内联缓存删除功能的探索
如果您搜索任何 JavaScript 性能建议,一个非常流行的建议是避免使用 delete 操作符。如今,这似乎是一个好建议,但为什么删除属性的开销会比添加属性大得多呢?
今年冬天我在 Apple 实习的目标是提高 JavaScriptCore 中 delete 操作符的性能。这让我有机会了解 JavaScriptCore 内联缓存优化是如何工作的,今天我们将快速浏览一下这些优化。
首先,我们将了解在主要引擎中删除操作的实际开销,并讨论为什么我们可能希望对其进行优化。然后,我们将通过为属性删除实现内联缓存来了解其工作原理。最后,我们将查看这些优化对基准测试和微基准测试产生的性能差异。
删除操作的开销有多大?
首先,我们为什么要费心去优化删除操作呢?删除操作应该相当罕见,许多 JavaScript 开发者也已经知道尽可能不要使用它。与此同时,我们通常会尽量避免出现大的隐藏性能断崖。为了演示一个简单的 delete 语句如何对性能产生令人惊讶的影响,我编写了一个小程序,它逐步渲染一个场景,并测量渲染每一帧所需的时间。这个基准测试并非旨在精确测量性能,而是为了便于观察大的性能差异。
您可以通过按下下方“运行”按钮自行运行程序,它将计算图像中每个像素的新颜色值,然后显示渲染所需的时间(以毫秒为单位)。
接下来,我们可以尝试对代码的热点部分执行单个 delete 语句。您可以通过勾选上方的“使用 Delete”复选框,然后再次点击“运行”来完成。代码看起来像这样:
class Point {
constructor(x, y, z) {
this.x = x
this.y = y
this.z = z
this.a = 0
if (useDelete)
delete this.a
}
}
以下结果是在我的个人电脑(运行 Fedora 30)上测得的,比较了 WebKit(r259643)的最新版本,分别启用和禁用所有删除优化。我还使用了 Fedora 仓库中的 Firefox 74 和 Chromium 77。
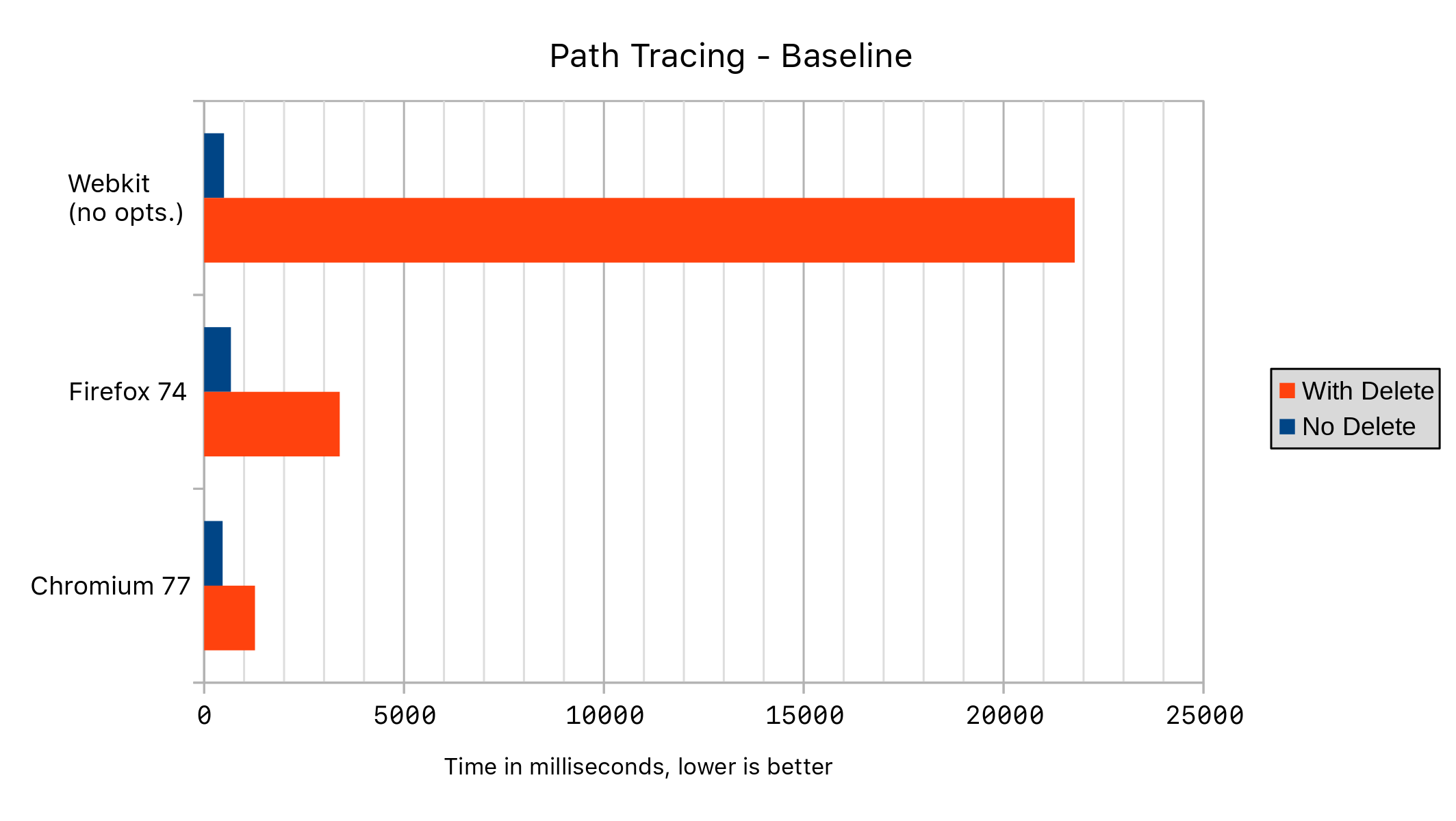
在这里,我们可以看到,在代码的热点部分添加一个 delete 语句会导致性能急剧下降!主要原因是 JavaScriptCore 以前对任何经过删除操作的对象都会禁用所有内联缓存优化,包括获取和设置对象属性时的优化。让我们看看原因。
