。 - 全局数据流图。我们说
全局 是指整个编译单元,因此包括某个 JS 函数以及 DFG 内联到其中的内容。因此,全局 仅仅意味着跨越基本块。DFG IR 维护一个跨越基本块的辅助数据流图。DFG IR 处理全局数据流的方法基于溢出(spilling):为了将一个值传递给后续块,您将其存储到栈上的溢出槽位,然后该块加载它。但在 DFG IR 中,我们还通过这些加载和存储来连接数据流关系。这意味着,如果您愿意执行遍历这个辅助数据流图的繁琐任务,您就可以获得数据流的全局视图。
图 34 显示了这是如何工作的示例。编译单元表示为三个图:控制流图、局部数据流和全局数据流。数据流图用从使用者到被使用值的边表示。局部数据流图的工作方式与 SSA 相同,因此任何 SSA 优化都可以在此 IR 上以块局部方式运行。全局数据流图由 SetLocal/GetLocal 节点组成,这些节点将值存储/加载到栈中。SetLocal 和 GetLocal 之间的数据流在 DFG IR 中完全表示,通过在每个局部变量活跃的基本块中通过特殊的
从编写卓越的高吞吐量优化的角度来看,这种 IR 设计方法就像是给编译器“下套”。编译器在拥有实际 SSA 形式时蓬勃发展,在这种形式中只有一个数据流图,并且在遍历数据流时不必考虑指令在控制流中的位置。对局部性的强调完全是为了卓越的编译时间。我们相信局部性为我们带来了无法通过其他方式获得的编译时间改进:
- 基本块的指令选择和寄存器分配可以作为对该基本块的一次性遍历来实现。指令选择器可以在该次遍历中即兴做出寄存器分配决策,例如决定需要任意数量的临时寄存器来为某些 DFG 节点发出代码。组合的指令选择器和寄存器分配器(即 DFG 后端)独立地编译基本块。这种代码生成善于为大型基本块进行寄存器分配,但对小型基本块则不然。对于只有一个基本块的函数,DFG 通常生成与 FTL 一样好的代码。
- 我们永远不需要解压缩 OSR 退出时的增量编码。我们只需让后端记录其寄存器分配决策的日志(变量事件流)。虽然函数的 DFG IR 在编译后会被丢弃,但这个日志以及 DFG IR 的缩小版(只包含 MovHints 和它们引用的内容)会被保存,这样我们就可以在 OSR 退出发生时 重放后端所做的事情。这使得 DFG 中的 OSR 退出处理非常廉价——尽管我们疯狂地推测,但我们完全避免了 OSR 栈映射的 O(n2) 复杂性爆炸。
- 无需进入或退出 SSA。一方面,SSA 转换性能是一个已解决的问题:它是一个接近线性时间的操作。即便如此,常数因子高到足以完全避免它是有益的。退出 SSA 更糟。如果我们要将 SSA 与我们的块局部后端结合起来,我们必须添加某种转换来发现如何在基本块之间加载/存储活跃状态。DFG IR 玩弄了技巧,同一个存储操作既将数据流传递到另一个块,又兼作 OSR 退出状态更新。目前尚不清楚退出 SSA 是否会发现所有可以重复使用同一存储操作用于 OSR 退出状态更新和数据流边的情况。这表明任何退出 SSA 的版本都会使 DFG 编译器要么生成更差的代码,要么运行更慢。因此,没有 SSA 可以使编译器运行更快,因为进入 SSA 不是免费的,而退出 SSA 是糟糕的。
- 如果每个优化都是块局部的,那么它就会更快。当然,您可以在 SSA IR 中编写块局部优化。但是,拥有一种强调局部性的 IR 就像一种静态保证,可以避免我们不小心在 DFG 中引入昂贵的编译器阶段。
全局数据流对 DFG 任务至关重要的唯一情况是静态分析。这出现在预测传播器和抽象解释器中。它们都使用全局数据流图以及局部数据流图,以便它们能够看到类型信息如何在整个编译单元中流动。幸运的是,如图 34 所示,全局数据流图是可用的。它的格式使其难以编辑但相对容易分析。例如,它隐式报告了每个基本块边界处的活跃变量集合,这使得在抽象解释器中合并状态相对便宜。

图 35 显示了完整的 DFG 优化管道。这是一个相当完整的管道:它包含常量折叠、控制流简化、CSE 和 DCE 等经典优化。它还包含许多 JavaScript 特有的功能,例如决定在哪里放置检查(统一、预测注入和传播、预测传播和修复)、专门优化变长参数的通用模式的阶段、一些 GC 屏障的阶段,以及有助于 OSR 的阶段(CPS 重线程和幻影插入)。只要这些优化是块局部的并且不尝试过度努力,我们就可以在 DFG 中进行大量优化。尽管如此,这个管道比 FTL 的要小得多,并且运行速度快得多。
总而言之,DFG 编译器使用 OSR 退出和静态分析来发出最优的类型检查集。与在任何分析层中运行 JavaScript 相比,这大大减少了类型检查的数量。由于类型检查消除的好处非常大,DFG 编译器通过将自身限制在程序的块局部视图来限制其在其他优化上花费的时间。这是 DFG 为了获得快速编译时间而做出的权衡。那些运行时间足够长、宁愿支付编译时间来获得这些优化的函数,最终会升级到 FTL,FTL 则会全力以赴提高吞吐量。
FTL 编译器
我们之前已经在原始博客文章和引入 B3 时记录了 FTL 架构的一些方面。本节将更新此 JIT 的功能描述,并深入探讨 FTL 如何执行 OSR。我们将按如下方式构建对 FTL 的讨论。首先,我们将列举它能够执行哪些优化。然后,我们将详细描述它如何执行 OSR 退出。最后,我们将讨论补丁点——一种基于 lambda 的 IR 操作。
所有优化
FTL 编译器的目的就是运行所有优化。这是一个我们从不妥协于峰值吞吐量的编译器。所有 DFG 中为了编译时间而牺牲吞吐量的已知权衡都在 FTL 中被逆转。FTL 编译的函数运行的周期数没有上限,所以它是一种即使是深奥的优化最终也有机会获得回报的编译器。FTL 结合了多种优化策略:
- 我们重用 DFG 管道,包括其奇特的 IR。这确保了 DFG 层所做的任何好事在 FTL 中也可用。
- 我们添加了新的 DFG SSA IR 和 DFG SSA 管道。我们使许多 DFG 阶段适应 DFG SSA(这通常使它们变为全局而非局部)。我们添加了许多只能在 SSA 中实现的新阶段(例如循环不变代码外提)。
- 我们将 DFG SSA IR 降级为 B3 IR。B3 是一种基于 SSA 的优化 JIT 编译器,它在 C 语言的抽象层级上运行。B3 有许多优化,包括全局指令选择和图着色寄存器分配。FTL 是 B3 的第一个客户,因此 B3 专为 DFG SSA IR 无法优化到的抽象层级进行优化。
拥有多种查看程序的方式为 FTL 提供了最大的优化机会。编译器的一些功能,特别是决定在哪里放置检查的部分,在 DFG 的奇特 IR 中表现出色。编译器的其他部分在 DFG SSA 中工作得最好,例如 DFG 的循环不变代码外提。许多事情在 B3 中工作得最好,例如大多数关于如何简化算术的推理。B3 是第一个对 JavaScript 一无所知的 IR,因此它自然是实现那些可能难以处理 JavaScript 语义的教科书式优化的地方。一些优化,如 CSE,在每个 IR 中执行时表现最佳,因为它们在每个 IR 中都能找到独特的机会。事实上,所有 IR 除了其专门的优化外,都具有相同的基本优化能力:CSE、DCE、常量折叠、CFG 简化和强度降低(有时称为窥孔优化或指令组合)。

不妥协的方法可能通过查看图 36 中的 FTL 优化管道才能得到最好的理解。FTL 对代码运行了 93 个阶段。这包括图 35 中的所有阶段(DFG 管道),除了 Varargs Forwarding,仅仅因为它完全被 FTL 的 Arguments Elimination 所取代。让我们回顾一下 FTL 最重要的优化:
- DFG AI。这是 FTL 中最重要的优化之一。它与我们在 DFG 层中运行的 AI 基本相同。使其与 SSA 配合使用会使其稍微更精确,也稍微更昂贵。我们总共运行 AI 六次。
- CSE(公共子表达式消除)。我们在 DFG IR(局部公共子表达式消除)、DFG SSA IR(全局公共子表达式消除)、B3 IR(强度降低和专用的公共子表达式消除),甚至在 Air(修复明显溢出,一种专注于溢出代码的 CSE)中运行它。我们的 CSE 可以进行值编号和加载/存储消除。
- 对象分配下沉是一种“must-points-to”分析,我们用它来消除对象分配或将其下沉到慢路径。它可以消除对象分配图,包括循环图。
- 整数范围优化是一种前向流敏感抽象解释器,其状态是描述变量之间已知关系的一组方程和不等式。它可以消除整数溢出检查和数组边界检查。