结构和转换
JavaScript 代码可以极其动态,这使得优化变得棘手。虽然许多其他语言有固定大小的结构体或类来帮助编译器进行优化,但 JavaScript 中的对象表现得像字典,允许关联任意值和键。此外,对象的形状经常随时间变化。为了性能,JavaScriptCore 为对象使用多种内部表示,在运行时根据程序如何使用它们来选择。对象的默认表示使用一种称为“结构”(Structure)的东西来保存对象的通用形状,允许多个具有相同形状的实例共享一个结构。如果两个对象具有相同的结构 ID,我们可以快速判断它们具有相同的形状。
class A {
constructor() {
this.x = 5
this.y = 10
}
}
let a = new A() // Structure: { x, y }
let b = new A() // same as a
结构存储对象拥有的所有属性的名称、属性(例如只读)和偏移量,通常也包括对象的原型。结构存储形状,而对象维护其属性存储,偏移量则给出此存储中的位置。
从高层次来看,使用这种表示方法向对象添加属性的步骤如下:
1) 构造一个添加了该属性的新结构。
2) 将值放入属性存储。
3) 更改对象的结构 ID 以指向新结构。
一个重要的优化是将这些结构更改缓存在一种称为结构转换表(structure transition table)的东西中。这就是为什么在上面的例子中,两个对象共享相同的结构 ID,而不是拥有独立但等效的结构对象的原因。我们不必为 b 创建一个新结构,而只需转换到我们已经为 a 创建的结构。
这种表示方法在对象形状数量少且变化可预测的情况下能提高性能,但它并非总是最佳表示。例如,如果有很多属性不太可能与其他对象共享,那么为该对象的每个实例创建一个新结构会更快。由于我们知道该对象与其结构之间存在 1:1 的关系,因此在更改对象形状时,我们不再需要更新结构 ID。这也意味着我们无法再缓存大多数属性访问,因为这些优化依赖于检查结构 ID。
在 JavaScriptCore 的早期版本中,对于任何具有已删除属性的对象,都会选择这种表示。这就是为什么当在热门对象上执行删除操作时,我们会看到如此大的性能差异。