- B3 的“降低强度”阶段运行一个不动点算法,其中包含 CFG 简化、常量折叠、重结合、SSA 清理、死代码消除、轻量级 CSE 以及大量杂项强度降低。
- 重复尾部,又称尾部复制,它会扁平化一些控制流菱形,取消小型循环的开关,并撤销某些 重新循环 的情况。我们盲目地在关键边被破坏的 CFG 上复制小型尾部。这使我们能够实现 拆分 为原始推测编译器所实现的部分功能。
- Lower B3 to Air 是一个全局模式匹配指令选择器。
- 图着色寄存器分配实现了 IRC 和 Briggs 寄存器分配器。我们在 x86 上使用 IRC,在 arm64 上使用 Briggs。区别在于,在寄存器压力较高的情况下,IRC 可以找到更多将赋值合并到单个寄存器中的机会。我们的寄存器分配器对 OSR 退出有特殊的优化,特别是我们为整数溢出检查发出的 OSR 退出。
FTL 中的 OSR 退出
既然我们已经列举了 FTL 能够执行的一些优化,现在让我们通过研究它是如何编译和执行 OSR 来深入了解 FTL 的工作原理。让我们从这个例子开始:
function foo(a, b, c)
{
return a + b + c;
}
字节码序列的相关部分是:
[ 7] add loc6, arg1, arg2
[ 12] add loc6, loc6, arg3
[ 17] ret loc6
这会产生以下 DFG IR:
24: GetLocal(Untyped:@1, arg1(B<Int32>/FlushedInt32), R:Stack(6), bc#7)
25: GetLocal(Untyped:@2, arg2(C<BoolInt32>/FlushedInt32), R:Stack(7), bc#7)
26: ArithAdd(Int32:@24, Int32:@25, CheckOverflow, Exits, bc#7)
27: MovHint(Untyped:@26, loc6, W:SideState, ClobbersExit, bc#7, ExitInvalid)
29: GetLocal(Untyped:@3, arg3(D<Int32>/FlushedInt32), R:Stack(8), bc#12)
30: ArithAdd(Int32:@26, Int32:@29, CheckOverflow, Exits, bc#12)
31: MovHint(Untyped:@30, loc6, W:SideState, ClobbersExit, bc#12, ExitInvalid)
33: Return(Untyped:@3, W:SideState, Exits, bc#17)
上面代码片段的 DFG 数据流如图 37 所示,OSR 退出站点如图 38 所示。


我们想将讨论重点放在 MovHint @27 以及它如何影响 ArithAdd @30 的代码生成。该 ArithAdd 将退出到字节码中的第二个 add,这需要恢复 loc6(即第一个 add 的结果),因为它在字节码的该点活跃(它也恰好被该 add 直接使用)。
这个 DFG IR 在 B3 中被降低为以下内容:
Int32 @42 = Trunc(@32, DFG:@26)
Int32 @43 = Trunc(@27, DFG:@26)
Int32 @44 = CheckAdd(@42:WarmAny, @43:WarmAny, generator = 0x1052c5cd0,
earlyClobbered = [], lateClobbered = [], usedRegisters = [],
ExitsSideways|Reads:Top, DFG:@26)
Int32 @45 = Trunc(@22, DFG:@30)
Int32 @46 = CheckAdd(@44:WarmAny, @45:WarmAny, @44:ColdAny, generator = 0x1052c5d70,
earlyClobbered = [], lateClobbered = [], usedRegisters = [],
ExitsSideways|Reads:Top, DFG:@30)
Int64 @47 = ZExt32(@46, DFG:@32)
Int64 @48 = Add(@47, $-281474976710656(@13), DFG:@32)
Void @49 = Return(@48, Terminal, DFG:@32)
CheckAdd 是 B3 的说法:执行整数加法,检查溢出,如果溢出,则执行由 generator 控制的 OSR 退出。generator 是一个 lambda,它被赋予一个 JIT 生成器对象(它可以用于在 OSR 退出跳转目的地发出代码)和一个 generator lambda。因此,CheckAdd 可以接受超过 2 个参数;前两个参数是实际的加法操作数,其余的是栈映射。由客户端决定传递多少个参数给栈映射,并且只有生成器才能看到它们的值。在这个例子中,只有第二个 CheckAdd (@46) 使用了栈映射。它传递了一个额外的参数 @44,它是第一个加法的结果——正如我们根据 MovHint @27 和 loc6 在 bc#12 活跃的事实所期望的那样。这是 FTL 将 MovHints 给出的增量编码解压缩成 B3 的完整栈映射的结果。

FTL OSR 退出意味着跟踪字节码局部变量值在多个降低阶段中发生的变化。各个阶段之间知之甚少。例如,最终的 IR,B3 和 Air,对字节码、字节码局部变量或任何 JavaScript 概念一无所知。我们通过跟踪每个退出站点的多个类似栈映射的映射来实现 OSR 退出,这些映射在组合在一起时提供了完整的视图(图 39):
- 我们通过解压缩 MovHint 增量获得的
DFG IR 栈映射 。这提供了从字节码局部变量 到DFG 节点或栈位置 的映射 。在某些情况下,DFG IR 必须将某些值存储到栈中,以支持通过function.arguments等方式进行的动态变量内省。DFG OSR 退出分析足够智能,能够识别这些情况,因为通过 OSR 退出从栈中提取值来处理这些情况更为优化。因此,OSR 退出分析可能会报告一个字节码局部变量可以通过 DFG 节点或栈位置获得。 - B3 在 CheckAdd 等 Check 指令的生成器 lambda 中提供的栈映射生成参数内部的
B3 值表示 数组。这是一个从B3 参数索引 到B3 值表示 的映射 ,该表示可以是寄存器、常量或栈位置。通过参数索引 ,我们指的是 Check 的栈映射参数中的索引。这是三条信息:一些用户值(例如 @46 = CheckAdd(@44, @45, @44))、其参数列表中的某个索引(例如 2)以及该索引引用的值(@44)。请注意,由于此 CheckAdd 有两个 @44 的参数索引,这意味着它们最终可能具有不同的值表示。例如,一个可能是常量,另一个可能是寄存器或溢出槽位并非不可能(尽管这极不可能;如果发生,那很可能是编译器中某种健全但不高效的反模式的结果)。B3 的客户端可以决定它将传递多少个栈映射参数,B3 保证它将为栈映射中的每个参数索引提供一个值表示(因此 CheckAdd 从参数索引 2 开始)。 - FTL OSR exit descriptor(FTL OSR 退出描述符)对象,FTL 的 DFG→B3 降级在每个退出点创建它,并将其保留在传递给 B3 检查的生成器 lambda 中。退出描述符基于 DFG IR 栈映射,并提供从字节码局部变量到B3 参数索引、常量、栈槽或实例化的映射。如果 DFG IR 栈映射表明某个字节码局部变量是一个具有常量值的节点,那么 OSR 退出描述符将直接告诉我们该值。如果 DFG 栈映射表明某个局部变量已在栈上,那么 OSR 退出描述符将直接告诉我们该栈槽。DFG 栈映射也可能告诉我们该节点是一个幻象对象分配——一个我们已优化掉但需要在 OSR 退出时重新实例化的对象分配。如果不是上述任何情况,OSR 退出描述符将告诉我们哪个 B3 参数索引包含该字节码局部变量的值。
- FTL 的 DFG→B3 降级已经维护了从DFG 节点到B3 值的映射。
- FTL OSR Exit(FTL OSR 退出)对象,这是一个从字节码局部变量到寄存器、常量、栈槽或实例化的映射。这是 FTL OSR 退出处理的最终产物,并从 B3 值表示和 FTL OSR 退出描述符中延迟计算。