我在实习期间的第一个优化是改为缓存删除转换,从而允许这些对象继续被缓存。
class A {
constructor() {
this.x = 5
this.y = 10
delete this.y
}
}
let a = new A() // Structure: { x } from { x, y }
let b = new A() // same as a
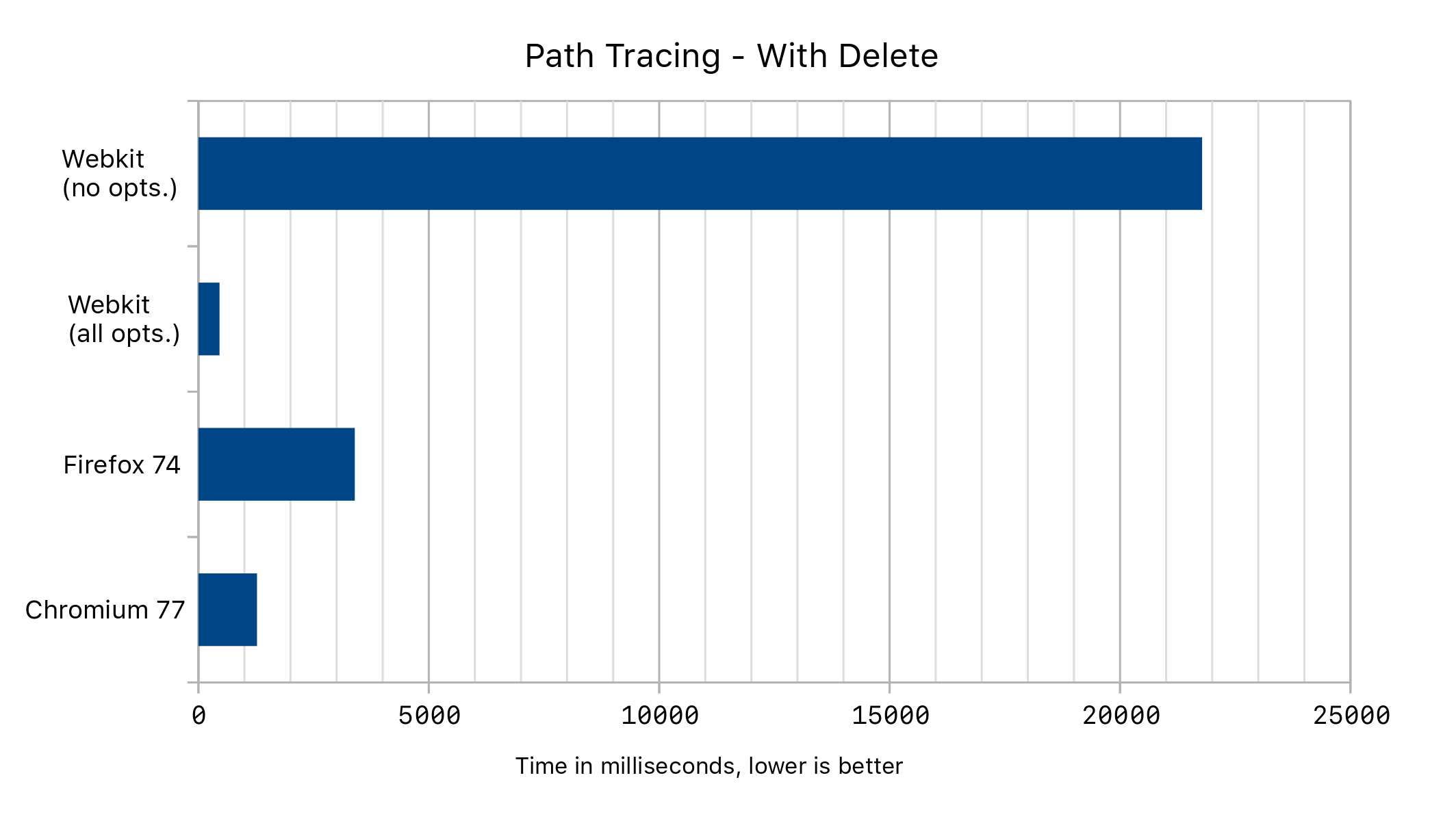
在这一改变之前,a 和 b 都拥有不同的结构。现在它们相同了。这不仅消除了我们的性能瓶颈,还将为删除语句本身带来进一步的优化。
在上面的路径追踪示例中,我们得到了以下性能结果:
内联缓存
现在我们可以缓存删除转换了,我们可以进一步优化属性删除行为本身。获取和设置属性都使用一种称为内联缓存的东西来完成,现在删除也一样。其工作方式是发出这些操作的通用版本,该版本会随着时间的推移自行修改,以更快地处理常见情况。
我为 delete 操作在我们的三个 JIT 编译器中实现了这种优化,并且我们的解释器也支持内联缓存。要了解 JavaScriptCore 如何使用多个编译器来权衡延迟和吞吐量,请参阅这篇博客文章。总结来说,代码首先由解释器执行。一旦它足够热,就会被我们的编译器编译成越来越优化的机器代码片段。
内联缓存使用结构来跟踪它所见过的对象形状。我们将看到内联缓存现在如何用于删除操作,这将使我们深入了解它如何也适用于获取和设置属性。
当我们看到一个删除属性语句时,我们首先会发出一个名为可修补跳转(patchable jump)的东西。这是一个以后可以更改的跳转指令。最初,它会简单地跳转到一些代码,调用属性删除的慢路径。然而,这个慢路径会存储这个调用的记录,在我们执行几次访问后,我们将尝试发出我们的第一个内联缓存。让我们通过一个例子来演示。
function test() {
for (let i = 0; i < 50; ++i) {
let o = { }
if (i < 10)
o.a = 1
else if (i < 20)
o.b = 1
else
o.c = 1
delete o.a
}
}
for (let i = 0; i < 100; ++i)
test()