这些部分如下协同工作。首先,我们计算 DFG IR 栈映射和 FTL 的 DFG 节点到 B3 值的映射。我们从 DFG OSR 退出分析中获取 DFG IR 栈映射,FTL 在降级过程中同时运行该分析。我们从降级中隐式获取 DFG 到 B3 的映射。然后我们用它来计算 FTL OSR 退出描述符以及要传递给栈映射的 B3 值集合。DFG IR 栈映射告诉我们哪些 DFG 节点是活跃的,因此我们使用 DFG 到 B3 的映射将其转换为 B3 值。某些节点将从 B3 栈映射中排除,例如对象实例化和常量。然后 FTL 在 B3 中创建 Check 值,将栈映射参数传递给它,并给它一个关闭在 OSR 退出描述符上的生成器 lambda。B3 的 Check 实现会找出每个栈映射参数索引要使用的值表示(这是 B3 寄存器分配器为每个数据流边执行此操作的结果),并以 B3 值表示数组的形式向生成器报告此信息。然后生成器创建一个引用 FTL OSR 退出描述符和值表示的 FTL::OSRExit 对象。FTL OSR 退出对象的用户可以通过询问 OSR 退出描述符,找出任何字节码局部变量应使用的寄存器、栈槽、常量值或实例化。它可以告知要使用的常量、溢出槽或实例化脚本。它还可以提供栈映射参数索引,在这种情况下,我们加载该索引处的值表示,然后它会告诉我们寄存器、溢出槽或常量。
这种 OSR 退出方法为我们带来了两个有用的特性。首先,它支持 OSR 特定的优化。其次,它支持不关心 OSR 的优化。让我们更详细地探讨这些。
FTL OSR 支持 OSR 特定的优化。这发生在 DFG IR 和 B3 IR 中。在 DFG IR 中,OSR 退出是 IR 的可变部分。任何操作都可以通过添加更多 OSR 退出进行优化,我们甚至能够移动检查。FTL 使用 DFG IR 进行复杂的 OSR 感知优化,例如对象分配下沉。在 B3 IR 中,OSR 退出获得特殊的寄存器分配处理。B3 将 Check 的栈映射参数理解为冷使用,这意味着如果这些使用被溢出,代价并不高。这对寄存器分配器来说是强大的信息。此外,B3 对带有溢出检查的加法和减法进行特殊的寄存器分配技巧(例如,我们可以精确识别结果寄存器何时可以重用栈映射寄存器,以及何时可以将结果寄存器与其中一个输入寄存器合并,以在 x86 上生成最优的两操作数形式)。
FTL OSR 也支持不关心 OSR 退出本身的优化。在 B3 IR 中,OSR 退出决策被固化到栈映射中。这是 OSR 退出最简单的表示形式,因为它不需要了解 OSR 退出语义即可正确处理。编译器阶段将指令的额外参数视为不透明是很自然的。由于多种因素的结合,显式栈映射在 B3 中尤其经济实惠:
- FTL 本身就是一种开销更大的编译器,因此 DFG OSR 增量编码优化变得不那么重要了,
- 我们只在 B3 中为 DFG 未优化掉的退出创建栈映射,并且
- B3 栈映射只包含活跃状态的子集(其余部分可能完全在 FTL OSR 退出描述符中描述)。
我们发现,由于显式 OSR 退出(如 MovHint 增量和退出源),在 DFG IR 中编写某些优化很烦人,有时甚至不切实际。在 B3 中不必担心这些问题。到目前为止,我们发现所有教科书上针对 SSA 的优化都可以在 B3 中实现。这意味着,我们只有在编写那些受益于 DFG 高级知识的阶段时,才会在编译器中遇到 OSR 退出相关的麻烦;否则,我们会在 B3 中编写这些阶段,并获得很好的体验。
这带来了一些令人惊讶的结果。每当 FTL 在 B3 中发出 Check 值时,B3 可能会复制该 Check。B3 IR 语义允许在优化期间复制任何代码,这通常是由于尾部复制造成的。不允许代码复制将比我们所能接受的程度更大地限制 B3。因此,当发生复制时,我们通过让多个 FTL OSR 退出共享相同的 OSR 退出描述符但获得单独的值表示来处理它。B3 也有可能证明某些 Check 要么是不必要的(总是成功),要么是永远无法到达的。在这种情况下,我们将有一个 FTL OSR 退出描述符,但没有 FTL OSR 退出。这种工作方式使得 DFG IR 永远不知道代码被复制了,而 B3 的尾部复制和不可达代码消除则对 OSR 退出一无所知。
补丁点:IR 中的 Lambda 表达式
这引出了关于 FTL 的最后一点。我们认为这个编译器最创新之处在于它在其 IR 中使用了 lambda 表达式。Check 就是其中一个例子。DFG 对 Check 在机器代码层面会做什么有一些了解,但这种了解是不完整的,直到我们填补了关于 B3 如何为 Check 的某些参数分配寄存器的一些空白。FTL 通过将 B3 Check 的一个操作数设为一个 lambda 表达式来处理此问题,该 lambda 表达式接受一个 JIT 代码生成器对象和所有参数的值表示。我们非常喜欢这种方法,以至于 B3 也支持 Patchpoint(补丁点)。Patchpoint 就像 C 编译器中的内联汇编片段,不同之处在于我们传递的不是包含汇编代码的字符串,而是一个 lambda 表达式,该表达式在被告知如何获取其参数并产生结果时将生成该汇编代码。FTL 将其用于多种情况:
- 每当 FTL 生成的 B3 IR 与 JavaScriptCore 的内部 ABI 交互时。这包括所有调用和类调用指令。
- 内联缓存。如果 FTL 想要发出内联缓存,它会使用 DFG 和基线编译器使用的相同内联缓存代码生成逻辑。我们没有教 B3 如何做,只是告诉 B3 这是一个补丁点。
- 惰性慢路径。FTL 具有仅当慢路径执行时才为其发出代码的能力。我们使用补丁点来实现这一点。
- 我们尚未添加到 B3 的指令。如果我们发现某些 JavaScript 特定的 CPU 指令,我们不必将其作为新的操作码贯穿 B3。我们可以直接使用 Patchpoint 发出它。(当然,将其贯穿 B3 会更好一些,但它不是严格必需的,这很好。)
以下是 FTL 使用补丁点发出快速双精度浮点数到整数转换的示例
if (MacroAssemblerARM64::
supportsDoubleToInt32ConversionUsingJavaScriptSemantics()) {
PatchpointValue* patchpoint = m_out.patchpoint(Int32);
patchpoint->appendSomeRegister(doubleValue);
patchpoint->setGenerator(
[=] (CCallHelpers& jit,
const StackmapGenerationParams& params) {
jit.convertDoubleToInt32UsingJavaScriptSemantics(
params[1].fpr(), params[0].gpr());
});
patchpoint->effects = Effects::none();
return patchpoint;
}
这告诉 B3,这是一个返回 Int32 并接受 Double 的补丁点。两者都假定进入 B3 选择的任何寄存器。然后生成器使用 C++ lambda 表达式通过我们的 JIT API 发出实际指令。最后,补丁点告诉 B3,该操作没有副作用(因此它可以被提升、消除等)。
关于 FTL 的讨论到此结束。FTL 是我们能想到的所有优化的、高吞吐量编译器。因为它是一个推测性编译器,其大部分设计都围绕着平衡处理 OSR 退出,这涉及不同程度了解 OSR 的 IR 之间的关注点分离。FTL 强大功能的一个关键是 B3 IR 中 lambda 表达式的使用,这允许 B3 客户端配置 B3 如何为某些操作发出机器代码。
编译和 OSR 概述
总而言之,JavaScriptCore 拥有两个优化编译器:DFG 和 FTL。它们基于相同的 IR (DFG IR),但 FTL 通过大量额外的编译器技术(SSA 和多个 IR)对其进行了扩展。DFG 是一种快速编译器:它的编译速度旨在比典型的优化编译器更快。但是,它生成的代码通常不是最优的。如果代码运行时间足够长,它也将通过 FTL 编译,FTL 试图发出最佳代码。
相关工作