首先,我们运行几次测试,使其提升到基线编译器。在 test() 内部,我们看到代码从具有三种不同结构的对象中删除属性,同时留出足够的时间让我们为每个对象发出新的内联缓存。让我们看看基线代码是什么样子的。
jmp [slow path] ; This jump is patchable
continuation:
[package up boolean result]
; falls through to rest of program
...
slow path:
[call into C++ slow path]
jmp [next bytecode]
此代码执行几次检查,然后跳转到慢路径调用或可修补跳转目标。慢路径调用放置在生成代码的主体之外,以提高缓存局部性。现在,我们看到可修补跳转目标也指向慢路径,但那将会改变。
在此时,删除操作是一个跳转到慢路径加上一个 C++ 调用,这相当昂贵。
每次调用慢路径时,它都会收集并保存有关其参数的信息。在这个例子中,它决定缓存的第一个情况是形状为 { c } 的结构的删除未命中。它生成以下代码,并重新修补可修补跳转目标,使其改为跳转到此处:
0x7f3fa96ff6e0: cmp [structure ID for { c }], (%rsi)
0x7f3fa96ff6e6: jnz [slow path]
0x7f3fa96ff6ec: mov $0x1, %eax ; return value true
0x7f3fa96ff6f1: jmp [continuation]
0x7f3fa96ff6f6: jmp [slow path]
我们看到,如果结构 ID 匹配,我们只需返回 true 并跳回到负责打包布尔结果并继续执行的续体。我们省去了昂贵的 C++ 调用,取而代之的只运行了几条指令。
接下来,随着引擎决定缓存下一个用例,我们看到生成了以下内联缓存:
0x7f3fa96ff740: mov (%rsi), %edx
0x7f3fa96ff742: cmp [structure ID for { c }], %edx
0x7f3fa96ff748: jnz [case 2]
0x7f3fa96ff74e: mov $0x1, %eax
0x7f3fa96ff753: jmp [continuation]
case 2:
0x7f3fa96ff758: cmp [structure ID for { a }], %edx
0x7f3fa96ff75e: jnz [slow path]
0x7f3fa96ff764: xor %rax, %rax; Zero out %rax
0x7f3fa96ff767: mov %rax, 0x10(%rsi); Store to the property storage
0x7f3fa96ff76b: mov [structure ID for { } from { a }], (%rsi)
0x7f3fa96ff771: mov $0x1, %eax
0x7f3fa96ff776: jmp [continuation]
在这里,我们看到了当属性存在时会发生什么。在这种情况下,我们将属性存储清零,更改结构 ID,并向续体返回 true (0x1),以便我们的结果被打包。
最后,我们看到了完整的内联缓存:
0x7f3fa96ff780: mov (%rsi), %edx
0x7f3fa96ff782: cmp [structure ID for { c }], %edx
0x7f3fa96ff788: jnz [case 2]
0x7f3fa96ff78e: mov $0x1, %eax
0x7f3fa96ff793: jmp [continuation]
case 2:
0x7f3fa96ff798: cmp [structure ID for { a }], %edx
0x7f3fa96ff79e: jnz [case 3]
0x7f3fa96ff7a4: xor %rax, %rax
0x7f3fa96ff7a7: mov %rax, 0x10(%rsi)
0x7f3fa96ff7ab: mov $0x37d4, (%rsi)
0x7f3fa96ff7b1: mov $0x1, %eax
0x7f3fa96ff7b6: jmp [continuation]
case 3:
0x7f3fa96ff7bb: cmp [structure ID for { b }], %edx
0x7f3fa96ff7c1: jnz [slow path]
0x7f3fa96ff7c7: mov $0x1, %eax
0x7f3fa96ff7cc: jmp [continuation]