利用廉价分析反馈进行推测的想法由 Hölzle、Chambers 和 Ungar 关于多态内联缓存的论文开创,他们将其称为自适应编译。这项工作采用了一种基于分割的推测策略,这意味着编译器会为每种可能的类型发出多份代码副本。这三位作者后来发明了 OSR 退出,尽管他们称之为动态去优化,并且仅将其用于增强调试。我们的推测编译方法意味着将 OSR 退出作为我们主要的推测策略。我们确实在非常有限的意义上使用了分割:在我们不够确定使用 OSR 的情况下,我们发出菱形推测,然后如果中间的代码路径足够小,我们允许尾部复制进行分割。
这种推测编译技术,即使用 OSR 或菱形推测但不过多分割,在 Java 性能大战期间首次获得了极大的关注。许多出色的 Java VM 使用解释器和 JIT 的组合,采用不同的优化策略来分析虚拟调用并推测性地去虚拟化它们,其中最好的实现使用了内联缓存、OSR 退出和监视点。使用此技术变体的 Java 实现包括(但不限于):
- IBM JIT,它结合了解释器和优化 JIT,并为去虚拟化进行了菱形推测。
- HotSpot 和 HotSpot server,它们结合了解释器和优化 JIT,并使用了菱形推测、OSR 退出以及 JavaScriptCore 使用的许多其他技术。JavaScriptCore 的 FTL JIT 与 HotSpot server 相似,因为这两个编译器都非常重视出色的 OSR 支持、全面的低级优化和图着色寄存器分配。
- Eclipse J9,HotSpot 的主要竞争对手,也使用推测编译。
- Jikes RVM,一个研究型虚拟机,它使用了 OSR 退出,但结合了基线 JIT 和优化 JIT。我关于这项技术的大部分知识都是在 Jikes RVM 工作时学到的。
与 Java 类似,JavaScript 已被证明是推测编译的一个很好的用例。JavaScript 性能大战的早期发起者包括 Squirrelfish 解释器(LLInt 的前身)、Squirrelfish Extreme JIT(我们现在称为基线 JIT)、结合了基线 JIT 和内联缓存的 早期 V8 引擎,以及 TraceMonkey。TraceMonkey 使用了一种名为跟踪的廉价优化 JIT 策略,它编译了许多推测路径。这个 JIT 有时优于基线 JIT,但由于过度推测,经常输给它们。V8 通过将推测编译方法引入 JavaScript 来提高赌注,使用了在 Java 中非常成功的模板:一个执行内联缓存的较低层,然后是一个基于内联缓存进行推测并退出到较低层的优化 JIT(称为 Crankshaft)。V8 的这个版本使用了一对 JIT(基线 JIT 和优化 JIT),非常类似于 Jikes RVM 为 Java 所做的那样。JavaScriptCore 很快效仿,将 DFG JIT 作为基线 JIT 的优化层,然后添加了 LLInt 和 FTL JIT。大约在同一时间,TraceMonkey 被 IonMonkey 取代,后者使用了与 Crankshaft 和 DFG 类似的技术。ChakraCore JavaScript 实现也使用了推测编译。JavaScriptCore 和 V8 继续通过创新的编译器技术扩展其优化,例如 B3(一个 CFG SSA 编译器)和 TurboFan(一个节点海洋 SSA 编译器)。与 Java 类似,顶级的实现至少有两层,较低的一层用于收集分析数据,较高的一层用于基于这些数据进行推测。而且,与 Java 类似,最快的实现都围绕 OSR 推测构建。
结论
JavaScriptCore 包含一些令人兴奋的推测性编译器技术。推测编译的核心是通过对程序在具有类型时可能拥有的类型进行押注,从而加速动态类型程序的执行。推测使用 OSR 退出,这是昂贵的,因此我们设计 JavaScriptCore,仅在确凿无疑的情况下才进行推测性押注。推测涉及使用多个执行层,一些用于分析,一些基于分析进行优化。JavaScriptCore 包含四个层,以实现每个函数的理想延迟/吞吐量权衡。一个控制系统根据代码是否足够“热”以及过去尝试优化它的次数来决定何时进行代码优化。所有层都使用通用的 IR(在 JavaScriptCore 的情况下是字节码)作为输入,并提供具有不同吞吐量/延迟和推测权衡的独立实现策略。
本文旨在揭示我们对推测编译的看法。我们希望它能为对 JavaScriptCore 感兴趣的人以及对构建自己的快速语言实现(尤其是那些具有非常奇怪和有趣功能)感兴趣的人提供有用的资源。