当我们在不同的浏览器中运行上述代码时,在有无删除优化的情况下,我们得到了以下性能数据:
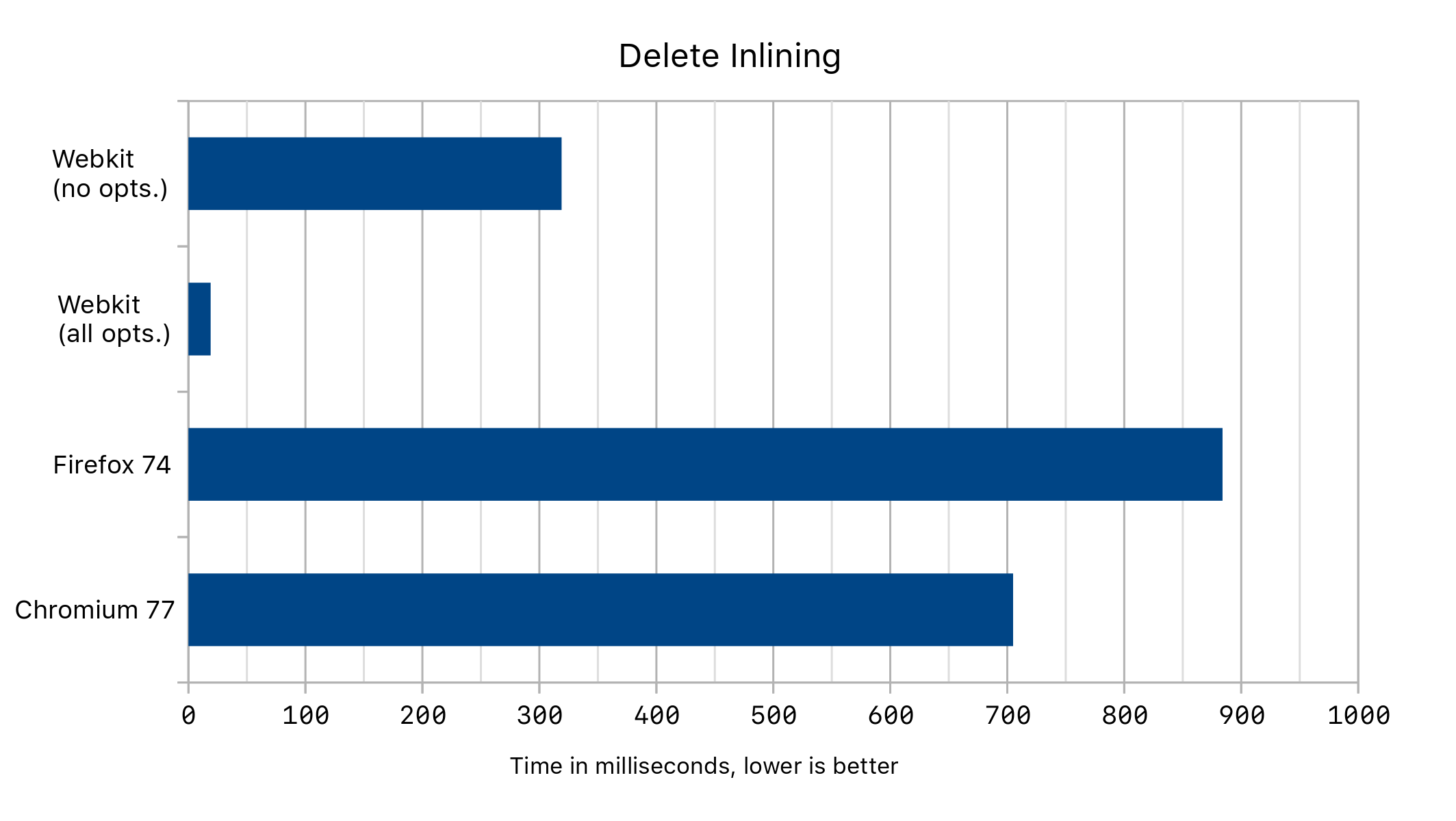
内联删除
现在我们已经了解了内联缓存是如何生成的,接下来我们希望了解如何将这些分析信息反馈给编译器。我们将看到我们的第一个优化编译器 DFG 如何像处理 puts 和 gets 一样尝试内联 delete 语句。这将允许我们所有的其他优化在 delete 语句内部进行查看,而不是将其视为一个黑箱。
我们将通过查看其中一个优化来演示这一点,即我们的对象分配下沉和消除阶段。此阶段试图在对象不脱离其作用域时阻止对象分配,但它以前将属性删除视为脱离。考虑以下代码:
function noEscape(i) {
let foo = { i }
delete foo.x
return foo.i
}
for (let i = 0; i < 1000000; ++i)
noEscape(5)
当 delete 运行时,它会首先获得一个内联缓存。随着代码继续分层,DFG 层最终将查看内联缓存所覆盖的案例,并且只看到一个结构。它将决定尝试内联 delete。
它首先推测目标对象的结构 ID 属于形状为 { i } 的结构。也就是说,我们检查对象的结构是否匹配,如果不匹配,则退出到较低层代码。这意味着我们的引擎可以假定任何后续代码的结构都匹配。如果这个假设最终被证明是错误的,我们最终将重新编译代码而不带这个假设。
D@25: NewObject()
D@30: CheckStructure(D@25, Structure for { })
D@31: PutByOffset(D@25, D@25, D@36, id0{i})
D@32: PutStructure(D@25, Structure for { i })
D@36: CheckStructure(D@25, Structure for { i })
D@37: JSConstant(True)
D@42: CheckStructure(D@25. Structure for { i })
D@43: GetByOffset(D@25, 0)
D@34: Return(D@43)
我们在这里看到,我们创建了一个新对象,然后看到了 put、delete 和 get 的内联版本。最后,我们返回。
如果 delete 语句被编译成一个 DeleteByID 节点,后续的优化将无法对这段代码进行太多优化。它们不了解 delete 对堆或程序的其余部分有什么影响。然而,我们看到一旦内联,delete 语句实际上变得非常简单:
D@36: CheckStructure(D@25, Structure for { i })
D@37: JSConstant(True)
也就是说,delete 语句变成了简单的检查和常量!接下来,虽然通常无法证明每个检查都是冗余的,但在本例中,我们的编译器将能够证明它可以安全地删除它们全部。最后,我们的对象分配消除阶段可以查看这段代码并删除对象分配。noEscape() 的最终代码如下所示:
D@36: GetStack(arg1)
D@25: PhantomNewObject()
D@34: Return(D@36)
PhantomNewObject 不会发出任何代码,使得我们最终的代码变得微不足道!我们得到了以下性能结果:
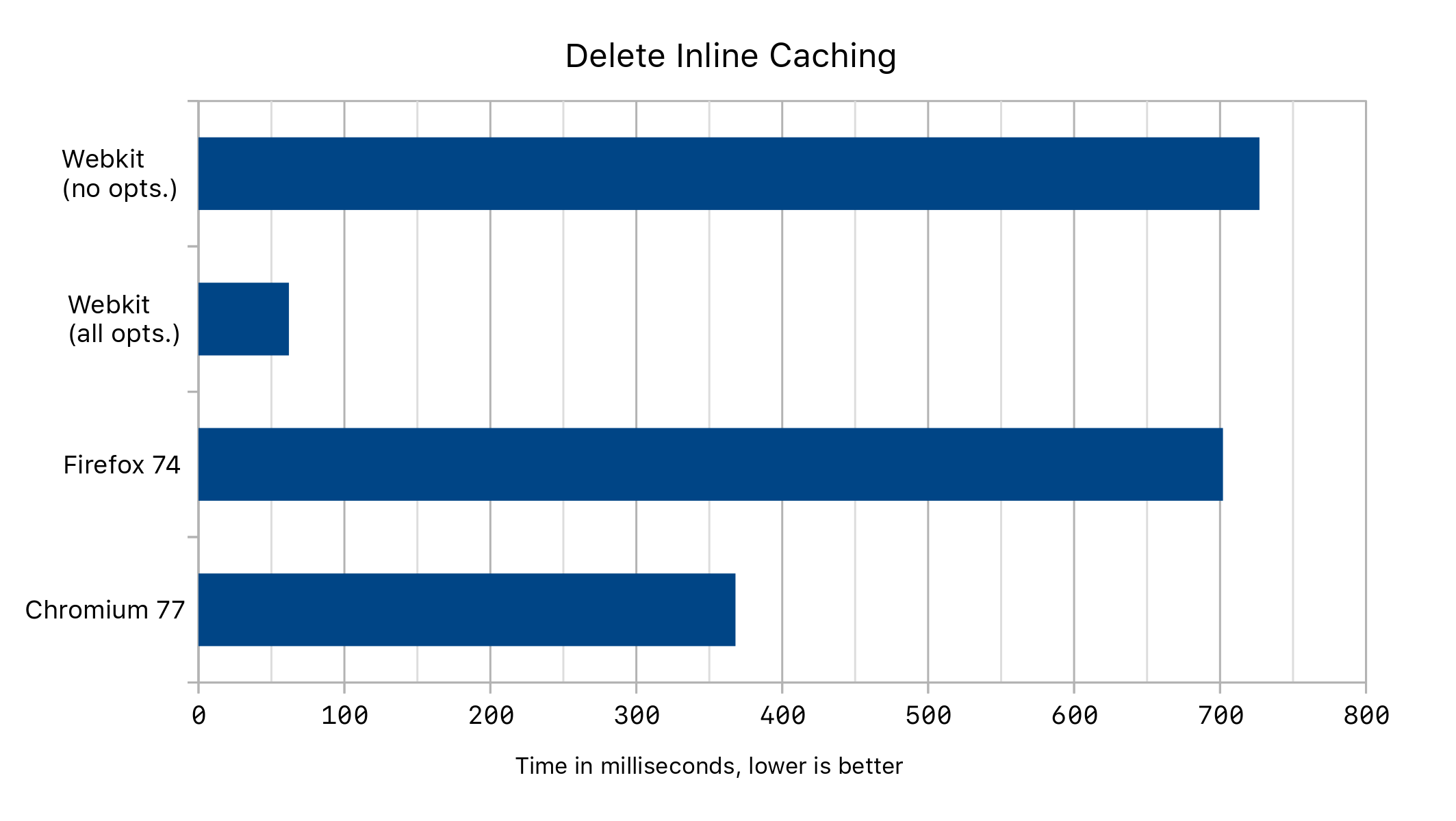
结果
删除转换的缓存使 Speedometer 基准测试的整体性能提高了 1%。主要原因是 EmberJS Debug 子测试频繁使用 delete 语句,而删除转换缓存使此基准测试的性能提高了 6%。此子测试被包含在基准测试中,因为发现许多网站没有发布 EmberJS 的发布版本。我们讨论的其他优化在跟踪的宏观基准测试中均未对性能产生影响。
总之,我们亲身了解了内联缓存的工作原理,甚至在此过程中推进了一些基准测试!我们学习这些优化的顺序(以及我本学期学习它们的顺序)与它们被发现的顺序密切相关。如果您想了解更多信息,请查阅这些关于 Smalltalk 和 Self 中内联缓存实现的论文,这两种语言启发了 JavaScript 的设计。我们可以看到从 Smalltalk 中的单态内联缓存到 Self 中支持内联的多态内联缓存的演变,就像我们今天在旅程中看到的一样。为删除操作实现内联缓存对我来说是一次非常有教育意义的经历,我希望您喜欢阅读这篇文章。
虽然删除操作仍然罕见,但让 JSC 更加健壮仍然感觉很棒。您可以通过提交错误报告或加入WebKit Slack 工作区与我们取得联系。您也可以考虑下载代码并亲自对其进行修改!